
02.星型与雪花模型
星型与雪花模型
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
星型模型
“星型模式”这个名字来源于这样一个事实,即当表关系可视化时,事实表在中间,由维表包围;与这些表的连接就像星星的光芒。
当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型。星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
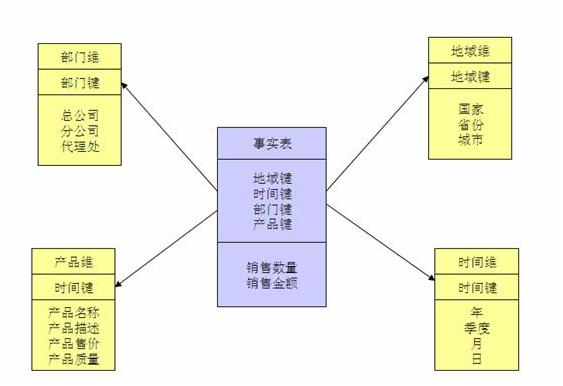
下例模式显示了可能在食品零售商处找到的数据仓库。在模式的中心是一个所谓的事实表(在这个例子中,它被称为 fact_sales)。事实表的每一行代表在特定时间发生的事件(这里,每一行代表客户购买的产品)。如果我们分析的是网站流量而不是零售量,则每行可能代表一个用户的页面浏览量或点击量。

通常情况下,事实被视为单独的事件,因为这样可以在以后分析中获得最大的灵活性。但是,这意味着事实表可以变得非常大。像苹果,沃尔玛或 eBay 这样的大企业在其数据仓库中可能有几十 PB 的交易历史,其中大部分实际上是表。
事实表中的一些列是属性,例如产品销售的价格和从供应商那里购买的成本(允许计算利润余额)。事实表中的其他列是对其他表(称为维表)的外键引用。由于事实表中的每一行都表示一个事件,因此这些维度代表事件的发生地点,时间,方式和原因。
例如上图中其中一个维度是已售出的产品 dim_product 表中的每一行代表一种待售产品,包括库存单位(SKU),说明,品牌名称,类别,脂肪含量,包装尺寸等。fact_sales 表中的每一行都使用外部表明在特定交易中销售了哪些产品。为了简单起见,如果客户一次购买几种不同的产品,则它们在事实表中被表示为单独的行
即使日期和时间通常使用维度表来表示,因为这允许对日期(诸如公共假期)的附加信息进行编码,从而允许查询区分假期和非假期的销售。
雪花模型
星型模型的变体被称为雪花模式,其中尺寸被进一步分解为子尺寸。例如,品牌和产品类别可能有单独的表格,并且 dim_product 表格中的每一行都可以将品牌和类别作为外键引用,而不是将它们作为字符串存储在 dim_product 表格中。雪花模式比星形模式更规范化,但是星形模式通常是首选,因为分析师使用它更简单。
在典型的数据仓库中,表格通常非常宽泛:事实表格通常有 100 列以上,有时甚至有数百列。维度表也可以是非常宽的,因为它们包括可能与分析相关的所有元数据——例如,dim_store 表可以包括在每个商店提供哪些服务的细节,它是否具有店内面包房,方形镜头,商店第一次开幕的日期,最后一次改造的时间,离最近的高速公路的距离等等。
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如下图,将地域维表又分解为国家,省份,城市等维表。它的优点是: 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
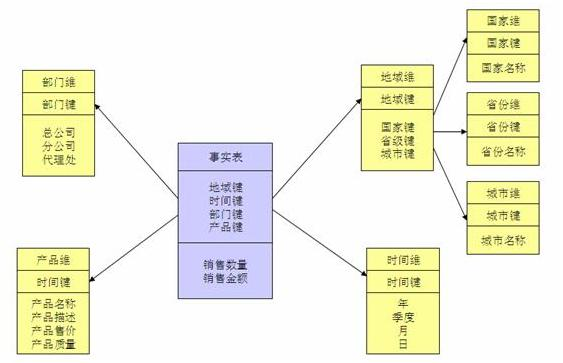
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
模型选择分析
雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”星形模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?”
数据优化
雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。相比较而言,星形模型实用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。
业务模型
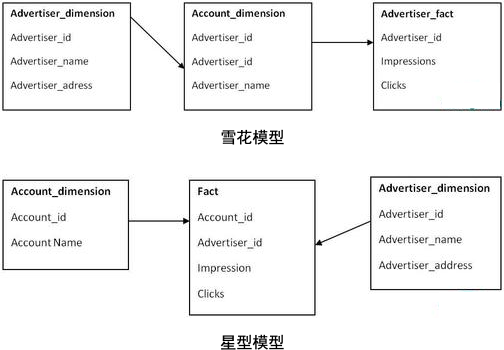
主键是一个单独的唯一键(数据属性),为特殊数据所选择。在上面的例子中,Advertiser_ID 就将是一个主键。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。在我们所引用的例子中,Advertiser_ID 将是 Account_dimension 的一个外键。
在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
性能
第三个区别在于性能的不同。雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道 Advertiser 的详细信息,雪花模型就会请求许多信息,比如 Advertiser Name、ID 以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。
而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将 Advertiser 的维度表和事实表连接即可。
ETL
雪花模型加载数据集市,因此 ETL 操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。星形模型加载维度表,不需要再维度之间添加附属模型,因此 ETL 就相对简单,而且可以实现高度的并行化。