
深浅模块
深层模块与浅层模块
深层模块(Deep Modules)
最好的模块是那些提供强大功能但具有简单接口的模块。我用“深入”一词来描述这样的模块。为了形象化深度的概念,假设每个模块都由一个矩形表示。每个矩形的面积与模块实现的功能成比例。矩形的顶部边缘代表模块的接口;边缘的长度表示接口的复杂性。最好的模块很深:它们在简单的接口后隐藏了许多功能。深度模块是一个很好的抽象,因为其内部复杂性的很小一部分对其用户可见。
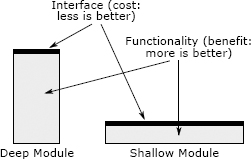
深浅模块。最好的模块很深:它们允许通过简单的接口访问许多功能。浅层模块是具有相对复杂的接口的模块,但功能不多:它不会掩盖太多的复杂性。模块深度是考虑成本与收益的一种方式。模块提供的好处是其功能。模块的成本(就系统复杂性而言)是其接口。模块的接口代表了模块强加给系统其余部分的复杂性:接口越小越简单,引入的复杂性就越小。最好的模块是那些收益最大,成本最低的模块。接口不错,但更多或更大的接口不一定更好!
Unix 操作系统及其后代(例如 Linux)提供的文件 I/O 机制是深层接口的一个很好的例子。I/O 只有五个基本系统调用,带有简单签名:
int open(const char* path, int flags, mode_t permissions);
ssize_t read(int fd, void* buffer, size_t count);
ssize_t write(int fd, const void* buffer, size_t count);
off_t lseek(int fd, off_t offset, int referencePosition);
int close(int fd);
开放系统调用采用分层文件名,例如 /a/b/c,并返回一个整数文件描述符,该描述符用于引用打开文件。open 的其他自变量提供可选信息,例如是否正在打开文件以进行读取或写入,如果不存在现有文件则是否应创建新文件,以及如果创建新文件则具有文件的访问权限。读写系统调用在应用程序内存和文件的缓冲区之间传输信息。close 结束对文件的访问。大多数文件是按顺序访问的,因此这是默认设置。但是,可以通过调用 lseek 系统调用来更改当前访问位置来实现随机访问。
Unix I/O 接口的现代实现需要成千上万行代码,这些代码可以解决诸如以下的复杂问题:
- 如何在磁盘上表示文件以便有效访问?
- 如何存储目录,以及如何处理分层路径名以查找它们所引用的文件?
- 如何强制执行权限,以使一个用户无法修改或删除另一用户的文件?
- 如何实现文件访问?例如,如何在中断处理程序和后台代码之间划分功能,以及这两个元素如何安全通信?
- 在同时访问多个文件时使用什么调度策略?
- 如何将最近访问的文件数据缓存在内存中以减少磁盘访问次数?
- 如何将各种不同的辅助存储设备(例如磁盘和闪存驱动器)合并到单个文件系统中?
所有这些问题,以及更多的问题,都由 Unix 文件系统实现来解决。对于调用系统调用的程序员来说,它们是不可见的。多年来,Unix I/O 接口的实现已经发生了根本的发展,但是五个基本内核调用并没有改变。深度模块的另一个示例是诸如 Go 或 Java 之类的语言中的垃圾收集器。这个模块根本没有接口。它在后台进行隐形操作以回收未使用的内存。由于将垃圾收集消除了用于释放对象的接口,因此向系统中添加垃圾回收实际上会缩小其总体接口。垃圾收集器的实现非常复杂,但是使用该语言的程序员无法发现这种复杂性。
诸如 Unix I/O 和垃圾收集器之类的深层模块提供了强大的抽象,因为它们易于使用,但隐藏了巨大的实现复杂性。
浅层模块
浅层模块是其接口与其提供的功能相比相对复杂的模块。例如,实现链表的类很浅。操作链表不需要太多代码(插入或删除元素仅需几行),因此链表抽象不会隐藏很多细节。链表接口的复杂度几乎与其实现的复杂度一样高。浅类有时是不可避免的,但是它们在管理复杂性方面没有提供太多帮助。这是一个浅层方法的极端示例,该浅层方法来自软件设计类的项目:
private void addNullValueForAttribute(String attribute) {
data.put(attribute, null);
}
从管理复杂性的角度来看,此方法会使情况变得更糟,而不是更好。该方法不提供任何抽象,因为其所有功能都可以通过其接口看到。例如,调用者可能需要知道该属性将存储在 data 变量中。考虑接口并不比考虑完整实现简单。如果正确记录了该方法,则文档将比该方法的代码长。与调用方直接操作数据变量相比,调用该方法所花费的击键甚至更多。该方法增加了复杂性(以供开发人员学习的新接口的形式),但没有提供任何补偿。
浅层模块是一个接口相对于其提供的功能而言复杂的模块。浅层模块在对抗复杂性方面无济于事,因为它们提供的好处(不必了解它们在内部如何工作)被学习和使用其接口的成本所抵消。小模块往往很浅。
信息隐藏与暴露
信息隐藏和深层模块密切相关。如果模块隐藏了很多信息,则往往会增加模块提供的功能,同时还会减少其接口。这使模块更深。相反,如果一个模块没有隐藏太多信息,则它要么功能不多,要么接口复杂。无论哪种方式,模块都是浅的。将系统分解为模块时,请尽量不要受运行时操作顺序的影响。这将使您沿着时间分解的路径前进,这将导致信息泄漏和模块浅。相反,请考虑执行应用程序任务所需的不同知识,并设计每个模块以封装这些知识中的一个或几个。这将产生带有深色模块的干净简单的设计。
仅当在其模块外部不需要隐藏信息时,隐藏信息才有意义。如果模块外部需要该信息,则不得隐藏它。假设模块的性能受某些配置参数的影响,并且模块的不同用途将需要对参数进行不同的设置。在这种情况下,将参数暴露在模块的界面中很重要,以便可以对其进行适当的旋转。作为软件设计师,您的目标应该是最大程度地减少模块外部所需的信息量。例如,如果模块可以自动调整其配置,那将比公开配置参数更好。但是,重要的是要识别模块外部需要哪些信息,并确保将其公开。
信息隐藏(Information hiding)
实现深层模块最重要的技术是信息隐藏。该技术最早由 David Parnas 描述。基本思想是每个模块应封装一些知识,这些知识代表设计决策。该知识嵌入在模块的实现中,但不会出现在其界面中,因此其他模块不可见。隐藏在模块中的信息通常包含有关如何实现某种机制的详细信息。以下是一些可能隐藏在模块中的信息示例:
- 如何在 B 树中存储信息,以及如何有效地访问它。
- 如何识别与文件中每个逻辑块相对应的物理磁盘块。
- 如何实现 TCP 网络协议。
- 如何在多核处理器上调度线程。
- 如何解析 JSON 文档。
隐藏的信息包括与该机制有关的数据结构和算法。它还可以包含较低级别的详细信息(例如页面大小),还可以包含更抽象的较高级别的概念,例如大多数文件较小的假设。信息隐藏在两个方面降低了复杂性:
- 首先,它将模块简化为接口。接口反映了模块功能的更简单、更抽象的视图,并隐藏了细节,这减少了使用该模块的开发人员的认知负担。例如,使用 B-tree 类的开发人员不需要考虑树中节点的理想扇出,也不需要考虑如何保持树的平衡。
- 其次,信息隐藏使系统更容易演化。如果隐藏了一段信息,那么在包含该信息的模块之外就不存在对该信息的依赖,因此与该信息相关的设计更改将只影响一个模块。例如,如果 TCP 协议发生了变化(例如,为了引入一种新的拥塞控制机制),协议的实现就必须进行修改,但是在使用 TCP 发送和接收数据的高级代码中不需要进行任何修改。
设计新模块时,应仔细考虑可以在该模块中隐藏哪些信息。如果您可以隐藏更多信息,则还应该能够简化模块的界面,这会使模块更深。注意:通过声明变量和方法为私有来隐藏类中的变量和方法与信息隐藏不是同一回事。私有元素可以帮助隐藏信息,因为它们使无法从类外部直接访问项目。但是,有关私人物品的信息仍可以通过公共方法(如 getter 和 setter 方法)公开。发生这种情况时,变量的性质和用法就如同变量是公开的一样暴露。
信息隐藏的最佳形式是将信息完全隐藏在模块中,从而使该信息对模块的用户无关且不可见。但是,部分信息隐藏也具有价值。例如,如果某个类的某些用户仅需要特定的功能或信息,并且可以通过单独的方法对其进行访问,以使其在最常见的用例中不可见,则该信息通常会被隐藏。与类的每个用户可见的信息相比,此类信息将创建更少的依赖项。
信息泄漏(Information leakage)
信息隐藏的反面是信息泄漏。当一个设计决策反映在多个模块中时,就会发生信息泄漏。这在模块之间创建了依赖关系:对该设计决策的任何更改都将要求对所有涉及的模块进行更改。如果一条信息反映在模块的界面中,则根据定义,该信息已经泄漏;因此,更简单的界面往往与更好的信息隐藏相关。但是,即使信息未出现在模块的界面中,也可能会泄漏信息。假设两个类都具有特定文件格式的知识(也许一个类读取该格式的文件,而另一个类写入它们)。即使两个类都不在其接口中公开该信息,它们都取决于文件格式:如果格式更改,则两个类都将需要修改。
信息泄漏是软件设计中最重要的危险信号之一。作为一个软件设计师,你能学到的最好的技能之一就是对信息泄露的高度敏感性。如果您在类之间遇到信息泄漏,请自问“我如何才能重新组织这些类,使这些特定的知识只影响一个类?”如果受影响的类相对较小,并且与泄漏的信息紧密相关,那么将它们合并到一个类中是有意义的。另一种可能的方法是从所有受影响的类中提取信息,并创建一个只封装这些信息的新类。但是,这种方法只有在您能够找到一个从细节中抽象出来的简单接口时才有效;如果新类通过其接口公开了大部分知识,那么它就不会提供太多的价值(您只是用通过接口的泄漏替换了后门泄漏)。
当在多个地方使用相同的知识时,例如两个都理解特定类型文件格式的不同类,就会发生信息泄漏。
时间分解(Temporal decomposition)
信息泄漏的一个常见原因是我称为时间分解的设计风格。在时间分解中,系统的结构对应于操作将发生的时间顺序。考虑一个应用程序,该应用程序以特定格式读取文件,修改文件内容,然后再次将文件写出。通过时间分解,该应用程序可以分为三类:一类用于读取文件,另一类用于执行修改,第三类用于写出新版本。文件读取和文件写入步骤都具有有关文件格式的知识,这会导致信息泄漏。解决方案是将用于读写文件的核心机制结合到一个类中。该类将在应用程序的读取和写入阶段使用。很容易陷入时间分解的陷阱,因为在编写代码时通常会想到必须执行操作的顺序。但是,大多数设计决策会在应用程序的整个生命周期中的多个不同时刻表现出来。结果,时间分解常常导致信息泄漏。
顺序通常很重要,因此它将反映在应用程序中的某个位置。但是,除非该结构与信息隐藏保持一致(也许不同阶段使用完全不同的信息),否则不应将其反映在模块结构中。在设计模块时,应专注于执行每个任务所需的知识,而不是任务发生的顺序。在时间分解中,执行顺序反映在代码结构中:在不同时间发生的操作在不同的方法或类中。如果在执行的不同点使用相同的知识,则会在多个位置对其进行编码,从而导致信息泄漏。