
21-用事件风暴分解单体设计微服务 - capital
用事件风暴分解单体设计微服务 - capital
作为软件工程师和架构师,我们经常面临为遗留系统创建目标微服务架构的挑战。这些系统通常是已经存在多年的大型单体应用程序,通常具有很多依赖性,并且通常在您的公司中没有一个人了解这一切。在这些情况下,一群领域专家是理解围绕业务上下文和所需功能的“原因”的关键,上下文对于创建成功的架构至关重要。
通常,您首先创建一个业务能力模型或分类法来绘制业务能力并将它们在特定级别分组下对齐。模型/分类法表示应用程序所需的一组功能集合。虽然这是有帮助的,但它有一些差距。分类法本身并没有提供更广泛的用例上下文,也没有提供有关如何将功能分解为微服务的洞察力。这就是事件风暴可以提供帮助的地方。事件风暴由 Alberto Brandolini 创建,事件风暴是一种交互式方式进行领域驱动设计(DDD),它将业务和技术部门的领域专家聚集在一起。在本文中,我将提供事件风暴的深入迭代示例、使用它的一些经验教训,以及如何将其应用于您的架构工作。
首先想澄清一些关于事件风暴的常见误解:
-
误解 #1 — 与 DDD 相同:虽然事件风暴基于许多 DDD 概念——包括有界上下文和聚合——但正式的 DDD 往往很复杂,需要大量的培训。事件风暴侧重于让所有领域专家参与的交互式协作白板练习。它更简单,不需要像正式 DDD 那样进行大量培训。
-
误解#2——它与设计思维相同:事件风暴和设计思维都利用了交互式业务流程映射练习和白板。它们的不同之处在于,事件风暴侧重于定义微服务架构的分解和分类。它还关注业务流程中当前正在发生的事情,称为事件。设计思维涉及一个分阶段的过程,包括问题定义、需求发现和基准测试、构思、原型设计和测试。它还更多地关注同理心和痛点。
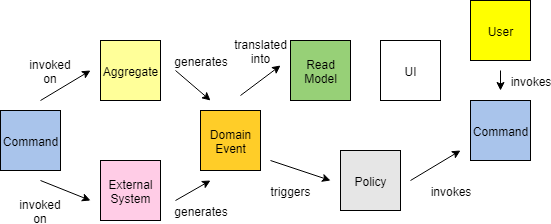
现在让我们深入了解事件风暴的细节。首先要了解的事情之一是捕获的有关域的不同类型的详细信息。这些不同类型的细节通常由不同颜色的便签表示。让我们详细介绍其中的每一个。
- 事件(橙色):这些是事件风暴中最重要和最广泛使用的组件,代表领域事件和与领域专家相关的任何事情。它们是用过去时写成的,并提供了用于后面分类步骤的基本细节。
- 命令(蓝色):这些是做某事的请求。它们可以源自用户或系统,也可以源自其他事件。
- 系统(粉红色):这些代表域中涉及的系统。它们可以发出命令或接收命令以及触发事件。
- 用户(黄色):这些是参与流程的人类用户。他们可能是一个人,也可能是一个部门/团队。黄色便签有助于显示业务流程的工作流程有多复杂,具体取决于所涉及的部门数量和来回的数量。
- 聚合(棕褐色):这是第一级分类,可以被认为是一组事件操作的“事物”。通常,它们是一个名词,可以在一组相互依赖的事件中识别出来。
- 读取模型(绿色):这表示可能对用户或系统做出决策至关重要的数据。我没有看到经常使用这个,但是当需要强调用户看到的数据时它会很有帮助。
- Policy 政策(灰色):这些代表可能需要执行的标准或规则,例如合规性政策的规则。
现在我们了解了我们想要在域中发现的不同类型的事物,让我们通过一个示例来介绍事件风暴的每个迭代步骤。对于我们的示例,我们将对通用电子商务站点的域进行建模。
步骤 #1 — 事件发现
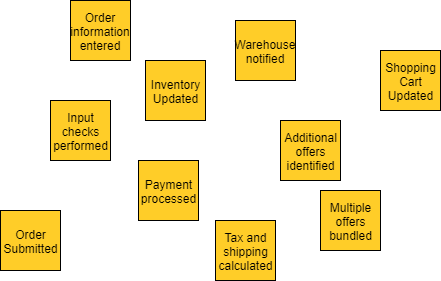
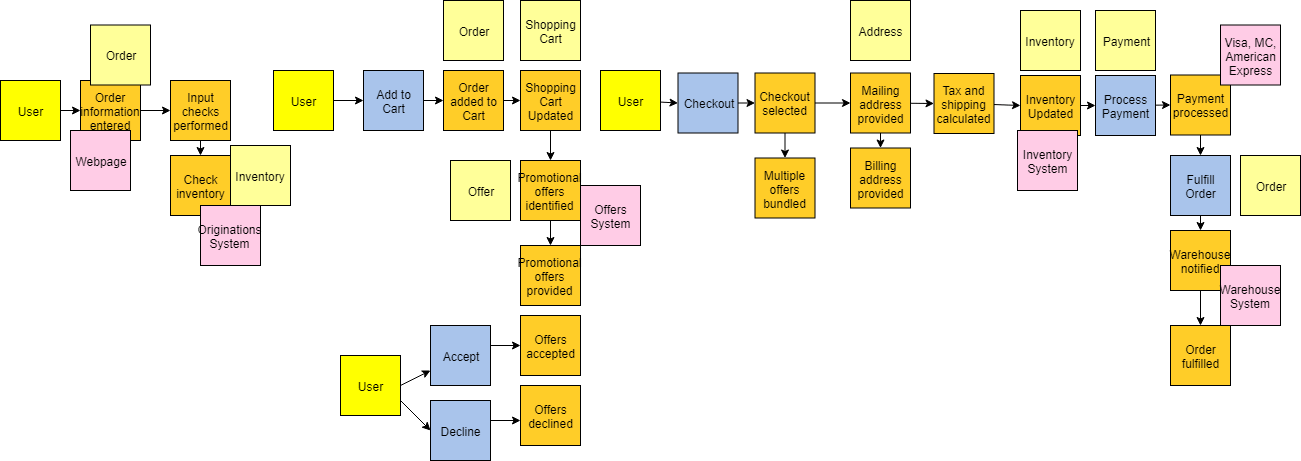
事件风暴的第一阶段是事件发现阶段。基本上,房间里的每个人都在写事件并将它们贴在墙上。将此阶段视为集思广益,因此请避免在此阶段应用任何分析或过滤,因为它只会减慢速度。别担心,该过程中的后续步骤会清理干净。此步骤通常需要最长的时间,并且留出足够的时间来捕获事件的基础非常重要。以电子商务网站为例,一些可能的事件可能是订单提交、付款处理或库存更新等。此阶段的输出示例如下所示:
步骤 #2 — 按顺序放置事件
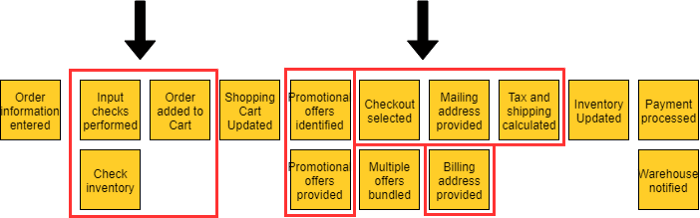
接下来的一系列步骤通过按顺序(通常从左到右)放置事件来帮助识别任何丢失的事件。建立顺序后,您可以倒退以帮助识别其他事件。在我们的电子商务示例中,首先输入订单信息,然后检查库存。在将它们按顺序排列时,我们发现我们为正在执行的输入检查遗漏了一个事件。提示 - 当多个事件同时发生时,您可以将它们垂直堆叠,如下所示:
第 3 步 — 对更广泛的生态系统进行建模
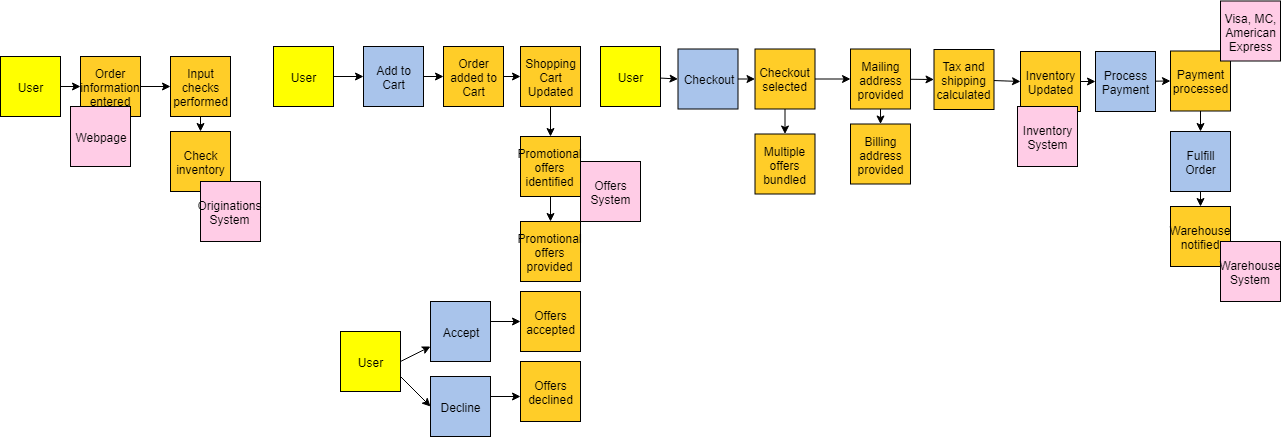
把事件序列后,下一步就是模拟出更广泛的生态系统通过提问,如,围绕事件“触发什么事件?它是一个系统吗?一个用户?另一个事件?涉及哪些命令?” 这个额外的上下文对于理解域的当前状态非常有价值。在我们的示例中,用户触发订单信息输入事件,他们通过网页(系统)进行操作。
步骤 #4 — 简单的事件分类
此时,所有详细事件及其相关部分都应建模,并在您准备进入分类时。第一种分类称为聚合。这些是名词或事物,事件发生作用。DDD 也有一个实体的概念,您可以将其视为聚合的下一个级别。根据我的经验,将聚合和实体视为相同有助于简化事情,使人们更容易理解。在我们的示例中,库存、订单、报价都是聚合的示例。它们是事件运行的对象。
步骤 #5 — 事件的有界上下文分类
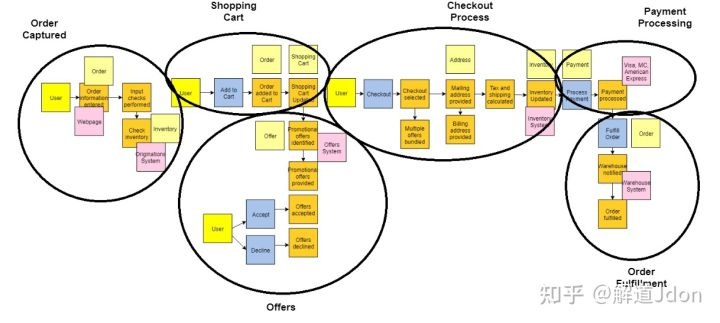
现在我们已准备好进行分类的有界上下文级别。所有相关事件都将落入一个单一的有界上下文中。例如,所有与购物车相关的事件都属于购物车有界上下文。这里要记住的一个重要的微服务概念是,如果它一起变化,它应该一起变化。我们希望尽可能消除有界上下文之间的依赖关系。如果语言在事件之间发生变化,则表明您已进入不同的有界上下文。
例如,从查看促销优惠到结帐时,语言正在发生变化。这最好在白板上完成,您可以简单地围绕相关事件绘制轮廓并适当标记有界上下文。
步骤 #6 — 将它们放在一起
现在我们已经完成了事件风暴的步骤!您现在可以使用有界上下文和聚合来了解所需的微服务。通常,有界上下文中的聚合代表一个或多个微服务。在我们的示例中,订单捕获有界上下文将具有与订单和库存相关的微服务。您会注意到 Order 也存在于 Shopping Cart bounded context 和 Order Fulfillment bounded context 中。这没关系,因为这表明它们是不同的微服务,因为它们处于不同的有界上下文中。他们可能都在做与订单相关的事情,但他们做的事情是不同的。在单体应用程序中,这些将被捆绑在一起创建耦合,但在微服务架构中,我们将它们分开以实现独立性。

附加步骤 #7:创建能力
现在您拥有大量信息来帮助您启动目标架构。根据我的经验,我发现添加一个从事件创建功能的步骤很有帮助。通常,能力是现在时形式的事件。然后可以将能力映射到各种目标能力架构视图中的有界上下文和聚合。这些不同的视图为建筑师和工程师提供了一个经过深思熟虑的蓝图来构建他们的目标状态。
