
01.设计理念
Kubernetes 设计理念
分析和理解 Kubernetes 的设计理念可以使我们更深入地了解 Kubernetes 系统,更好地利用它管理分布式部署的云原生应用,另一方面也可以让我们借鉴其在分布式系统设计方面的经验。
能力抽象
与一般的 PaaS 平台相比,K8s 也是支持服务部署、自动运维、资源调度、扩缩容、自我修复、负载均衡,服务发现等功能,而其独特之处就是其对于基础设施层进行了较好的能力抽象。K8s 并没有处理具体的存储、网络这些差异性极大的部分,而是做云无关,开始实现各类 interface,做各种抽象。比如容器运行时接口(CRI)、容器网络接口(CNI)、容器存储接口(CSI)。这些接口让 Kubernetes 变得无比开放,而其本身则可以专注于内部部署及容器调度。
Kubernetes 生态中也会有很多通用的功能,比如服务发现、负载均衡、日志系统、监控系统等,这些都有提供默认方案,且这些方案都是可选、可插拔的。这些也都可以看作是 PaaS 平台的基础设施,在 Kubernetes 上也没有强绑强销的买卖,给用户提供了高度的灵活性。
Kubernetes 的各种功能都离不开它定义的资源对象,这些对象都可以通过 API 被提交到集群的 Etcd 中。API 的定义和实现都符合 HTTP REST 的格式,用户可以通过标准的 HTTP 动词(POST、PUT、GET、DELETE)来完成对相关资源对象的增删改查。常用的资源对象,比如 Deployment、DaemonSet、Job、PV 等。API 的抽象也意在这部分资源对象的定义。Kubernetes 有新的功能实现,一般会创建新的资源对象,而功能也依托于该对象进行实现。
分层架构
Kubernetes 有类似于 Linux 的分层架构,如下图所示:

-
基础设施层:包括容器运行时、网络、存储等。
-
核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境。
-
应用层:部署(无状态、有状态应用、Job 等)和路由(服务发现、负载均衡等)
-
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
-
接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
-
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等外部生态以及 CRI、CNI、CSI、镜像仓库、Cloud Provider、集群自身的配置和管理等内部生态。
声明式设计与控制闭环
Kubernetes 采用了声明式(Declarative)的资源管理模式,该模式会有如下几个步骤:
-
声明:用户通过声明式的配置文件(json/yaml 等)向 Kubernetes 告诉所期望达到的应用状态。(比如:运行 2 个副本的 Nginx 服务)
-
观测:Kubernetes 会观测到用户的声明,并自动分析出需要执行的操作及用户所期望达到的应用状态。(比如选取合适的节点,配置相应的负载均衡策略等)
-
行动:Kubernetes 控制器会负责具体的工作执行,以达到用户声明的应用状态,该过程是全自动化。
-
持续观测与收敛:大型分布式系统必然会存在各种异常,比如系统崩溃、容器退出等。Kubernetes 自然会持续关注系统的实时状态,当遇到异常时能够及时的进行自我修复。比如用户声明了 2 个 Nginx 服务,当其中有个 Nginx 挂了,或者所在的宿主机挂了,Kubernetes 会自动发现,并寻找合适的节点,再运行一个新的 Nginx 服务,以维持用户所期望达到的应用状态。
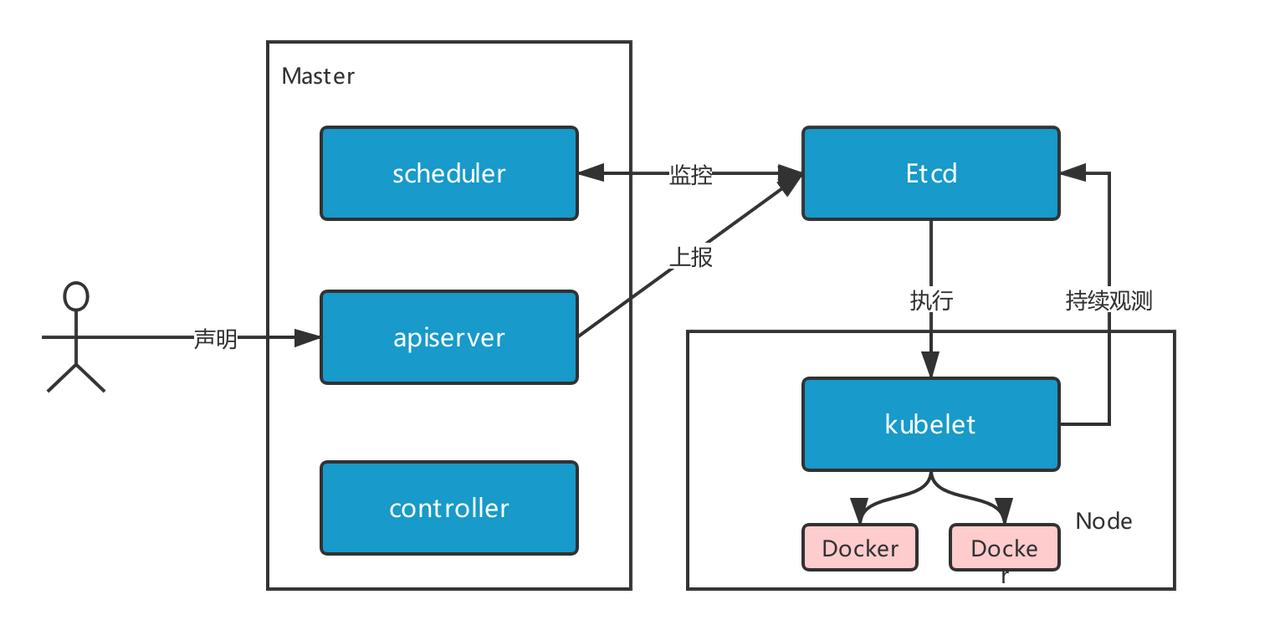
相对于命令式操作,声明式操作会更稳定且更容易被用户接受,因为该 API 中隐含了用户想要操作的目标对象,而这些对象刚好都是名词性质的,比如 Service、Deployment、PV 等;且声明式的配置文件更贴近“人类语言”,比如 YAML、JSON。
声明式的设计理念有助于实现控制闭环,持续观测、校正,最终将运行状态达到用户期望的状态;感知用户的行为并执行。比如修改 Pod 数量,应用升级/回滚等等。调度器是核心,但它只是负责从集群节点中选择合适的 node 来运行 pods,显然让调度器来实现上诉的功能不太合适,而需要有专门的控制器组件来实现。
Kubernetes 中所有的配置都是通过 API 对象的 spec 去设置的,也就是用户通过配置系统的理想状态来改变系统,这是 Kubernetes 重要设计理念之一,即所有的操作都是声明式(Declarative)的而不是命令式(Imperative)的。声明式操作在分布式系统中的好处是稳定,不怕丢操作或运行多次,例如设置副本数为 3 的操作运行多次也还是一个结果,而给副本数加 1 的操作就不是声明式的,运行多次结果就错了。
Kubernetes 实现了大量的 Controllers,它们通过 list-watch etcd 来感知集群数据的更新,然后 24 小时不间断的工作以达到期待的状态,在该过程中它们也会把创建的各类数据反馈回 kube-apiserver & etcd,从而形成了数据流的闭环。kube-controller-manager 不仅完成了 Kubernetes 集群功能的大部分,还提供很强大的扩展能力,可以让用户轻松的实现自己的 controllers。
API 设计原则
Kubernetes 集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的 API 对象,支持对该功能的管理操作,理解掌握的 API,就好比抓住了 Kubernetes 系统的牛鼻子。Kubernetes 系统 API 的设计有以下几条原则:
-
所有 API 应该是声明式的。正如前文所说,声明式的操作,相对于命令式操作,对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。另外,声明式操作更容易被用户使用,可以使系统向用户隐藏实现的细节,隐藏实现的细节的同时,也就保留了系统未来持续优化的可能性。此外,声明式的 API,同时隐含了所有的 API 对象都是名词性质的,例如 Service、Volume 这些 API 都是名词,这些名词描述了用户所期望得到的一个目标分布式对象。
-
API 对象是彼此互补而且可组合的。这里面实际是鼓励 API 对象尽量实现面向对象设计时的要求,即“高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。事实上,Kubernetes 这种分布式系统管理平台,也是一种业务系统,只不过它的业务就是调度和管理容器服务。
-
高层 API 以操作意图为基础设计。如何能够设计好 API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。因此,针对 Kubernetes 的高层 API 设计,一定是以 Kubernetes 的业务为基础出发,也就是以系统调度管理容器的操作意图为基础设计。
-
低层 API 根据高层 API 的控制需要设计。设计实现低层 API 的目的,是为了被高层 API 使用,考虑减少冗余、提高重用性的目的,低层 API 的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
-
尽量避免简单封装,不要有在外部 API 无法显式知道的内部隐藏的机制。简单的封装,实际没有提供新的功能,反而增加了对所封装 API 的依赖性。内部隐藏的机制也是非常不利于系统维护的设计方式,例如 StatefulSet 和 ReplicaSet,本来就是两种 Pod 集合,那么 Kubernetes 就用不同 API 对象来定义它们,而不会说只用同一个 ReplicaSet,内部通过特殊的算法再来区分这个 ReplicaSet 是有状态的还是无状态。
-
API 操作复杂度与对象数量成正比。这一条主要是从系统性能角度考虑,要保证整个系统随着系统规模的扩大,性能不会迅速变慢到无法使用,那么最低的限定就是 API 的操作复杂度不能超过 O(N),N 是对象的数量,否则系统就不具备水平伸缩性了。
-
API 对象状态不能依赖于网络连接状态。由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证 API 对象状态能应对网络的不稳定,API 对象的状态就不能依赖于网络连接状态。
-
尽量避免让操作机制依赖于全局状态,因为在分布式系统中要保证全局状态的同步是非常困难的。
控制机制设计原则
-
控制逻辑应该只依赖于当前状态。这是为了保证分布式系统的稳定可靠,对于经常出现局部错误的分布式系统,如果控制逻辑只依赖当前状态,那么就非常容易将一个暂时出现故障的系统恢复到正常状态,因为你只要将该系统重置到某个稳定状态,就可以自信的知道系统的所有控制逻辑会开始按照正常方式运行。
-
假设任何错误的可能,并做容错处理。在一个分布式系统中出现局部和临时错误是大概率事件。错误可能来自于物理系统故障,外部系统故障也可能来自于系统自身的代码错误,依靠自己实现的代码不会出错来保证系统稳定其实也是难以实现的,因此要设计对任何可能错误的容错处理。
-
尽量避免复杂状态机,控制逻辑不要依赖无法监控的内部状态。因为分布式系统各个子系统都是不能严格通过程序内部保持同步的,所以如果两个子系统的控制逻辑如果互相有影响,那么子系统就一定要能互相访问到影响控制逻辑的状态,否则,就等同于系统里存在不确定的控制逻辑。
-
假设任何操作都可能被任何操作对象拒绝,甚至被错误解析。由于分布式系统的复杂性以及各子系统的相对独立性,不同子系统经常来自不同的开发团队,所以不能奢望任何操作被另一个子系统以正确的方式处理,要保证出现错误的时候,操作级别的错误不会影响到系统稳定性。
-
每个模块都可以在出错后自动恢复。由于分布式系统中无法保证系统各个模块是始终连接的,因此每个模块要有自我修复的能力,保证不会因为连接不到其他模块而自我崩溃。
-
每个模块都可以在必要时优雅地降级服务。所谓优雅地降级服务,是对系统鲁棒性的要求,即要求在设计实现模块时划分清楚基本功能和高级功能,保证基本功能不会依赖高级功能,这样同时就保证了不会因为高级功能出现故障而导致整个模块崩溃。根据这种理念实现的系统,也更容易快速地增加新的高级功能,因为不必担心引入高级功能影响原有的基本功能。