
02.为何使用 K8s
为何使用 K8s
K8s 的功能特性
Kubernates 是建立在扩展性的具备二次开发的功能层次丰富的体系化系统,首先其最核心的功能是管理容器集群,能管理容器化的集群(包括存储,计算),当然这个是建立在对容器运行时(CRI),网络接口(CNI),存储服务接口(CSI/FV)的基础上;其次是面向应用(包括无状态/有状态,批处理/服务型应用)的部署和路由能力,特别是基于微服务架构的应用管理,具备了其服务定义和服务发现,以及基于 configmap 的统一配置能力;在基础资源(主要是抽象底层 IaaS 的资源)和应用层的抽象模型之上是治理层,包含弹性扩容,命名空间/租户,等。当然,基于其原子内核的基础能力,在 K8s 的核心之上搭建统一的日志中心和全方位监控等服务是水到渠成的,CNCF 更是有其认定推荐。
功能
-
服务发现和负载平衡:K8s 可以使用 DNS 名称或使用自己的 IP 地址暴露容器。如果容器的流量很高,K8s 能够负载均衡并分配网络流量,以便部署稳定。
-
存储编排:K8s 允许您自动安装您选择的存储系统,例如本地存储,公共云提供商等。
-
自动部署和回滚:您可以使用 K8s 描述已部署容器的所需状态,并且可以以受控速率将实际状态更改为所需状态。例如,您可以自动化 K8s 为您的部署创建新容器,删除现有容器并将所有资源用于新容器。
-
自动装箱:K8s 允许您指定每个容器需要多少 CPU 和内存(RAM)。当容器指定了资源请求时,K8s 可以更好地决定管理容器的资源。
-
自我修复:K8s 重新启动失败的容器,替换容器,杀死不响应用户定义的运行状况检查的容器,并且在它们准备好服务之前不会将它们通告给客户端。
-
密钥和配置管理:K8s 允许您存储和管理敏感信息,例如密码,OAuth 令牌和 ssh 密钥。您可以部署和更新机密和应用程序配置,而无需重建容器映像,也不会在堆栈配置中暴露机密。
优势
-
它的速度很快:在不停机的情况下持续部署新功能时,K8s 是一个完美的选择。K8s 的目标是以恒定的正常运行时间更新应用程序。它的速度通过您每小时可以运送的许多功能来衡量,同时保持可用的服务。以正确的方式使用 K8s 可帮助 DevOps 即服务团队自动扩展应用程序并以零停机时间进行更新。
-
遵循不可变基础架构的原则:以传统方式,如果多个更新出现任何问题,您就没有任何记录显示您部署了多少更新以及发生了哪个错误。在不可变基础结构中,如果您希望更新任何应用程序,则需要使用新标记构建容器映像并进行部署,从而使用旧映像版本终止旧容器。通过这种方式,您将获得一份记录,并了解您所做的事情以及是否有任何错误; 您可以轻松回滚到上一个图像。
-
提供声明性配置:用户可以知道系统应该处于什么状态以避免错误。作为传统工具的源代码控制,单元测试等不能与命令式配置一起使用,但可以与声明性配置一起使用。
-
大规模部署和更新软件:由于 K8s 具有不可变的声明性,因此扩展很容易。K8s 提供了一些用于扩展目的的有用功能:
- 水平基础架构缩放:在单个服务器级别执行操作以应用水平缩放。可以毫不费力地添加或分离 atest 服务器。
- 自动扩展:根据 CPU 资源或其他应用程序指标的使用情况,您可以更改正在运行的容器数
- 手动缩放:您可以通过命令或界面手动缩放正在运行的容器的数量
- 复制控制器:复制控制器确保群集在运行条件下具有指定数量的等效窗格。如果存在太多 Pod,则复制控制器可以删除额外的 Pod,反之亦然。
-
处理应用程序的可用性:K8s 检查节点和容器的运行状况,并在由于错误导致的盒中崩溃时提供自我修复和自动替换。此外,它在多个 Pod 之间分配负载,以便在意外流量期间快速平衡资源。
-
存储卷:在 K8s 中,数据在容器之间共享,但如果 Pod 被杀死,则会自动删除卷。此外,数据是远程存储的,因此如果将 Pod 移动到另一个节点,数据将保留,直到用户删除为止。
不足
-
初始过程需要时间:创建新进程时,您必须等待应用程序开始,然后才能供用户使用。如果要迁移到 K8s,则需要对代码库进行修改,以使启动过程更有效,这样用户就不会有糟糕的体验。
-
迁移到无状态需要付出很多努力:如果您的应用程序是群集或无状态的,则不会配置额外的 Pod,并且必须在应用程序中重新配置。
-
安装过程繁琐:如果您不使用 Azure,Google 或 Amazon 等任何云提供商,则很难在群集上设置 K8s;不过在有 Rancher 这样的工具辅助下,安装效率也有了大幅度的提高。
云操作系统
在 Kubernetes 诞生之前,很多产品也做过此类尝试,例如 Mesos;Mesos 早期甚至并不支持容器,主要设计的目标也是短任务(后通过 Marathon Framework 支持长服务),更像一个分布式的工作流和任务管理(或者是分布式进程管理)系统,但是已经体现了 Workload 和硬件资源分离的思想。在前 Kubernetes 时代,Mesos 的设计更像是传统的系统工程师对分布式任务调度的思考和实践;K8s 从设计之初就是要在硬件层之上去抽象所有类型的 workload,构建自己的生态系统。如果说 Mesos 还是个工具的话,那么 K8s 的目标其实是奔着做一个分布式操作系统去的。
简单做个类比:整个集群的计算资源统一管控起来就像一个单机的物理计算资源,容器就像一个个进程,Overlay network 就像进程通信,镜像就像一个个可执行文件,Controller 就像 Systemd,Kubectl 就像 Shell 等。从另一方面看,Kubernetes 为各种 IaaS 层提供了一套标准的抽象,不管你底层是自己的数据中心的物理机,还是某个公有云的 VM,只要你的服务是构建在 K8s 之上,那么就获得了无缝迁移的能力。
微服务
现在我们都习惯了使用微服务来构建服务端架构,K8s 它不仅仅提供了对于基础云资源的管控,它还为我们在设计微服务之中所需的设计要素提供了对应的解决方案:
- API 网关:Ingress
- 无状态化:区分有状态与无状态的应用,K8s 中无状态对应 Deployment,有状态对应 StatefulSet
- 数据库的横向扩展:Headless Service 指向 PaaS 服务,或者 StatefulSet 部署
- 缓存:Headless Service 指向 PaaS 服务,或者 StatefulSet 部署
- 服务拆分与服务发现:Service
- 服务编排与弹性伸缩:Deployment 的 Replicas
- 统一配置中心:ConfigMap
- 统一的日志中心:DaemonSet 部署日志 Agent
- 熔断,限流,降级:Service Mesh
- 全方位的监控:Cadvisor,DaemonSet 部署监控
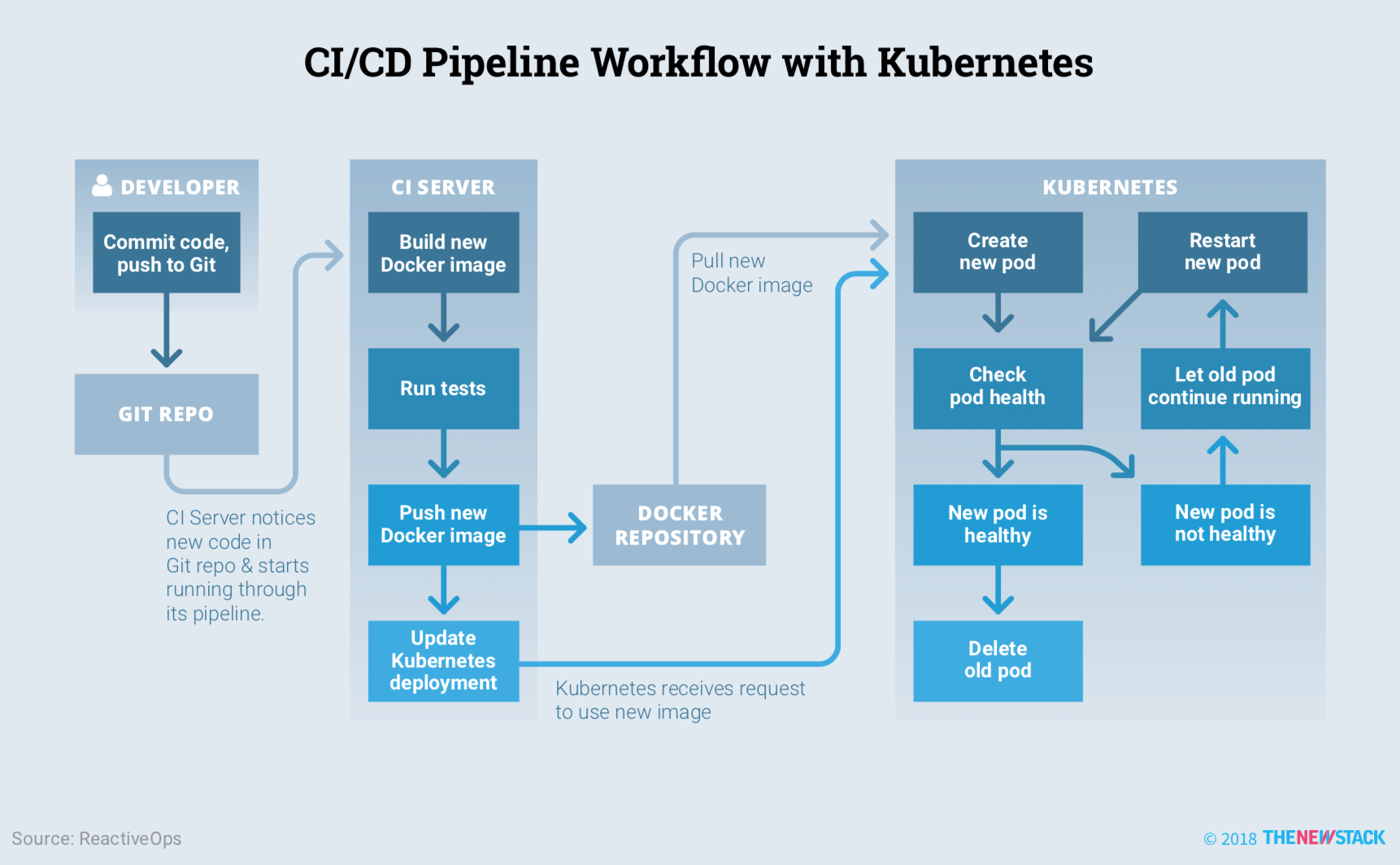
Kubernetes、Service Mesh 和 Serverless 三者共同演绎不同层次的封装和向上屏蔽下面的细节。Kubernetes 引入了不同的设计模式,实现对各种云资源全新、有效和优雅的抽象和管理模式,让集群的管理和应用发布变成了件相当轻松且不易出错的事。被广泛采用的微服务软件架构将分布式应用的各种复杂度迁移到了服务之间,如何通过全局一致、体系化、规范化和无侵入的手段进行治理就变成了微服务软件架构下至关重要的内容。Kubernetes 细化的应用程序的分解粒度,同时将服务发现、配置管理、负载均衡和健康检查等作为基础设施的功能,简化了应用程序的开发。而 Kubernetes 这种声明式配置尤其适合 CI/CD 流程,况且现在还有如 Helm、Draft、Spinnaker、Skaffold 等开源工具可以帮助我们发布 Kuberentes 应用。
Service Mesh 通过将各服务所共用和与环境相关的内容剥离到部署于每个服务边上的 Sidecar 进程而轻松地做到了。这一剥离动作使得服务与平台能充分解耦而方便各自演进与发展,也使得服务变轻而有助于改善服务启停的及时性。Service Mesh 因为将那些服务治理相关的逻辑剥离到了 Sidecar 中且作为独立进程,所以 Sidecar 所实现的功能天然地支持多语言,为上面的服务采用多语言开发创造了更为有利的条件。通过 Service Mesh 对整个网络的服务流量进行技术收口,让异地多活这样涉及流量调度的系统工程实现起来更加优雅、简洁与有效,也能更加方便地实现服务版本升级时的灰度、回滚而改善安全生产质量。由于技术收口,给服务流量的治理和演进、排错、日志采集的经济性等疑难问题创造了新的发展空间。
基础设施使用 YAML 表达
从 Puppet 和 Chef 的世界里走出来,Kubernetes 的一个重要转变是,从以代码为基础的基础架构转向了以数据为基础的基础架构。具体来说,就是 YAML。Kubernetes 中的所有资源,包括 Pod、Configurations、Deployments、Volumes 等,都可以简单地用 YAML 文件来表达。比如:
apiVersion: v1
kind: Pod
metadata:
name: site
labels:
app: web
spec:
containers:
- name: front-end
image: nginx
ports:
- containerPort: 80
这种表示方式使 DevOps 或 SRE 工程师更容易完全表达工作负载,而不需要在 Python、Ruby 或 Javascript 等语言中用代码表示。将基础架构作为数据的好处还包括:
-
GitOps 或 Git 操作版本控制。使用这种方法,你可以将所有的 Kubernetes YAML 文件都保存在 git 仓库下,这样你就可以准确地知道何时进行了更改,谁做了更改,以及具体更改了什么。这使得整个组织的透明度更高,并且通过避免团队成员弄不清楚去哪里寻找配置,从而提高了效率。同时,只需合并一个拉动请求,就可以更方便地自动化更改 Kubernetes 资源。
-
可扩展性。将资源定义为 YAML,使得集群操作人员在 Kubernetes 资源中改变一两个数字来扩容或者缩容集群。Kubernetes 有水平 pod 自动缩放器,可以指定给定部署所需要的最小和最大 pod 数量,以便能自动缩容/扩容应对流量低谷/高峰。例如,如果你正在运行的部署可能因为流量突增而需要更多的容量,你可以将 maxReplicas 从 10 个改为 20 个。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deployment
minReplicas: 1
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- 安全和控制。YAML 是验证在 Kubernetes 中部署什么和如何部署的好方法。例如,当涉及到安全问题时,一个重要的关注点就是你的工作负载是否以非 root 用户的身份运行。我们可以利用像 conftest 这样的工具(YAML/JSON 验证器),再加上 Open Policy Agent 这样的策略验证器,来检查你的工作负载的 SecurityContext 是否不允许容器作为 root 用户运行。为此,用户可以使用一个简单的 Open Policy Agent rego 策略,如下。
package main
deny[msg] {
input.kind = "Deployment"
not input.spec.template.spec.securityContext.runAsNonRoot = true
msg = "Containers must not run as root"
}
- 云供应商的整合。科技行业的主要趋势之一就是在公有云供应商中运行工作负载。在云供应商组件的帮助下,Kubernetes 允许每个集群与它所运行的云供应商进行集成。例如,如果用户在 AWS 中的 Kubernetes 中运行某应用程序,并希望该应用程序可以通过服务访问,云供应商会帮助自动创建一个 LoadBalancer 服务,该服务会自动提供一个 Amazon Elastic Load Balancer 来将流量转发到应用程序的 pods。
可扩展性
Kubernetes 的可扩展性很强,开发者很喜欢这一点。Kubernetes 已经内置了很多资源,如 Pods、Deployments、StatefulSets、Secrets、ConfigMaps 等。然而用户和开发者可以通过自定义资源定义的形式添加更多的资源。例如,如果我们想定义一个 CronTab 资源,我们可以这样做。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.my.org
spec:
group: my.org
versions:
- name: v1
served: true
storage: true
Schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
pattern: '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
replicas:
type: integer
minimum: 1
maximum: 10
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
我们以后可以用如下的方式创建一个 CronTab 资源。
apiVersion: "my.org/v1"
kind: CronTab
metadata:
name: my-cron-object
spec:
cronSpec: "* * * * */5"
image: my-cron-image
replicas: 5
Kubernetes 可扩展性的另一种形式是开发者可以编写自己的 Operator,这是一个在 Kubernetes 集群中运行的特定进程,遵循控制循环模式。一个 Operator 允许用户通过与 Kubernetes API 对话来自动管理 CRD(自定义资源定义)。社区有几个工具,允许开发者创建自己的 Operator。其中一个工具是 Operator Framework 及其 Operator SDK。该 SDK 为开发者提供了一个框架,让他们可以非常快速地开始创建 Operator。例如,您可以通过以下命令行开始创建 Operator。
$ operator-sdk new my-operator --repo github.com/myuser/my-operator
这就为你的 Operator 创建了包括 YAML 文件和 Golang 代码在内的整个样板。
.
|____cmd
| |____manager
| | |____main.go
|____go.mod
|____deploy
| |____role.yaml
| |____role_binding.yaml
| |____service_account.yaml
| |____operator.yaml
|____tools.go
|____go.sum
|____.gitignore
|____version
| |____version.go
|____build
| |____bin
| | |____user_setup
| | |____entrypoint
| |____Dockerfile
|____pkg
| |____apis
| | |____apis.go
| |____controller
| | |____controller.go
添加 API 和控制器的方式如下。
$ operator-sdk add api --api-version=myapp.com/v1alpha1 --kind=MyAppService
$ operator-sdk add controller --api-version=myapp.com/v1alpha1 --kind=MyAppService
最后构建并推送 Operator 到你的容器注册表中。
$ operator-sdk build your.container.registry/youruser/myapp-operator
如果开发者需要更多的控制权,他们可以修改 Golang 文件中的样板代码。例如,要修改控制器的具体内容,他们可以对 controller.go 文件进行修改。
另一个项目 KUDO 只需使用声明式的 YAML 文件就可以创建 Operator。例如,Apache Kafka 的 Operator 就是这样定义的,它允许用户在 Kubernetes 上面安装一个 Kafka 集群,只需要几条命令就可以了。
$ kubectl kudo install zookeeper
$ kubectl kudo install kafka
然后用另一个命令来调整 kafka 参数。
$ kubectl kudo install kafka --instance=my-kafka-name \
-p ZOOKEEPER_URI=zk-zookeeper-0.zk-hs:2181 \
-p ZOOKEEPER_PATH=/my-path -p BROKER_CPUS=3000m \
-p BROKER_COUNT=5 -p BROKER_MEM=4096m \
-p DISK_SIZE=40Gi -p MIN_INSYNC_REPLICAS=3 \
-p NUM_NETWORK_THREADS=10 -p NUM_IO_THREADS=20