
04.全链路可观测
全链路可观测
2015 年前后,分布式系统也已成熟,微服务架构尚未普及,可观测问题就已经在桎梏技术团队的工作效率。一个 To C 的软件使用问题可能由客服发起,整条支撑链路的所有技术部门,都要逐一排查接口和日志,流程非常原始,也非常低效。如果业务到达一个量级,支撑系统变多,两名研发查上两三个星期也是常事。微服务架构普及后,问题变得更加严峻。一个服务被拆分成数个黑盒的、虚拟的微服务,故障排除彻底成为一种折磨。
因此,可观测问题正在悄然成为 IT 行业的热门话题。2016 年,一本名叫《Site Reliability Engineering - How Google Runs Production Systems》出版,谷歌的工程师在书中描绘了故障生命周期的五个阶段:故障预防、故障发现、故障定位、故障恢复、故障改进。而对 IT 系统故障的发现和定位,正是可观测问题的另一种诠释,某种程度上也最接近可观测问题本质的定义。
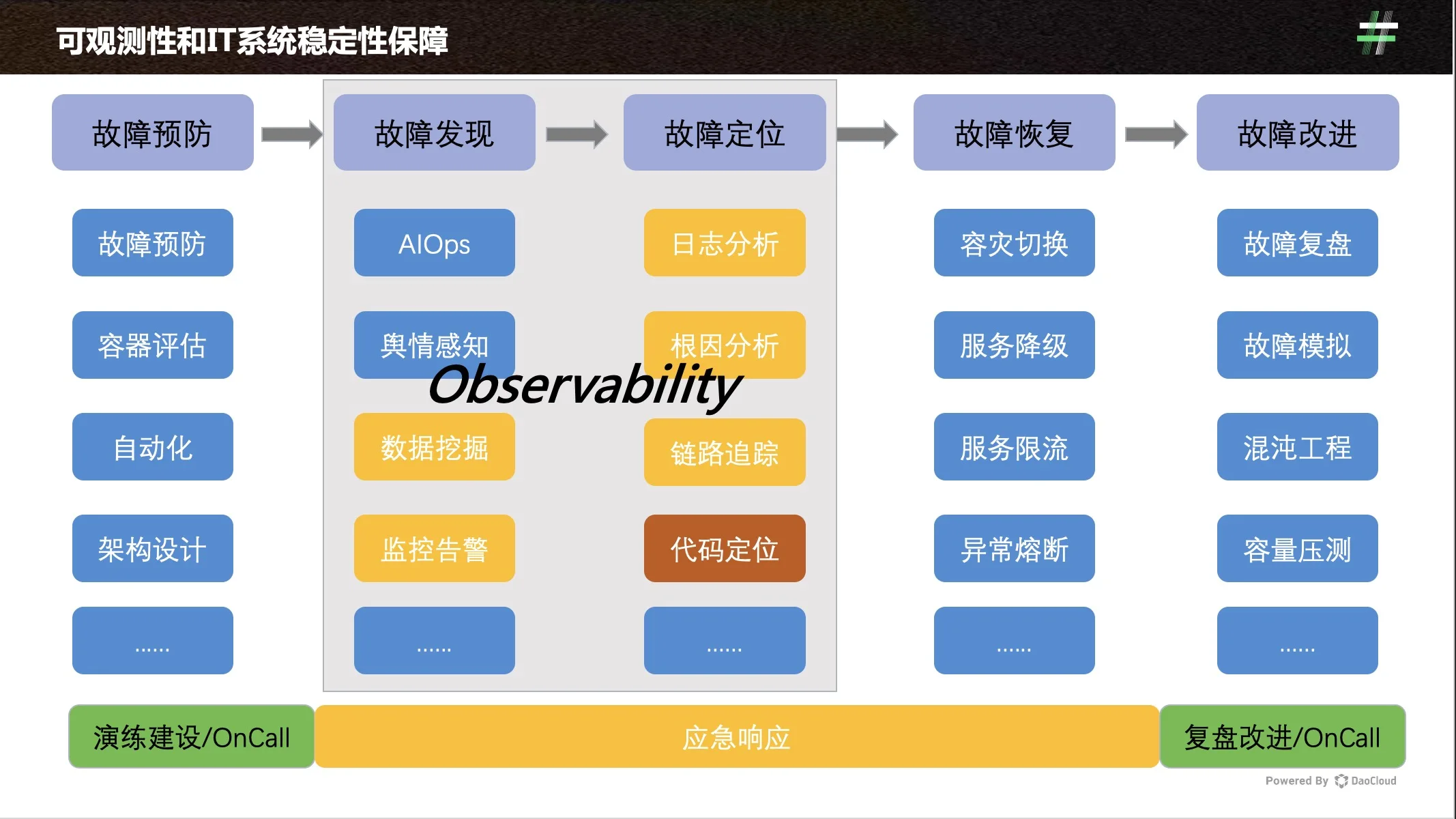
在此基础上,我们可以将可观测问题大致分为四类:
-
分布式链路追踪技术:可观测的基石,在用户一次请求服务的调⽤过程中,无论请求被分发到多少个子系统,子系统又调用了多少其他子系统,我们都要把系统信息和系统间调用关系都追踪记录下来,最终把数据集中起来做可视化展示。
-
APM:Application Performance Monitoring,应用性能监控,主要是为了对企业核心业务系统进行性能的故障定位和处理,帮助优化性能,提高业务系统的可靠性和用户体验,更多偏向产品维度,其底层虽依赖分布式链路追踪技术,但不能直接用来解决分布式链路追踪的问题。
-
NPM:Network Performance Monitoring,网络性能监控,其关键在于实现全网流量的可视化,对数据包、网络接口、流数据进行监控和分析。
-
RUM:Real User Monitoring,真实用户监控,关键在于端到端反应用户的真实体验,捕捉用户和页面的每一个交互并分析其性能,是种高度实用主义的监控设计。
同时,可观测存在三个主要的数据源:
- 指标(metrics)
- 链路(trace)
- 日志(log)
其中指标告诉我们是否有故障,链路告诉我们故障在哪里,日志则告诉我们故障的原因。
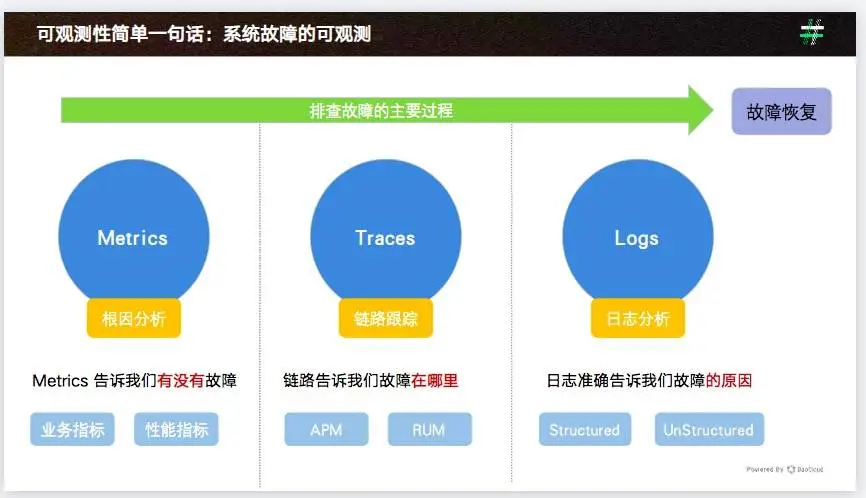
这三类可观测问题加上三种监控类型,共同构成了可观测问题的主要内容。