
机器学习面试题
参考答案请查阅《MachineLearning-Notes》
Supervised machine learning
What is supervised machine learning? 👶
A case when we have both features (the matrix X) and the labels (the vector y)
Linear regression
What is regression? Which models can you use to solve a regression problem? 👶
Regression is a part of supervised ML. Regression models investigate the relationship between a dependent (target) and independent variable (s) (predictor). Here are some common regression models:
- Linear Regression establishes a linear relationship between target and predictor (s). It predicts a numeric value and has a shape of a straight line.
- Logistic Regression solves classification problem when target is categorical. It searches for the probability of an event, predicts a value from 0 to 1.
- Polynomial Regression has a regression equation with the power of independent variable more than 1. It is a curve that fits into the data points.
- Ridge Regression helps when predictors are highly correlated (multicollinearity problem). It penalizes the squares of regression coefficients but doesn’t allow to reach zeros (uses l2 regularization).
- Lasso Regression penalizes the absolute values of regression coefficients and allow reach absolute zero for some coefficient (allow feature selection).
What is linear regression? When do we use it? 👶
Linear regression is a model that assumes a linear relationship between the input variables (X) and the single output variable (y).
With a simple equation:
y = B0 + B1*x1 + ... + Bn * xN
B is regression coefficients, x values are the independent (explanatory) variables and y is dependent variable.
The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is called multiple linear regression.
Simple linear regression:
y = B0 + B1*x1
Multiple linear regression:
y = B0 + B1*x1 + ... + Bn * xN
What’s the normal distribution? Why do we care about it? 👶
The normal distribution is a continuous probability distribution whose probability density function takes the following formula:
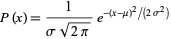
where μ is the mean and σ is the standard deviation of the distribution.
The normal distribution derives its importance from the Central Limit Theorem, which states that if we draw a large enough number of samples, their mean will follow a normal distribution regardless of the initial distribution of the sample, i.e the distribution of the mean of the samples is normal. It is important that each sample is independent from the other.
This is powerful because it helps us study processes whose population distribution is unknown to us.
How do we check if a variable follows the normal distribution? ⭐️
- Plot a histogram out of the sampled data. If you can fit the bell-shaped “normal” curve to the histogram, then the hypothesis that the underlying random variable follows the normal distribution can not be rejected.
- Check Skewness and Kurtosis of the sampled data. Zero-skewness and zero-kurtosis are typical for a normal distribution, so the farther away from 0, the more non-normal the distribution.
- Use Kolmogorov-Smirnov or/and Shapiro-Wilk tests for normality. They take into account both Skewness and Kurtosis simultaneously.
- Check for Quantile-Quantile plot. It is a scatterplot created by plotting two sets of quantiles against one another. Normal Q-Q plot place the data points in a roughly straight line.
What if we want to build a model for predicting prices? Are prices distributed normally? Do we need to do any pre-processing for prices? ⭐️
Answer here
What are the methods for solving linear regression do you know? ⭐️
Answer here
What is gradient descent? How does it work? ⭐️
Gradient descent is an algorithm that uses calculus concept of gradient to try and reach local or global minima. It works by taking the negative of the gradient in a point of a given function, and updating that point repeatedly using the calculated negative gradient, until the algorithm reaches a local or global minimum, which will cause future iterations of the algorithm to return values that are equal or too close to the current point. It is widely used in machine learning applications.
What is the normal equation? ⭐️
Normal equations are equations obtained by setting equal to zero the partial derivatives of the sum of squared errors (least squares); normal equations allow one to estimate the parameters of a multiple linear regression.
What is SGD — stochastic gradient descent? What’s the difference with the usual gradient descent? ⭐️
Answer here
Which metrics for evaluating regression models do you know? 👶
Answer here
What are MSE and RMSE? 👶
MSE stands for Mean Square Error while RMSE stands for Root Mean Square Error. They are metrics with which we can evaluate models.
Validation
What is overfitting? 👶
When your model perform very well on your training set but can’t generalize the test set, because it adjusted a lot to the training set.
How to validate your models? 👶
Answer here
Why do we need to split our data into three parts: train, validation, and test? 👶
The training set is used to fit the model, i.e. to train the model with the data. The validation set is then used to provide an unbiased evaluation of a model while fine-tuning hyperparameters. This improves the generalization of the model. Finally, a test data set which the model has never “seen” before should be used for the final evaluation of the model. This allows for an unbiased evaluation of the model. The evaluation should never be performed on the same data that is used for training. Otherwise the model performance would not be representative.
Can you explain how cross-validation works? 👶
Cross-validation is the process to separate your total training set into two subsets: training and validation set, and evaluate your model to choose the hyperparameters. But you do this process iteratively, selecting differents training and validation set, in order to reduce the bias that you would have by selecting only one validation set.
What is K-fold cross-validation? 👶
Answer here
How do we choose K in K-fold cross-validation? What’s your favorite K? 👶
Answer here
Classification
What is classification? Which models would you use to solve a classification problem? 👶
Classification problems are problems in which our prediction space is discrete, i.e. there is a finite number of values the output variable can be. Some models which can be used to solve classification problems are: logistic regression, decision tree, random forests, multi-layer perceptron, one-vs-all, amongst others.
What is logistic regression? When do we need to use it? 👶
Answer here
Is logistic regression a linear model? Why? 👶
Answer here
What is sigmoid? What does it do? 👶
Answer here
How do we evaluate classification models? 👶
Answer here
What is accuracy? 👶
Accuracy is a metric for evaluating classification models. It is calculated by dividing the number of correct predictions by the number of total predictions.
Is accuracy always a good metric? 👶
Accuracy is not a good performance metric when there is imbalance in the dataset. For example, in binary classification with 95% of A class and 5% of B class, prediction accuracy can be 95%. In case of imbalance dataset, we need to choose Precision, recall, or F1 Score depending on the problem we are trying to solve.
What is the confusion table? What are the cells in this table? 👶
Confusion table (or confusion matrix) shows how many True positives (TP), True Negative (TN), False Positive (FP) and False Negative (FN) model has made.
| Actual | Actual | ||
|---|---|---|---|
| Positive (1) | Negative (0) | ||
| Predicted | Positive (1) | TP | FP |
| Predicted | Negative (0) | FN | TN |
- True Positives (TP): When the actual class of the observation is 1 (True) and the prediction is 1 (True)
- True Negative (TN): When the actual class of the observation is 0 (False) and the prediction is 0 (False)
- False Positive (FP): When the actual class of the observation is 0 (False) and the prediction is 1 (True)
- False Negative (FN): When the actual class of the observation is 1 (True) and the prediction is 0 (False)
Most of the performance metrics for classification models are based on the values of the confusion matrix.
What are precision, recall, and F1-score? 👶
- Precision and recall are classification evaluation metrics:
- P = TP / (TP + FP) and R = TP / (TP + FN).
- Where TP is true positives, FP is false positives and FN is false negatives
- In both cases the score of 1 is the best: we get no false positives or false negatives and only true positives.
- F1 is a combination of both precision and recall in one score:
- F1 = 2 * PR / (P + R).
- Max F score is 1 and min is 0, with 1 being the best.
Precision-recall trade-off ⭐️
Answer here
What is the ROC curve? When to use it? ⭐️
Answer here
What is AUC (AU ROC)? When to use it? ⭐️
Answer here
How to interpret the AU ROC score? ⭐️
Answer here
What is the PR (precision-recall) curve? ⭐️
Answer here
What is the area under the PR curve? Is it a useful metric? ⭐️I
Answer here
In which cases AU PR is better than AU ROC? ⭐️
Answer here
What do we do with categorical variables? ⭐️
Answer here
Why do we need one-hot encoding? ⭐️
Answer here
Regularization
What happens to our linear regression model if we have three columns in our data: x, y, z — and z is a sum of x and y? ⭐️
Answer here
What happens to our linear regression model if the column z in the data is a sum of columns x and y and some random noise? ⭐️
Answer here
What is regularization? Why do we need it? 👶
Answer here
Which regularization techniques do you know? ⭐️
Answer here
What kind of regularization techniques are applicable to linear models? ⭐️
Answer here
How does L2 regularization look like in a linear model? ⭐️
Answer here
How do we select the right regularization parameters? 👶
Answer here
What’s the effect of L2 regularization on the weights of a linear model? ⭐️
Answer here
How L1 regularization looks like in a linear model? ⭐️
Answer here
What’s the difference between L2 and L1 regularization? ⭐️
Answer here
Can we have both L1 and L2 regularization components in a linear model? ⭐️
Answer here
What’s the interpretation of the bias term in linear models? ⭐️
Answer here
How do we interpret weights in linear models? ⭐️
If the variables are normalized, we can interpret weights in linear models like the importance of this variable in the predicted result.
If a weight for one variable is higher than for another — can we say that this variable is more important? ⭐️
Answer here
When do we need to perform feature normalization for linear models? When it’s okay not to do it? ⭐️
Answer here
Feature selection
What is feature selection? Why do we need it? 👶
Answer here
Is feature selection important for linear models? ⭐️
Answer here
Which feature selection techniques do you know? ⭐️
Answer here
Can we use L1 regularization for feature selection? ⭐️
Answer here
Can we use L2 regularization for feature selection? ⭐️
Answer here
Decision trees
What are the decision trees? 👶
Answer here
How do we train decision trees? ⭐️
Answer here
What are the main parameters of the decision tree model? 👶
Answer here
How do we handle categorical variables in decision trees? ⭐️
Answer here
What are the benefits of a single decision tree compared to more complex models? ⭐️
Answer here
How can we know which features are more important for the decision tree model? ⭐️
Answer here
Random forest
What is random forest? 👶
Answer here
Why do we need randomization in random forest? ⭐️
Answer here
What are the main parameters of the random forest model? ⭐️
Answer here
How do we select the depth of the trees in random forest? ⭐️
Answer here
How do we know how many trees we need in random forest? ⭐️
Answer here
Is it easy to parallelize training of a random forest model? How can we do it? ⭐️
Answer here
What are the potential problems with many large trees? ⭐️
Answer here
What if instead of finding the best split, we randomly select a few splits and just select the best from them. Will it work? 🚀
Answer here
What happens when we have correlated features in our data? ⭐️
Answer here
Gradient boosting
What is gradient boosting trees? ⭐️
Answer here
What’s the difference between random forest and gradient boosting? ⭐️
Answer here
Is it possible to parallelize training of a gradient boosting model? How to do it? ⭐️
Answer here
Feature importance in gradient boosting trees — what are possible options? ⭐️
Answer here
Are there any differences between continuous and discrete variables when it comes to feature importance of gradient boosting models? 🚀
Answer here
What are the main parameters in the gradient boosting model? ⭐️
Answer here
How do you approach tuning parameters in XGBoost or LightGBM? 🚀
Answer here
How do you select the number of trees in the gradient boosting model? ⭐️
Answer here
Parameter tuning
Which parameter tuning strategies (in general) do you know? ⭐️
Answer here
What’s the difference between grid search parameter tuning strategy and random search? When to use one or another? ⭐️
Answer here
Neural networks
What kind of problems neural nets can solve? 👶
Answer here
How does a usual fully-connected feed-forward neural network work? ⭐️
Answer here
Why do we need activation functions? 👶
Answer here
What are the problems with sigmoid as an activation function? ⭐️
Answer here
What is ReLU? How is it better than sigmoid or tanh? ⭐️
Answer here
How we can initialize the weights of a neural network? ⭐️
Answer here
What if we set all the weights of a neural network to 0? ⭐️
Answer here
What regularization techniques for neural nets do you know? ⭐️
Answer here
What is dropout? Why is it useful? How does it work? ⭐️
Answer here
Optimization in neural networks
What is backpropagation? How does it work? Why do we need it? ⭐️
Answer here
Which optimization techniques for training neural nets do you know? ⭐️
Answer here
How do we use SGD (stochastic gradient descent) for training a neural net? ⭐️
Answer here
What’s the learning rate? 👶
The learning rate is an important hyperparameter that controls how quickly the model is adapted to the problem during the training. It can be seen as the “step width” during the parameter updates, i.e. how far the weights are moved into the direction of the minimum of our optimization problem.
What happens when the learning rate is too large? Too small? 👶
A large learning rate can accelerate the training. However, it is possible that we “shoot” too far and miss the minimum of the function that we want to optimize, which will not result in the best solution. On the other hand, training with a small learning rate takes more time but it is possible to find a more precise minimum. The downside can be that the solution is stuck in a local minimum, and the weights won’t update even if it is not the best possible global solution.
How to set the learning rate? ⭐️
Answer here
What is Adam? What’s the main difference between Adam and SGD? ⭐️
Answer here
When would you use Adam and when SGD? ⭐️
Answer here
Do we want to have a constant learning rate or we better change it throughout training? ⭐️
Answer here
How do we decide when to stop training a neural net? 👶
Answer here
What is model checkpointing? ⭐️
Answer here
Can you tell us how you approach the model training process? ⭐️
Answer here
Neural networks for computer vision
How we can use neural nets for computer vision? ⭐️
Answer here
What’s a convolutional layer? ⭐️
Answer here
Why do we actually need convolutions? Can’t we use fully-connected layers for that? ⭐️
Answer here
What’s pooling in CNN? Why do we need it? ⭐️
Answer here
How does max pooling work? Are there other pooling techniques? ⭐️
Answer here
Are CNNs resistant to rotations? What happens to the predictions of a CNN if an image is rotated? 🚀
Answer here
What are augmentations? Why do we need them? 👶What kind of augmentations do you know? 👶How to choose which augmentations to use? ⭐️
Answer here
What kind of CNN architectures for classification do you know? 🚀
Answer here
What is transfer learning? How does it work? ⭐️
Answer here
What is object detection? Do you know any architectures for that? 🚀
Answer here
What is object segmentation? Do you know any architectures for that? 🚀
Answer here
Text classification
How can we use machine learning for text classification? ⭐️
Answer here
What is bag of words? How we can use it for text classification? ⭐️
Bag of Words is a representation of text that describes the occurrence of words within a document. The order or structure of the words is not considered. For text classification, we look at the histogram of the words within the text and consider each word count as a feature.
What are the advantages and disadvantages of bag of words? ⭐️
Advantages:
- Simple to understand and implement.
Disadvantages:
- The vocabulary requires careful design, most specifically in order to manage the size, which impacts the sparsity of the document representations.
- Sparse representations are harder to model both for computational reasons (space and time complexity) and also for information reasons
- Discarding word order ignores the context, and in turn meaning of words in the document. Context and meaning can offer a lot to the model, that if modeled could tell the difference between the same words differently arranged (“this is interesting” vs “is this interesting”), synonyms (“old bike” vs “used bike”).
What are N-grams? How can we use them? ⭐️
The function to tokenize into consecutive sequences of words is called n-grams. It can be used to find out N most co-occurring words (how often word X is followed by word Y) in a given sentence.
How large should be N for our bag of words when using N-grams? ⭐️
Answer here
What is TF-IDF? How is it useful for text classification? ⭐️
Term Frequency (TF) is a scoring of the frequency of the word in the current document. Inverse Document Frequency(IDF) is a scoring of how rare the word is across documents. It is used in scenario where highy recurring words may not contain as much informational content as the domain specific words. For example, words like “the” that are frequent across all documents therefore need to be less weighted. The Tf-IDF score highlights words that are distinct (contain useful information) in a given document.
Which model would you use for text classification with bag of words features? ⭐️
Answer here
Would you prefer gradient boosting trees model or logistic regression when doing text classification with bag of words? ⭐️
Answer here
What are word embeddings? Why are they useful? Do you know Word2Vec? ⭐️
Answer here
Do you know any other ways to get word embeddings? 🚀
Answer here
If you have a sentence with multiple words, you may need to combine multiple word embeddings into one. How would you do it? ⭐️
Answer here
Would you prefer gradient boosting trees model or logistic regression when doing text classification with embeddings? ⭐️
Answer here
How can you use neural nets for text classification? 🚀
Answer here
How can we use CNN for text classification? 🚀
Answer here
Clustering
What is unsupervised learning? 👶
Unsupervised learning aims to detect paterns in data where no labels are given.
What is clustering? When do we need it? 👶
Clustering algorithms group objects such that similar feature points are put into the same groups (clusters) and dissimilar feature points are put into different clusters.
Do you know how K-means works? ⭐️
- Partition points into k subsets.
- Compute the seed points as the new centroids of the clusters of the current partitioning.
- Assign each point to the cluster with the nearest seed point.
- Go back to step 2 or stop when the assignment does not change.
How to select K for K-means? ⭐️
- Domain knowledge, i.e. an expert knows the value of k
- Elbow method: compute the clusters for different values of k, for each k, calculate the total within-cluster sum of square, plot the sum according to the number of clusters and use the band as the number of clusters.
- Average silhouette method: compute the clusters for different values of k, for each k, calculate the average silhouette of observations, plot the silhouette according to the number of clusters and select the maximum as the number of clusters.
What are the other clustering algorithms do you know? ⭐️
- k-medoids: Takes the most central point instead of the mean value as the center of the cluster. This makes it more robust to noise.
- Agglomerative Hierarchical Clustering (AHC): hierarchical clusters combining the nearest clusters starting with each point as its own cluster.
- DIvisive ANAlysis Clustering (DIANA): hierarchical clustering starting with one cluster containing all points and splitting the clusters until each point describes its own cluster.
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN): Cluster defined as maximum set of density-connected points.
Do you know how DBScan works? ⭐️
- Two input parameters epsilon (neighborhood radius) and minPts (minimum number of points in an epsilon-neighborhood)
- Cluster defined as maximum set of density-connected points.
- Points p_j and p_i are density-connected w.r.t. epsilon and minPts if there is a point o such that both, i and j are density-reachable from o w.r.t. epsilon and minPts.
- p_j is density-reachable from p_i w.r.t. epsilon, minPts if there is a chain of points p_i -> p_i+1 -> p_i+x = p_j such that p_i+x is directly density-reachable from p_i+x-1.
- p_j is a directly density-reachable point of the neighborhood of p_i if dist(p_i,p_j) <= epsilon.
When would you choose K-means and when DBScan? ⭐️
- DBScan is more robust to noise.
- DBScan is better when the amount of clusters is difficult to guess.
- K-means has a lower complexity, i.e. it will be much faster, especially with a larger amount of points.
Dimensionality reduction
What is the curse of dimensionality? Why do we care about it? ⭐️
Data in only one dimension is relatively tightly packed. Adding a dimension stretches the points across that dimension, pushing them further apart. Additional dimensions spread the data even further making high dimensional data extremely sparse. We care about it, because it is difficult to use machine learning in sparse spaces.
Do you know any dimensionality reduction techniques? ⭐️
- Singular Value Decomposition (SVD)
- Principal Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
- T-distributed Stochastic Neighbor Embedding (t-SNE)
- Autoencoders
- Fourier and Wavelet Transforms
What’s singular value decomposition? How is it typically used for machine learning? ⭐️
- Singular Value Decomposition (SVD) is a general matrix decomposition method that factors a matrix X into three matrices L (left singular values), Σ (diagonal matrix) and R^T (right singular values).
- For machine learning, Principal Component Analysis (PCA) is typically used. It is a special type of SVD where the singular values correspond to the eigenvectors and the values of the diagonal matrix are the squares of the eigenvalues. We use these features as they are statistically descriptive.
- Having calculated the eigenvectors and eigenvalues, we can use the Kaiser-Guttman criterion, a scree plot or the proportion of explained variance to determine the principal components (i.e. the final dimensionality) that are useful for dimensionality reduction.
Ranking and search
What is the ranking problem? Which models can you use to solve them? ⭐️
Answer here
What are good unsupervised baselines for text information retrieval? ⭐️
Answer here
How would you evaluate your ranking algorithms? Which offline metrics would you use? ⭐️
Answer here
What is precision and recall at k? ⭐️
Answer here
What is mean average precision at k? ⭐️
Answer here
How can we use machine learning for search? ⭐️
Answer here
How can we get training data for our ranking algorithms? ⭐️
Answer here
Can we formulate the search problem as a classification problem? How? ⭐️
Answer here
How can we use clicks data as the training data for ranking algorithms? 🚀
Answer here
Do you know how to use gradient boosting trees for ranking? 🚀
Answer here
How do you do an online evaluation of a new ranking algorithm? ⭐️
Answer here
Recommender systems
What is a recommender system? 👶
Recommender systems are software tools and techniques that provide suggestions for items that are most likely of interest to a particular user.
What are good baselines when building a recommender system? ⭐️
- A good recommer system should give relevant and personalized information.
- It should not recommend items the user knows well or finds easily.
- It should make diverse suggestions.
- A user should explore new items.
What is collaborative filtering? ⭐️
- Collaborative filtering is the most prominent approach to generate recommendations.
- It uses the wisdom of the crowd, i.e. it gives recommendations based on the experience of others.
- A recommendation is calculated as the average of other experiences.
- Say we want to give a score that indicates how much user u will like an item i. Then we can calculate it with the experience of N other users U as r_ui = 1/N * sum(v in U) r_vi.
- In order to rate similar experiences with a higher weight, we can introduce a similarity between users that we use as a multiplier for each rating.
- Also, as users have an individual profile, one user may have an average rating much larger than another user, so we use normalization techniques (e.g. centering or Z-score normalization) to remove the users’ biases.
- Collaborative filtering does only need a rating matrix as input and improves over time. However, it does not work well on sparse data, does not work for cold starts (see below) and usually tends to overfit.
How we can incorporate implicit feedback (clicks, etc) into our recommender systems? ⭐️
In comparison to explicit feedback, implicit feedback datasets lack negative examples. For example, explicit feedback can be a positive or a negative rating, but implicit feedback may be the number of purchases or clicks. One popular approach to solve this problem is named weighted alternating least squares (wALS) [Hu, Y., Koren, Y., & Volinsky, C. (2008, December). Collaborative filtering for implicit feedback datasets. In Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on (pp. 263-272). IEEE.]. Instead of modeling the rating matrix directly, the numbers (e.g. amount of clicks) describe the strength in observations of user actions. The model tries to find latent factors that can be used to predict the expected preference of a user for an item.
What is the cold start problem? ⭐️
Collaborative filterung incorporates crowd knowledge to give recommendations for certain items. Say we want to recommend how much a user will like an item, we then will calculate the score using the recommendations of other users for this certain item. We can distinguish between two different ways of a cold start problem now. First, if there is a new item that has not been rated yet, we cannot give any recommendation. Also, when there is a new user, we cannot calculate a similarity to any other user.
Possible approaches to solving the cold start problem? ⭐️🚀
- Content-based filtering incorporates features about items to calculate a similarity between them. In this way, we can recommend items that have a high similarity to items that a user liked already. In this way, we are not dependant on the ratings of other users for a given item anymore and solve the cold start problem for new items.
- Demographic filtering incorporates user profiles to calculate a similarity between them and solves the cold start problem for new users.
Time series
What is a time series? 👶
A time series is a set of observations ordered in time usually collected at regular intervals.
How is time series different from the usual regression problem? 👶
The principle behind causal forecasting is that the value that has to be predicted is dependant on the input features (causal factors). In time series forecasting, the to be predicted value is expected to follow a certain pattern over time.
Which models do you know for solving time series problems? ⭐️
- Simple Exponential Smoothing: approximate the time series with an exponentional function
- Trend-Corrected Exponential Smoothing (Holt‘s Method): exponential smoothing that also models the trend
- Trend- and Seasonality-Corrected Exponential Smoothing (Holt-Winter‘s Method): exponential smoothing that also models trend and seasonality
- Time Series Decomposition: decomposed a time series into the four components trend, seasonal variation, cycling varation and irregular component
- Autoregressive models: similar to multiple linear regression, except that the dependent variable y_t depends on its own previous values rather than other independent variables.
- Deep learning approaches (RNN, LSTM, etc.)
If there’s a trend in our series, how we can remove it? And why would we want to do it? ⭐️
We can explicitly model the trend (and/or seasonality) with approaches such as Holt’s Method or Holt-Winter’s Method. We want to explicitly model the trend to reach the stationarity property for the data. Many time series approaches require stationarity. Without stationarity,the interpretation of the results of these analyses is problematic [Manuca, Radu & Savit, Robert. (1996). Stationarity and nonstationarity in time series analysis. Physica D: Nonlinear Phenomena. 99. 134-161. 10.1016/S0167-2789(96)00139-X. ].
You have a series with only one variable “y” measured at time t. How do predict “y” at time t+1? Which approaches would you use? ⭐️
We want to look at the correlation between different observations of y. This measure of correlation is called autocorrelation. Autoregressive models are multiple regression models where the time-lag series of the original time series are treated like multiple independent variables.
You have a series with a variable “y” and a set of features. How do you predict “y” at t+1? Which approaches would you use? ⭐️
Given the assumption that the set of features gives a meaningful causation to y, a causal forecasting approach such as linear regression or multiple nonlinear regression might be useful. In case there is a lot of data and the explanability of the results is not a high priority, we can also consider deep learning approaches.
What are the problems with using trees for solving time series problems? ⭐️
Answer here