
领域对象
领域对象
MartinFowler 曾经提出贫血模型与充血模型的概念,他认为我们大多数系统以 POJO 作为模型,只有普通的 getter、setter 方法,没有真正的行为,好像缺少血液的人;而在 Evans 看来,DDD 中模型都是以充血形式存在,也就是说在 DDD 中,我们设计的模型不仅包含描述业务属性,还要包含能够描述动作的方法,不同的是,领域中一些概念不能用在模型对象,如仓储、工厂、服务等,如强加于模型中,将破坏模型的定义。领域建模是通过识别领域对象与行为来连接与现实世界业务主体与操作的映射关系。对象与行为的组织设计原则更体现面向对象设计的思想,通过聚合、解耦、抽象、组合等多种设计方式达到系统可复用,可维护,易扩展的能力。所谓的领域对象可能会分为以下几个概念:
- 失血模型:是仅包含属性的 getter/setter 方法的数据载体,没有行为和动作,业务逻辑由服务层完成。
- 贫血模型:包括了属性、getter/setter 方法,和不依赖于持久化的原子领域逻辑,依赖于持久层的业务逻辑将会放到服务层中。
- 充血模型:包含了属性、getter/setter 方法、大部分的业务逻辑,包括依赖于持久层的业务逻辑,所以使用充血模型的领域层是依赖于持久层,服务层是很薄的一层,仅仅封装事务和少量逻辑。
- 胀血模型:取消了 Service 层,胀血模型就是把和业务逻辑不相关的其他应用逻辑(如授权、事务等)都放到领域模型中。
胀血模型是显而易见不可取的,这里不做过多讨论。失血模型是绝大数企业开发应用的模式,一些火热的 ORM 工具比如 Hibernate,Entity Framework 实际上助长了失血模型的扩散,而且传统三层架构中的服务层,承受了太多的职责,如事务管理、业务逻辑、权限检查等,这违反了单一职责原则和关注分离原则,并且产生了大量的依赖和循环依赖,当业务复杂度上升时,服务层所包含的代码将会非常庞大和复杂,直接导致了维护成本和测试成本的上升。同时也会导致业务逻辑、状态会散落到在大量方法中,原本的代码意图会渐渐不明确,我们将这种情况称为由失血症引起的失忆症,它会导致系统变得愈发复杂和难以维护。
采用领域模型的开发方式,将数据和业务逻辑封装在一起,从服务层移动到领域将业务逻辑模型中,这样服务层可以只负责应用逻辑(事务、日志、认证、监控、编排等),领域模型可以专门负责其相关的业务逻辑,相关的业务分别内聚到不同的领域模型中,与现实领域的业务对象映射,一些很有可能重复的业务代码都会被集中到一处,降低重复代码,提升业务逻辑的复用、可测试性和维护性。贫血模型和充血模型都是满足数据+行为的,应该采用哪种模式,大家这是一个争论了旷日持久的问题,关注点还是在于领域模型是否要依赖持久层,我个人还是偏重于贫血模式,依赖持久层就意味着单元测试的展开要更加困难,而且领域对象的生命周期应该交给外部模型才更合理。
Entity(实体)
每个实体是具有唯一标识的领域概念,并且可以相当长的一段时间内持续地变化。例如实体订单 Order,标识为 oderId,活动实体 Activity,标识为 activityId,客户实体 Customer,标识为 customerId。假设每个客户都有一个或者多个收货地址(包括国家、省、市、村、楼号、单元)等等,作为客户实体的一部分携带的业务属性,可以进一步提取为地址值对象,一对多关联,用以保证最关键的业务含义在实体身上,控制每个领域对象的粒度最小,避免属性过多导致模型混乱,结构不清晰。
我们可以对实体做多次修改,故一个实体对象可能和它先前的状态大不相同。但是,由于它们拥有相同的身份标识,他们依然是同一个实体。并且标识符在历经各种状态变更后仍能保持一致。对这些对象而言,重要的不是其属性,而是其延续性和标识,对象的延续性和标识会跨越甚至超出软件的生命周期。
实体的业务形态
在 DDD 不同的设计过程中,实体的形态是不同的。在战略设计时,实体是领域模型的一个重要对象。领域模型中的实体是多个属性、操作或行为的载体。在事件风暴中,我们可以根据命令、操作或者事件,找出产生这些行为的业务实体对象,进而按照一定的业务规则将依存度高和业务关联紧密的多个实体对象和值对象进行聚类,形成聚合。你可以这么理解,实体和值对象是组成领域模型的基础单元。
实体的代码形态
在代码模型中,实体的表现形式是实体类,这个类包含了实体的属性和方法,通过这些方法实现实体自身的业务逻辑。在 DDD 里,这些实体类通常采用充血模型,与这个实体相关的所有业务逻辑都在实体类的方法中实现,跨多个实体的领域逻辑则在领域服务中实现。
实体的运行形态
实体以 DO(领域对象)的形式存在,每个实体对象都有唯一的 ID。我们可以对一个实体对象进行多次修改,修改后的数据和原来的数据可能会大不相同。但是,由于它们拥有相同的 ID,它们依然是同一个实体。比如商品是商品上下文的一个实体,通过唯一的商品 ID 来标识,不管这个商品的数据如何变化,商品的 ID 一直保持不变,它始终是同一个商品。
实体的数据库形态
与传统数据模型设计优先不同,DDD 是先构建领域模型,针对实际业务场景构建实体对象和行为,再将实体对象映射到数据持久化对象。在领域模型映射到数据模型时,一个实体可能对应 0 个、1 个或者多个数据库持久化对象。大多数情况下实体与持久化对象是一对一。在某些场景中,有些实体只是暂驻静态内存的一个运行态实体,它不需要持久化。比如,基于多个价格配置数据计算后生成的折扣实体。而在有些复杂场景下,实体与持久化对象则可能是一对多或者多对一的关系。比如,用户 user 与角色 role 两个持久化对象可生成权限实体,一个实体对应两个持久化对象,这是一对多的场景。再比如,有些场景为了避免数据库的联表查询,提升系统性能,会将客户信息 customer 和账户信息 account 两类数据保存到同一张数据库表中,客户和账户两个实体可根据需要从一个持久化对象中生成,这就是多对一的场景。
ValueObject(值对象)
所谓值对象,就是通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体;当我们只关心一个模型元素的属性时,在 DDD 中用来描述领域的特定方面,并且是一个没有标识符的对象,应把它归类为值对象。实体与 VO 的区别在于唯一的身份标识和可变性。当一个对象用于描述一个事物,但是又没有唯一标示,那么它就是一个 VO。例如商品中的商品类别,类别就没有一个唯一标识,通过图书、服装等这些值就能明确表示这个商品类别。VO 一般是不影响实际业务开展的,可共享的,没有唯一标识的 POJO 对象。在传统三层模式中,VO 往往用以作为界面展示的信息载体,在 DDD 中虽然编写方式一致,但是在这里仍是具有一定业务语义,是领域模型的一部分,而不是被表现层某页面绑架的临时对象。
建议将值对象设计成一个不变(Immutable)对象,当度量和描述改变时,可以用另外一个值对象予以替换。它可以和其它值对象进行相等性比较,且不会对协作对象造成副作用,也避免了并发带来的冲突等问题。在领域驱动设计中,提倡尽量定义值对象来替代基本类型,因为基本类型无法体现统一语言中的领域概念。假设一个实体定义了许多属性,这些属性都是基本类型,就会导致与这些属性相关的领域行为都要放到实体中,导致实体的职责变得不够单一。引入值对象后情况就不同了,我们可以利用合理的职责分配,将这些职责(领域行为)按照内聚性分配到各个值对象中,这个领域模型就能变得协作良好。值对象可以与其所在的实体对象保存在同一张表中,值对象的每一个属性保存为一列;值对象也可以独立于其所在的实体对象保存在另一张表中,值对象获得委派主键,该主键对客户端是不可见的。
值对象的业务形态
值对象是 DDD 领域模型中的一个基础对象,它跟实体一样都来源于事件风暴所构建的领域模型,都包含了若干个属性,它与实体一起构成聚合。我们不妨对照实体,来看值对象的业务形态,这样更好理解。本质上,实体是看得到、摸得着的实实在在的业务对象,实体具有业务属性、业务行为和业务逻辑。而值对象只是若干个属性的集合,只有数据初始化操作和有限的不涉及修改数据的行为,基本不包含业务逻辑。值对象的属性集虽然在物理上独立出来了,但在逻辑上它仍然是实体属性的一部分,用于描述实体的特征。
在值对象中也有部分共享的标准类型的值对象,它们有自己的限界上下文,有自己的持久化对象,可以建立共享的数据类微服务,比如数据字典。
值对象的代码形态
值对象在代码中有这样两种形态。如果值对象是单一属性,则直接定义为实体类的属性;如果值对象是属性集合,则把它设计为 Class 类,Class 将具有整体概念的多个属性归集到属性集合,这样的值对象没有 ID,会被实体整体引用。我们看一下下面这段代码,person 这个实体有若干个单一属性的值对象,比如 Id、name 等属性;同时它也包含多个属性的值对象,比如地址 address。

值对象的运行形态
实体实例化后的 DO 对象的业务属性和业务行为非常丰富,但值对象实例化的对象则相对简单和乏味。除了值对象数据初始化和整体替换的行为外,其它业务行为就很少了。值对象嵌入到实体的话,有这样两种不同的数据格式,也可以说是两种方式,分别是属性嵌入的方式和序列化大对象的方式。
引用单一属性的值对象或只有一条记录的多属性值对象的实体,可以采用属性嵌入的方式嵌入。引用一条或多条记录的多属性值对象的实体,可以采用序列化大对象的方式嵌入。比如,人员实体可以有多个通讯地址,多个地址序列化后可以嵌入人员的地址属性。值对象创建后就不允许修改了,只能用另外一个值对象来整体替换。
- 以属性嵌入的方式形成的人员实体对象,地址值对象直接以属性值嵌入人员实体中。

- 以序列化大对象的方式形成的人员实体对象,地址值对象被序列化成大对象 Json 串后,嵌入人员实体中。
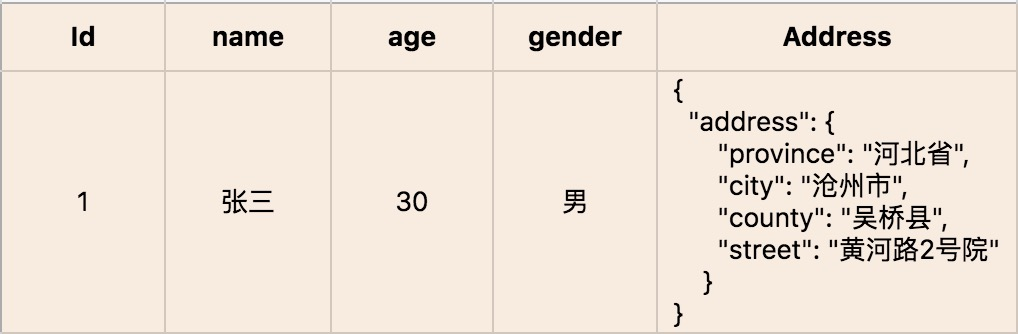
值对象的数据库形态
DDD 引入值对象是希望实现从“数据建模为中心”向“领域建模为中心”转变,减少数据库表的数量和表与表之间复杂的依赖关系,尽可能地简化数据库设计,提升数据库性能。如何理解用值对象来简化数据库设计呢?传统的数据建模大多是根据数据库范式设计的,每一个数据库表对应一个实体,每一个实体的属性值用单独的一列来存储,一个实体主表会对应 N 个实体从表。而值对象在数据库持久化方面简化了设计,它的数据库设计大多采用非数据库范式,值对象的属性值和实体对象的属性值保存在同一个数据库实体表中。
举个例子,还是基于上述人员和地址那个场景,实体和数据模型设计通常有两种解决方案:第一是把地址值对象的所有属性都放到人员实体表中,创建人员实体,创建人员数据表;第二是创建人员和地址两个实体,同时创建人员和地址两张表。第一个方案会破坏地址的业务涵义和概念完整性,第二个方案增加了不必要的实体和表,需要处理多个实体和表的关系,从而增加了数据库设计的复杂性。
我们可以综合这两个方案的优势,扬长避短。在领域建模时,我们可以把地址作为值对象,人员作为实体,这样就可以保留地址的业务涵义和概念完整性。而在数据建模时,我们可以将地址的属性值嵌入人员实体数据库表中,只创建人员数据库表。这样既可以兼顾业务含义和表达,又不增加数据库的复杂度。
值对象就是通过这种方式,简化了数据库设计,总结一下就是:在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。另外,也有 DDD 专家认为,要想发挥对象的威力,就需要优先做领域建模,弱化数据库的作用,只把数据库作为一个保存数据的仓库即可。即使违反数据库设计原则,也不用大惊小怪,只要业务能够顺利运行,就没什么关系。
实体与值对象的关系
值对象是一把双刃剑,它的优势是可以简化数据库设计,提升数据库性能。但如果值对象使用不当,它的优势就会很快变成劣势。“知彼知己,方能百战不殆”,你需要理解值对象真正适合的场景。值对象采用序列化大对象的方法简化了数据库设计,减少了实体表的数量,可以简单、清晰地表达业务概念。这种设计方式虽然降低了数据库设计的复杂度,但却无法满足基于值对象的快速查询,会导致搜索值对象属性值变得异常困难。
值对象采用属性嵌入的方法提升了数据库的性能,但如果实体引用的值对象过多,则会导致实体堆积一堆缺乏概念完整性的属性,这样值对象就会失去业务涵义,操作起来也不方便。实体和值对象是微服务底层的最基础的对象,一起实现实体最基本的核心领域逻辑。值对象和实体在某些场景下可以互换,很多 DDD 专家在这些场景下,其实也很难判断到底将领域对象设计成实体还是值对象?可以说,值对象在某些场景下有很好的价值,但是并不是所有的场景都适合值对象。你需要根据团队的设计和开发习惯,以及上面的优势和局限分析,选择最适合的方法。
DDD 引入值对象还有一个重要的原因,就是到底领域建模优先还是数据建模优先?DDD 提倡从领域模型设计出发,而不是先设计数据模型。前面讲过了,传统的数据模型设计通常是一个表对应一个实体,一个主表关联多个从表,当实体表太多的时候就很容易陷入无穷无尽的复杂的数据库设计,领域模型就很容易被数据模型绑架。可以说,值对象的诞生,在一定程度上,和实体是互补的。
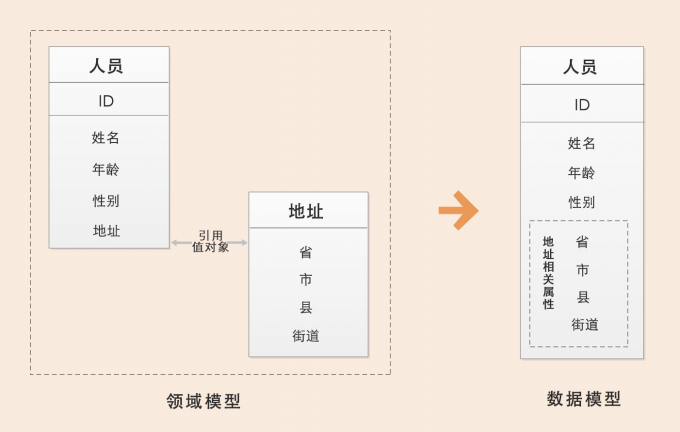
在领域模型中人员是实体,地址是值对象,地址值对象被人员实体引用。在数据模型设计时,地址值对象可以作为一个属性集整体嵌入人员实体中,组合形成上图这样的数据模型;也可以以序列化大对象的形式加入到人员的地址属性中,前面表格有展示。从这个例子中,我们可以看出,同样的对象在不同的场景下,可能会设计出不同的结果。有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护。
贫血模型与充血模型案例
贫血模型
此种模型下领域对象的作用很简单,只有所有属性的 get/set 方式,以及少量简单的属性值转换,不包含任何业务逻辑,不关系对象持久化,只是用来做为数据对象的承载和传递的介质。
@Entity
@Data
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class User {
@Id
private String userId;
private String userName;
private String password;
private boolean isLock;
}
而真正的业务逻辑则由领域服务负责实现,此服务引入持久化仓库,在业务逻辑完成之后持久化到仓库中,并在此可以发布领域事件(Domain Event)。
public interface UserService {
void create(User user);
void edit(User user);
void changePassword(String userId, String newPassword);
void lock(String userId);
void unlock(String userId);
}
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository repo;
@Override
public void edit(User user) {
User dbUser = repo.findById(user.getUserId()).get();
dbUser.setUserName(user.getUserName());
repo.save(dbUser);
// 发布领域事件 ...
}
@Override
public void lock(String userId) {
User dbUser = repo.findById(userId).get();
dbUser.setLock(true);
repo.save(dbUser);
// 发布领域事件 ...
}
// ... 省略完整代码
}
SpringBoot 采用单例模式,尽量不手动创建对象,对象无状态化,故较推荐使用贫血模型:
- 优点:结构简单,职责单一,相互隔离性好,使用单例模型提高运行性能
- 缺点:对象状态与行为分离,不能直观地描述领域对象。行为的设计主要考虑参数的输入和输出而非行为本身,不太具有面向对象设计的思考方式。行为间关联性较小,更像是面向过程式的方法,可复用性也较小。
充血模型
此种模型下领域对象作用此领域相关行为,包含此领域相关的业务逻辑,同时也包含对领域对象的持久化操作。
@Entity
@Data
@Builder
@AllArgsConstructor
public class User implements UserService {
@Id
private String userId;
private String userName;
private String password;
private boolean isLock;
// 持久化仓库
@Transient
private UserRepository repo;
// 是否是持久化对象
@Transient
private boolean isRepository;
@PostLoad
public void per() {
isRepository = true;
}
public User() {
}
public User(UserRepository repo) {
this.repo = repo;
}
@Override
public void create(User user) {
repo.save(user);
}
@Override
public void edit(User user) {
if (!isRepository) {
throw new RuntimeException("用户不存在");
}
userName = user.userName;
repo.save(this);
// 发布领域事件 ...
}
@Override
public void lock() {
if (!isRepository) {
throw new RuntimeException("用户不存在");
}
isLock = true;
repo.save(this);
// 发布领域事件 ...
}
}
在领域对象行为逻辑较复杂的情况下,需要多个行为共享对象状态的时候,充血模型表现力更强。
- 优点:对象自洽程度很高,表达能力很强,因此非常适合于复杂的企业业务逻辑的实现,以及可复用程度比较高,更符合面向对象设计思想
- 缺点:对象属性中掺杂持久化仓库,不够纯粹,持久化操作是否属于业务逻辑有待求证。但由于持久化仅需暴露接口,对业务逻辑与持久化操作的耦合度有一定降低。
无持久化充血模型
为了解决业务逻辑不纯粹问题,也有将持久化操作移出业务逻辑的作法。
@Entity
@Data
@Builder
@AllArgsConstructor
public class User implements UserService {
@Id
private String userId;
private String userName;
private String password;
private boolean isLock;
// 是否是持久化对象
@Transient
private boolean isRepository;
@Override
public void create(User user) {
user.userId = UUID.randomUUID().toString();
}
@Override
public void edit(User user) {
userName = user.userName;
}
@Override
public void lock() {
isLock = true;
}
}
@Service
public class UserManager {
@Autowired
private UserRepository repo;
public User findOne(String userId){
return repo.findById(userId).get();
}
public void edit(User u) {
User user = findOne(u.getUserId());
user.edit(u);
repo.save(user);
// 发布领域事件 ...
}
public void lock(String userId) {
User user = findOne(userId);
user.lock();
repo.save(user);
// 发布领域事件 ...
}
}
此种方式是前两种方式的折中,充分地做到了解耦,但也牺牲了部分内聚:
- 优点:保持了业务逻辑的纯粹性,去掉了持久化的入侵
- 缺点:降低了领域服务的自治性,破坏了行为逻辑的完整性,部分逻辑混入了 application 层,尤其是领域事件的发布