
Snowflake
Snowflake
Snowflake 算法产生于 Twitter 的高并发场景下,其需要为每秒上万条消息的请求分配一条唯一的 ID,这些 ID 还需要一些大致的顺序以方便客户端排序,并且在分布式系统中不同机器产生的 ID 必须不同。Snowflake 算法的核心思想在于,使用一个 64 bit 的 long 型的数字作为全局唯一 ID。这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。
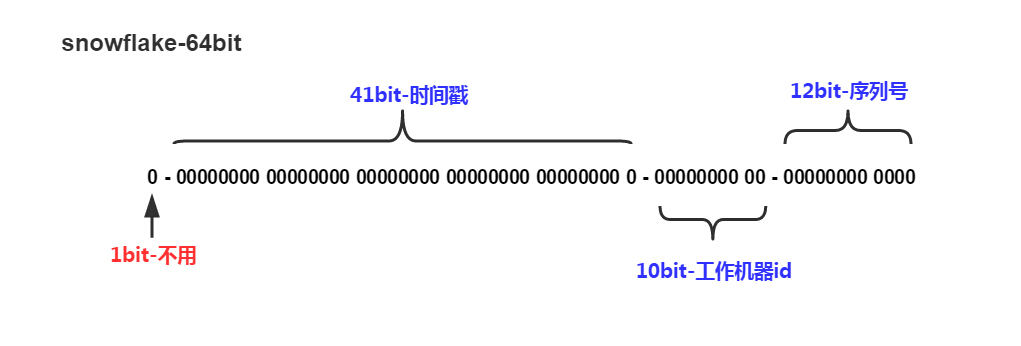
首位 bit 不可用,是因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。除了最高位 bit 标记为不可用以外,其余三组 bit 占位均可浮动,看具体的业务需求而定。默认情况下 41bit 的时间戳可以支持该算法使用到 2082 年,10bit 的工作机器 id 可以支持 1023 台机器,序列号支持 1 毫秒产生 4095 个自增序列 id。由此也可看出,Snowflake 限制 workid 最多能有 1024,也就是说,应用规模不能超过 1024;虽然可以进行细微的调整,但是总是有数量的限制。
在《Database-Notes》一文中,我们也讨论了该算法的作用。
时间戳
这里时间戳的细度是毫秒级,具体代码如下,建议使用 64 位 linux 系统机器,因为有 vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
uint64_t generateStamp()
{
timeval tv;
gettimeofday(&tv, 0);
return (uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
}
默认情况下有 41 个 bit 可以供使用,那么一共有 T(1llu « 41)毫秒供你使用分配,年份 = T / (3600 _ 24 _ 365 * 1000) = 69.7 年。如果你只给时间戳分配 39 个 bit 使用,那么根据同样的算法最后年份 = 17.4 年。总体来说,是一个很高效很方便的 GUID 产生算法,一个 int64_t 字段就可以胜任,不像现在主流 128bit 的 GUID 算法,即使无法保证严格的 id 序列性,但是对于特定的业务,比如用做游戏服务器端的 GUID 产生会很方便。另外,在多线程的环境下,序列号使用 atomic 可以在代码实现上有效减少锁 的密度。
工作机器 ID
严格意义上来说这个 bit 段的使用可以是进程级,机器级的话你可以使用 MAC 地址来唯一标示工作机器,工作进程级可以使用 IP+Path 来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个 id 是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。 这里的解决方案是需要一个工作 id 分配的进程,可以使用自己编写一个简单进程来记录分配 id,或者利用 Mysql auto_increment 机制也可以达到效果。

工作进程与工作 id 分配器只是在工作进程启动的时候交互一次,然后工作进程可以自行将分配的 id 数据落文件,下一次启动直接读取文件里的 id 使用。PS:这个工作机器 id 的 bit 段也可以进一步拆分,比如用前 5 个 bit 标记进程 id,后 5 个 bit 标记线程 id 之类。
序列号
序列号就是一系列的自增 id(多线程建议使用 atomic),为了处理在同一毫秒内需要给多条消息分配 id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
uint64_t waitNextMs(uint64_t lastStamp)
{
uint64_t cur = 0;
do {
cur = generateStamp();
} while (cur <= lastStamp);
return cur;
}
代码实现
Java
public class IdWorker {
private long workerId; // 这个就是代表了机器id
private long datacenterId; // 这个就是代表了机房id
private long sequence; // 这个就是代表了一毫秒内生成的多个id的最新序号
public IdWorker(long workerId, long datacenterId, long sequence) {
// sanity check for workerId
// 这儿不就检查了一下,要求就是你传递进来的机房id和机器id不能超过32,不能小于0
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(
String.format(
"worker Id can't be greater than %d or less than 0",
maxWorkerId
)
);
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(
String.format(
"datacenter Id can't be greater than %d or less than 0",
maxDatacenterId
)
);
}
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
// 这个是二进制运算,就是5 bit最多只能有31个数字,也就是说机器id最多只能是32以内
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 这个是一个意思,就是5 bit最多只能有31个数字,机房id最多只能是32以内
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift =
sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
private long lastTimestamp = -1L;
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
// 这个是核心方法,通过调用nextId()方法,让当前这台机器上的snowflake算法程序生成一个全局唯一的id
public synchronized long nextId() {
// 这儿就是获取当前时间戳,单位是毫秒
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf(
"clock is moving backwards. Rejecting requests until %d.",
lastTimestamp
);
throw new RuntimeException(
String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp
)
);
}
// 下面是说假设在同一个毫秒内,又发送了一个请求生成一个id
// 这个时候就得把seqence序号给递增1,最多就是4096
if (lastTimestamp == timestamp) {
// 这个意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,
//这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
// 这儿记录一下最近一次生成id的时间戳,单位是毫秒
lastTimestamp = timestamp;
// 这儿就是最核心的二进制位运算操作,生成一个64bit的id
// 先将当前时间戳左移,放到41 bit那儿;将机房id左移放到5 bit那儿;将机器id左移放到5 bit那儿;将序号放最后12 bit
// 最后拼接起来成一个64 bit的二进制数字,转换成10进制就是个long型
return (
((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence
);
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
//---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1, 1, 1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}