
ZooKeeper
ZooKeeper
ZooKeeper 是一种用于分布式应用程序的分布式开源协调服务。它公开了一组简单的原语,分布式应用程序可以构建这些原语,以实现更高级别的服务,以实现同步,配置维护以及组和命名。它被设计为易于编程,并使用在熟悉的文件系统目录树结构之后设计的数据模型。它在 Java 中运行,并且具有 Java 和 C 的绑定。
ZooKeeper 最早起源于雅虎研究院的一个研究小组。当时,雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
-
顺序一致性,来自任意特定客户端的更新都会按其发送顺序被提交。也就是说,如果一个客户端将 Znode z 的值更新为 a,在之后的操作中,它又将 z 的值更新为 b,则没有客户端能够在看到 z 的值是 b 之后再看到值 a(如果没有其他对 z 的更新)。
-
原子性,每个更新要么成功,要么失败。这意味着如果一个更新失败,则不会有客户端会看到这个更新的结果。
-
单一系统映像,一个客户端无论连接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比 在之前服务器上所看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务器时,所有滞后于故障服务器的服务器都不会接受该 连接请求,除非这些服务器赶上故障服务器。
-
持久性/可靠性,一个更新一旦成功,其结果就会持久存在并且不会被撤销。这表明更新不会受到服务器故障的影响。
-
实时性:一旦一个事务被成功应用后,Zookeeper 可以保证客户端立即可以读取到这个事务变更后的最新状态的数据。
二、Zookeeper 设计目标
Zookeeper 致力于为那些高吞吐的大型分布式系统提供一个高性能、高可用、且具有严格顺序访问控制能力的分布式协调服务。它具有以下四个目标:
2.1 目标一:简单的数据模型
Zookeeper 通过树形结构来存储数据,它由一系列被称为 ZNode 的数据节点组成,类似于常见的文件系统。不过和常见的文件系统不同,Zookeeper 将数据全量存储在内存中,以此来实现高吞吐,减少访问延迟。

2.2 目标二:构建集群
可以由一组 Zookeeper 服务构成 Zookeeper 集群,集群中每台机器都会单独在内存中维护自身的状态,并且每台机器之间都保持着通讯,只要集群中有半数机器能够正常工作,那么整个集群就可以正常提供服务。
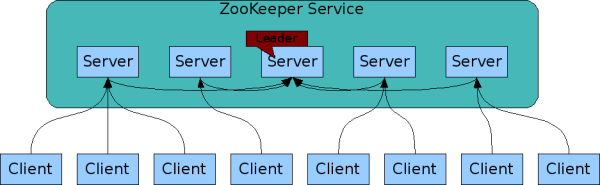
2.3 目标三:顺序访问
对于来自客户端的每个更新请求,Zookeeper 都会分配一个全局唯一的递增 ID,这个 ID 反映了所有事务请求的先后顺序。
2.4 目标四:高性能高可用
ZooKeeper 将数据存全量储在内存中以保持高性能,并通过服务集群来实现高可用,由于 Zookeeper 的所有更新和删除都是基于事务的,所以其在读多写少的应用场景中有着很高的性能表现。