
库自增 ID
基于数据库的 ID 生成
sequence 单表方案
在单数据源情况下,基于原理 2 生成 id,此时数据库就是中心节点,所有序列号由中心节点派发;而在多数据源和单元化场景下,单元化是多数据源的特例,支持多数据源就能方便实现单元化支持。
这种情况下一个序列只存储于一张 sequence 表,使用 SequenceDao 进行表的读写。一张 sequence 表可以存储多个序列,不同的序列用名字(name)字段区分,所以一般而言一个应用一个 sequence 表就够了,甚至多个应用可以共享一张 sequence 表。通过这种单点数据源的方式,可以实现序列全局唯一,由于数据库知道目前派发出去的最大 id 号,后续的请求,只要在现在基础上递增即可。现在应用申请一个 id,需要用乐观锁(CAS)的方式更新序列的值,但是每个 id 都要乐观锁更新 db 实在太慢,因此为了加速 id 分配,一次 CAS 操作批量分配 id,分配 id 的数量就是 sequence 的内步长,默认的内步长是 1000,这样可以降低 1000 倍的数据库访问,不过有得必有失,这种方式生成的序列就不能保证全局有序了,并且在应用重启的时候,将会重新申请一段 id。sequence 所用的数据库表结构如下:
-- ----------------------------
-- Table structure for `sequence`
-- ----------------------------
DROP TABLE IF EXISTS `sequence`;
CREATE TABLE `sequence` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Id',
`name` varchar(64) NOT NULL COMMENT 'sequence name',
`value` bigint(20) NOT NULL COMMENT 'sequence current value',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NULL DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='sequence'
;
sequence 表的核心字段就两个:name 和 value,name 就是当前序列的名称,value 就是当前 sequence 已经分配出去的 id 最大值。多数据源的场景除了能够自适应后面的单元化场景之外,还可以避免单点故障,即一个 sequence 表不可用情况下,sequence 能够用其他数据源继续提供 id 生成服务。
即为每个数据源分配一个序号,数据源根据自己的序号在序列空间中独占一组序列号,原理如下图:

水平扩展
单台机器自然存在可用性问题,最简单的方式就是考虑将其扩展到多台机器,在前文的 sequence 单表方案中,我们是基于单表的自增;在分布式情况下,我们可以通过设置不同数据库的 auto_increment_increment 以及 auto_increment_offset 来不同的自增规则:
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;

在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长 step 为 2,TicketServer1 的初始值为 1(1,3,5,7,9,11…)、TicketServer2 的初始值为 2(2,4,6,8,10…)。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1 从 1 开始发号,TicketServer2 从 2 开始发号,两台机器每次发号之后都递增 2:
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1
TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2
假设我们要部署 N 台机器,步长需设置为 N,每台的初始值依次为 0,1,2…N-1 那么整个架构就变成了如下图所示:
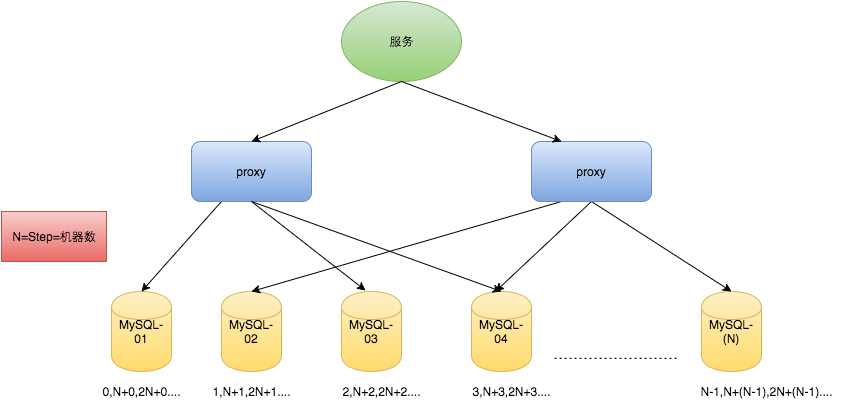
不过这种方式也存在问题,系统水平扩展比较困难,比如定义好了步长和机器台数之后,很难进行增删。ID 没有了单调递增的特性,只能趋势递增,并且数据库压力还是很大,每次获取 ID 都得读写一次数据库,只能靠堆机器来提高性能。