
02.缓存
缓存
在互联网领域, 流行着这么一句话:90%的流量由 10%的内容产生。缓存也由此产生: 只为最频繁访问的 10%的内容提供更快的存储, 就可以以很低的成本提供尽可能好的服务质量。一般符合这种互联网访问模型的曲线是下图这样的. 对每个访问的 url 做独立计数, 并按照从访问最多到最低排序:

缓存是软件系统中常见的组成部分,其能够提升系统的请求处理与响应能力,避免重复地处理,快速返回常见的数据:
背景分析
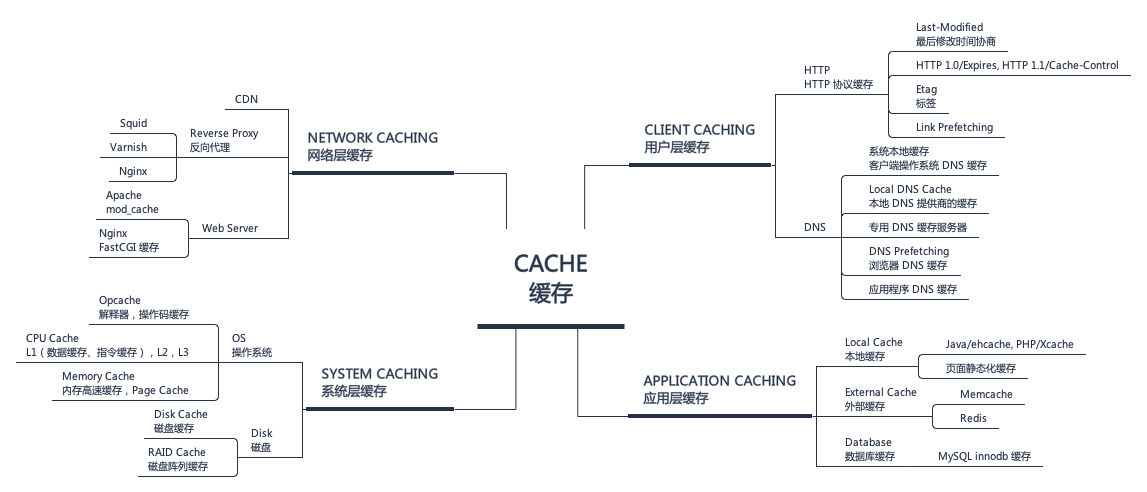
功能与分类

缓存系统的主要功能常常有:
-
数据库缓存:作为数据库与 DAO 层之间的中间缓存,降低对后端数据库的访问压力,高速缓存能使得访问速度达到 1ms 级别,例如高频率的数据库查询。
-
临时数据存储:应用程序需要维护大量临时数据,将临时数据存储在缓存系统中,可以降低内存管理的开销,改进应用程序工作负载。例如:在分布式系统中,同一个用户的不同请求可能会发送到不同的服务器上,这时可以用缓存作为全局存储,用于保存 Session 数据、用户的 Token、权限信息等数据。
-
部分数据的持久化存储:此时类似于传统的数据库,将数据存入磁盘中做持久化存储,例如广告推荐类需要离线计算大量数据以及榜单的生成。
我们往往会从系统层、应用层、网络层、用户层等不同的维度去提高缓存机制与策略。客户端缓存也被称为“浏览器缓存”,下载数据的客户端,浏览器,应用程序,其他服务等可以跟踪下载的内容,如果该数据有任何过期时间,则 ETag 为最后一个请求允许条件、请求数据是否已更改等。网络层缓存中,类似于 Varnish或Squid 拦截看起来相同的请求(基于各种可配置标准),尽早直接从内存中返回响应,而不是点击应用程序服务器。这允许应用服务器花费更多时间处理其他流量。应用层缓存则是 Memcache,Redis 等软件可以在您的应用程序中实现,以缓存数据存储查询等各种内容,这样可以更快地生成响应。
变更订阅
当今流行的应用开发风格涉及将功能分解为一组通过同步网络请求(如 REST API)进行通信的服务(service)。这种面向服务的架构优于单一庞大应用的优势主要在于:通过松散耦合来提供组织上的可扩展性:不同的团队可以专职于不同的服务上,从而减少团队之间的协调工作(因为服务可以独立部署和更新)。在数据流中组装流算子与微服务方法有很多相似之处。但底层通信机制是有很大区别:数据流采用单向异步消息流,而不是同步的请求/响应式交互。
除了在“消息传递数据流”中列出的优点(如更好的容错性),数据流系统还能实现更好的性能。例如,假设客户正在购买以一种货币定价,但以另一种货币支付的商品。为了执行货币换算,你需要知道当前的汇率。这个操作可以通过两种方式实现:
- 在微服务方法中,处理购买的代码可能会查询汇率服务或数据库,以获取特定货币的当前汇率。
- 在数据流方法中,处理订单的代码会提前订阅汇率变更流,并在汇率发生变动时将当前汇率存储在本地数据库中。处理订单时只需查询本地数据库即可。
第二种方法能将对另一服务的同步网络请求替换为对本地数据库的查询(可能在同一台机器甚至同一个进程中)。数据流方法不仅更快,而且当其他服务失效时也更稳健。最快且最可靠的网络请求就是压根没有网络请求!我们现在不再使用 RPC,而是在购买事件和汇率更新事件之间建立流联接。连接是时间相关的:如果购买事件在稍后的时间点被重新处理,汇率可能已经改变。如果要重建原始输出,则需要获取原始购买时的历史汇率。无论是查询服务还是订阅汇率更新流,你都需要处理这种时间相关性。订阅变更流,而不是在需要时查询当前状态,使我们更接近类似电子表格的计算模型:当某些数据发生变更时,依赖于此的所有衍生数据都可以快速更新。还有很多未解决的问题,例如关于时间相关连接等问题,但我认为围绕数据流构建应用的想法是一个非常有希望的方向。
Links
- https://mp.weixin.qq.com/s/jdOVzGTyi_6mgK7Gkr4yMA
- https://www.zhihu.com/question/319817091/answer/653985863
- https://zhuanlan.zhihu.com/p/70597595
- https://zhuanlan.zhihu.com/p/72671938 Redis 与 Mysql 双写一致性方案解析
- https://zhuanlan.zhihu.com/p/91770135 如何保障 mysql 和 redis 之间的数据一致性?
- https://zhuanlan.zhihu.com/p/74880843
- https://www.zhihu.com/question/26190832/answer/825301105 Cache 和 Buffer 都是缓存,主要区别是什么?
- https://cubox.pro/c/vBop8Y 本文源自并发编程网的翻译邀请,翻译的是 Jakob Jenkov 的 《软件架构》 中关于缓存技术的内容,虽然是 2014 年的文章,但是从软件架构层面上,并不过时。
- https://zhuanlan.zhihu.com/p/106101091 如何保障 mysql 和 redis 之间的数据一致性?