
CQRS
CQRS
CQRS(Command & Query Responsibility Segregation)命令查询职责分离,和 REST 同属于架构风格,如果单纯理解 CQRS,是比较容易的,另一种方式解释就是,一个方法要么是执行某种动作的命令,要么是返回数据的查询,命令的体现是对系统状态的修改,而查询则不会,职责的分离更加有利于领域模型的提炼,系统的灵活性和可扩展性也得到进一步加强。
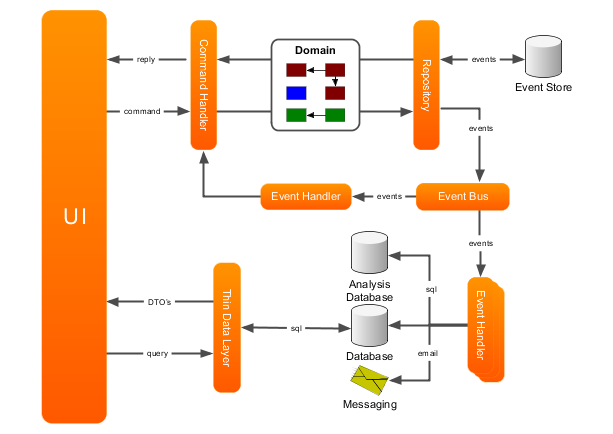
来自用户 UI 的请求分为 Query(查询)和 Command(命令),这些请求操作都会被 Service Interfaces(服务接口,只是一个统称)接收,然后再进行分发处理,对于命令操作会更新 Update Data store,因为读与写分离,为了保持数据的一致性,我们还需要把数据更新应用到 Read Data store。对于一般的应用系统来说,查询会占很大的比重,因为读与写分离了,所以我们可以针对查询进行进一步性能优化,而且还可以保持查询的灵活性和独立性,这种方式在应对大型业务系统来说是非常重要的,从这种层面上来说,CQRS 不用于 DDD 架构好像也是可以的,因为它是一种风格,并不局限于一种架构实现,所以你可以把它有价值的东西进行提炼,应用到合适的一个架构系统中也是可以的。
- Command Bus(命令总线):图中没有,应该放在 Command Handler 之前,可以看作是 Command 发布者。
- Command Handler(命令处理器):处理来自 Command Bus 分发的请求,可以看作是 Command 订阅者、处理者。
- Event Bus(事件总线):一般在 Command Handler 完成之后,可以看作是 Event 发布者。
- Event Handler(事件处理器):处理来自 Event Bus 分发的请求,可以看作是 Event 订阅者、处理者。
- Event Store(事件存储):对应概念 Event Sourcing(事件溯源),可以用于事件回放处理,还原指定对象状态。
首先抽离两个重要概念:Command(命令)和 Event(事件),Command 是一种命令的语气(本身就是命令的意思,呵呵),它的效果就是对某种对象状态的修改,Command Bus 收集来自 UI 的 Command 命令,并根据具体命令分发给具体的 Command Handler 进行处理,这时候就会产生一些领域操作,并对相应的领域对象进行修改,Command Handler 只是修改操作,并不会涉及到修改之后的操作(比如保存、事件发布等),Command Handler 完成之后并不表示这个 Command 命令就此结束,它需要把接下来的操作交给 Event Bus(完成之后的操作),并分发给相应的 Event Handler 订阅者进行处理,一般是数据保存、事件存储等。
VO(View Object):视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
DTO(Data Transfer Object):数据传输对象,这个概念来源于 J2EE 的设计模式,原来的目的是为了 EJB 的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负载,但在这里,我泛指用于展示层与服务层之间的数据传输对象。
DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体。
PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那么,数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属性。
梳理 Command 整个流程,你会发现一个关键词:状态(Status),在上一篇博文讲 REST 概念时,也有一个相似的概念:应用状态(Application State),REST 其中的一个含义就是状态转换,从客气端的发起请求开始,到服务端响应请求结束,应用状态在其过程中会进行不断的转换,请求响应的整个过程也就是应用状态转换的过程,对于 Command 处理流程来说,领域对象的状态和应用状态其实是相类似。我举一个例子,在 REST 架构风格中,应用状态是不会保存到服务端的,客户端发起请求(包含应用状态信息),服务端做出相应处理,此时的状态会转换成资源状态呈现给客户端,这就是表现层状态转换的意思,回到 Command 处理流程上,Command Bus 接收来自 UI 的请求,分发给相应的 Command Handler 进行处理,在处理过程中,就会对领域对象进行修改操作,但它不会保存修改之后的状态信息,而是交给 Event Handler 进行保存状态信息。
和 Command 相比,Query 的处理流程就简单很多了,Query Service 接收来自 UI 的查询请求,这个查询处理可以用各种方式实现,你可以使用 ORM,也可以直接写 SQL 代码
CQRS(Command Query Separation,命令查询分离)最早来自于 Betrand Meyer(Eiffel 语言之父,OCP 提出者)提出的概念。其基本思想在于任何一个对象的方法可以分为两大类:
- 命令(Command):不返回任何结果(void),但会改变对象的状态。
- 查询(Query):返回结果,但是不会改变对象的状态,对系统没有副作用。
CQRS 使用分离的接口将数据查询操作(Queries)和数据修改操作(Commands)分离开来,这也意味着在查询和更新过程中使用的数据模型也是不一样的。这样读和写逻辑就隔离开来了,分离了读写职责之后,可以对数据进行读写分离操作来改进性能,可扩展性和安全性。
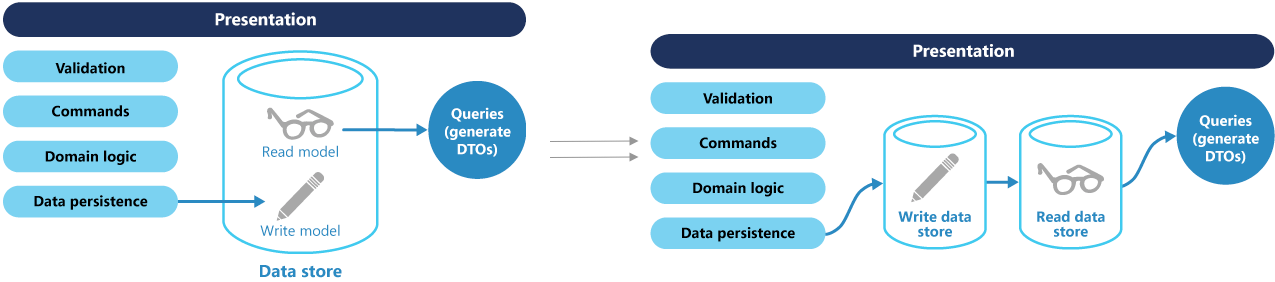
设计理念
读写分离
主数据库处理 CUD,从库处理 R,从库的的结构可以和主库的结构完全一样,也可以不一样,从库主要用来进行只读的查询操作。在数量上从库的个数也可以根据查询的规模进行扩展,在业务逻辑上,也可以根据专题从主库中划分出不同的从库。从库也可以实现成 ReportingDatabase,根据查询的业务需求,从主库中抽取一些必要的数据生成一系列查询报表来存储。
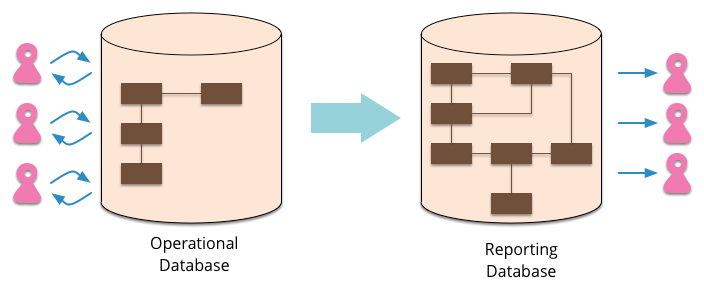
在 CQRS 中,所有的涉及到对 DB 的操作都是通过发送 Command,然后特定的 Command 触发对应事件来完成操作,这个过程是异步的,并且所有涉及到对系统的变更行为都包含在具体的事件中,结合 Eventing Source 模式,可以记录下所有的事件,而不是以往的某一点的数据信息,这些信息可以作为系统的操作日志,可以来对系统进行回退或者重放。
事务脚本与 DDD
CQRS 就是对事务脚本和领域模型两种模式的综合,因为对于 Query 和报表的场景,使用领域模型往往会把简单的事情弄复杂,此时完全可以用奥卡姆剃刀把领域层剃掉,直接访问 Infrastructure。
CQRS 还可以与 DDD 相结合:
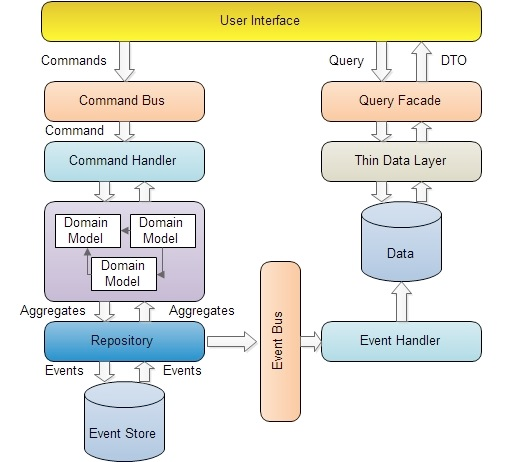
优势与对比
-
分工明确,可以负责不同的部分
-
将业务上的命令和查询的职责分离能够提高系统的性能、可扩展性和安全性。并且在系统的演化中能够保持高度的灵活性,能够防止出现 CRUD 模式中,对查询或者修改中的某一方进行改动,导致另一方出现问题的情况。
-
逻辑清晰,能够看到系统中的那些行为或者操作导致了系统的状态变化。
-
可以从数据驱动(Data-Driven) 转到任务驱动(Task-Driven)以及事件驱动(Event-Driven)。
数据一致性
传统架构,数据一般是强一致性的,通常会使用数据库事务保证一次操作的所有数据修改都在一个数据库事务里,从而保证了数据的强一致性。在分布式的场景,同样希望数据的强一致性,就是使用分布式事务。但是众所周知,分布式事务的难度、成本是非常高的,而且采用分布式事务的系统的吞吐量都会比较低,系统的可用性也会比较低。所以,很多时候,也会放弃数据的强一致性,而采用最终一致性;从 CAP 定理的角度来说,就是放弃一致性,选择可用性。
CQRS 架构,则完全秉持最终一致性的理念。这种架构基于一个很重要的假设,就是用户看到的数据总是旧的。对于一个多用户操作的系统,这种现象很普遍。比如秒杀的场景,当你下单前,也许界面上你看到的商品数量是有的,但是当你下单的时候,系统提示商品卖完了。在界面上看到的数据是从数据库取出来的,一旦显示到界面上,就不会变了。但是很可能其他人已经修改了数据库中的数据。这种现象在大部分系统中,尤其是高并发的 WEB 系统,尤其常见。
所以,基于这样的假设,即便系统做到了数据的强一致性,用户还是很可能会看到旧的数据。所以,这就给设计架构提供了一个新的思路。能否这样做:只需要确保系统的一切添加、删除、修改操作所基于的数据是最新的,而查询的数据不必是最新的。这样就很自然的引出了 CQRS 架构了。C 端数据保持最新、做到数据强一致;Q 端数据不必最新,通过 C 端的事件异步更新即可。所以,基于这个思路开始思考,如何具体的去实现 CQ 两端。
扩展性
传统架构,各个组件之间是强依赖,都是对象之间直接方法调用;CQRS 架构,则是事件驱动的思想;从微观的聚合根层面,传统架构是应用层通过过程式的代码协调多个聚合根一次性以事务的方式完成整个业务操作,而 CQRS 架构,则是通过事件驱动的方式,最终实现多个聚合根的交互,CQ 两端也是通过事件的方式异步进行数据同步,也是事件驱动的一种体现。
架构层面,传统架构是 SOA 的思想,CQRS 是 EDA 的思想。SOA 是一个服务调用另一个服务完成服务之间的交互,服务之间紧耦合;EDA 是一个组件订阅另一个组件的事件消息,根据事件信息更新组件自己的状态,所以 EDA 架构,每个组件都不会依赖其他的组件;组件之间仅仅通过 topic 产生关联,耦合性非常低。例如原来 A 服务调用了 B,C 两个服务,后来想多调用一个服务 D,SOA 则需要改 A 服务的逻辑;而 EDA 架构,不需要动现有的代码,原来有 B,C 两订阅者订阅 A 产生的消息,现在只需要增加一个新的消息订阅者 D 即可。
可用性
统架构和 CQRS 架构,都可以做到高可用,只要做到让系统中每个节点都无单点即可。但是,相比之下 CQRS 架构可以有更多的回避余地和选择空间。传统架构,可用性要把读写合在一起综合考虑。CQRS 架构把读和写分离了,可用性相当于被隔离在了两个部分去考虑。
C 端可用性更加容易的,因为 C 端是消息驱动的。做任何数据修改时,都会发送 Command 到分布式消息队列,然后后端消费者处理 Command->产生领域事件->持久化事件->发布事件到分布式消息队列->最后事件被 Q 端消费。这个链路是消息驱动的。相比传统架构的直接服务方法调用,可用性要高很多。因为就算处理 Command 的后端消费者暂时挂了,也不会影响前端 Controller 发送 Command,Controller 依然可用。
Q 端和传统架构没什么区别,因为都是要处理高并发的查询。以前怎么优化的,现在还是怎么优化。
使用场景
-
当在业务逻辑层有很多操作需要相同的实体或者对象进行操作的时候。CQRS 使得我们可以对读和写定义不同的实体和方法,从而可以减少或者避免对某一方面的更改造成冲突
-
对于一些基于任务的用户交互系统,通常这类系统会引导用户通过一系列复杂的步骤和操作,通常会需要一些复杂的领域模型,并且整个团队已经熟悉领域驱动设计技术。写模型有很多和业务逻辑相关的命令操作的堆,输入验证,业务逻辑验证来保证数据的一致性。读模型没有业务逻辑以及验证堆,仅仅是返回 DTO 对象为视图模型提供数据。读模型最终和写模型相一致。
-
适用于一些需要对查询性能和写入性能分开进行优化的系统,尤其是读/写比非常高的系统,横向扩展是必须的。比如,在很多系统中读操作的请求时远大于写操作。为适应这种场景,可以考虑将写模型抽离出来单独扩展,而将写模型运行在一个或者少数几个实例上。少量的写模型实例能够减少合并冲突发生的情况
-
适用于一些团队中,一些有经验的开发者可以关注复杂的领域模型,这些用到写操作,而另一些经验较少的开发者可以关注用户界面上的读模型。
-
对于系统在将来会随着时间不段演化,有可能会包含不同版本的模型,或者业务规则经常变化的系统
-
需要和其他系统整合,特别是需要和事件溯源 Event Sourcing 进行整合的系统,这样子系统的临时异常不会影响整个系统的其他部分。