
04.哈希索引
哈希索引
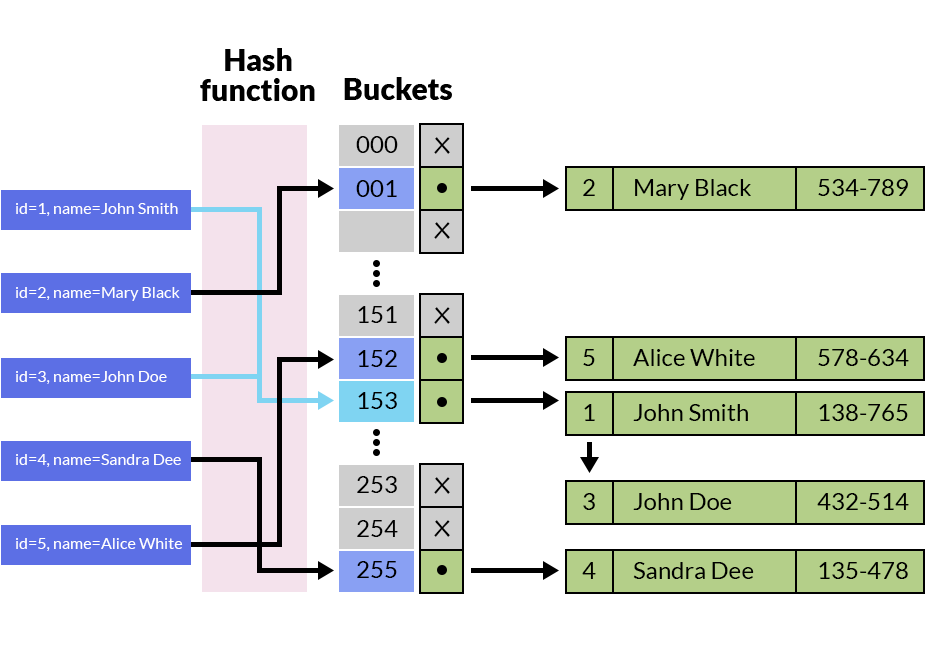
哈希索引即是基于哈希技术,如上图所示,我们将一系列的最终的键值通过哈希函数转化为存储实际数据桶的地址数值。值本身存储的地址就是基于哈希函数的计算结果,而搜索的过程就是利用哈希函数从元数据中推导出桶的地址。
- 添加新值的流程,首先会根据哈希函数计算出存储数据的地址,如果该地址已经被占用,则添加新桶并重新计算哈希函数。
- 更新值的流程则是先搜索到目标值的地址,然后对该内存地址应用所需的操作。
哈希索引的实现思路是,对一个字符串字段,为其每个值都计算一个哈希值,并且建立一个新字段用于存储这些哈希值,然后为这个新字段建立索引,并且为字符串字段建立插入和更新的触发器,用于更新哈希字段的值。在进行查询时,使用同一哈希算法计算查询的字符串的哈希值,使用该哈希值在哈希字段上进行查询,由于建立了索引,因而查询非常快,对于查询到的结果将查询的字符串与查询结果的字符串字段进行比较,从而得到最后的结果。这里由于新建立的哈希字段是整型的,因而其索引片非常小,并且由于字符串字段的选择性非常高,因而哈希字段的选择性相对非常高,因而总体而言,查询效率是非常高的。
哈希索引会在进行相等性测试(等或者不等)时候具有非常高的性能,但是在进行比较查询、Order By 等更为复杂的场景下就无能为力。
- 哈希索引仅仅能满足=,<=>,IN,IS NULL 或者 IS NOT NULL 查询,不能使用范围查询。由于哈希索引比较的是进行哈希运算之后的哈希值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的哈希算法处理之后的哈希值的大小关系,并不能保证和哈希运算前完全一样。
- 哈希索引无法被用来避免数据的排序操作。由于哈希索引中存放的是经过哈希计算之后的哈希值,而且哈希值的大小关系并不一定和哈希运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
- 哈希索引不能利用部分索引键查询。对于组合索引,哈希索引在计算哈希值的时候是组合索引键合并后再一起计算哈希值,而不是单独计算哈希值,所以通过组合索引的前面一个或几个索引键进行查询的时候,哈希索引也无法被利用。
- 哈希索引在任何时候都不能避免表扫描。前面已经知道,哈希索引是将索引键通过哈希运算之后,将哈希运算结果的哈希值和所对应的行指针信息存放于一个哈希表中,由于不同索引键存在相同哈希值,所以即使取满足某个哈希键值的数据的记录条数,也无法从 哈希索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
- 哈希索引遇到大量哈希值相等的情况后性能并不一定就会比 B-Tree 索引高。对于选择性比较低的索引键,如果创建哈希索引,那么将会存在大量记录指针信息存于同一个哈希值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
哈希索引
键值数据的结构相对简单,其索引也较为直观。键值存储与在大多数编程语言中可以找到的字典(dictionary)类型非常相似,通常字典都是用哈希映射(hash map)(或哈希表(hash table))实现的。既然我们已经有内存中数据结构-哈希映射,为什么不使用它来索引在磁盘上的数据呢?
内存索引
假设我们的数据存储只是一个追加写入的文件,就像前面的例子一样。那么最简单的索引策略就是:保留一个内存中的哈希映射,其中每个键都映射到一个数据文件中的字节偏移量,指明了可以找到对应值的位置,如下图所示。当你将新的键值对追加写入文件中时,还要更新哈希映射,以反映刚刚写入的数据的偏移量(这同时适用于插入新键与更新现有键)。当你想查找一个值时,使用哈希映射来查找数据文件中的偏移量,寻找(seek)该位置并读取该值。

现实中,Bitcask 实际上就是这么做的(Riak 中默认的存储引擎)Bitcask 提供高性能的读取和写入操作,但所有键必须能放入可用内存中,因为哈希映射完全保留在内存中。这些值可以使用比可用内存更多的空间,因为可以从磁盘上通过一次 seek 加载所需部分,如果数据文件的那部分已经在文件系统缓存中,则读取根本不需要任何磁盘 I/O。
像 Bitcask 这样的存储引擎非常适合每个键的值经常更新的情况。例如,键可能是视频的 URL,值可能是它播放的次数(每次有人点击播放按钮时递增)。在这种类型的工作负载中,有很多写操作,但是没有太多不同的键——每个键有很多的写操作,但是将所有键保存在内存中是可行的。
日志分段与压缩
直到现在,我们只是追加写入一个文件,所以如何避免最终用完磁盘空间?一种好的解决方案是,将日志分为特定大小的段,当日志增长到特定尺寸时关闭当前段文件,并开始写入一个新的段文件。然后,我们就可以对这些段进行压缩(compaction),如下图所示。压缩意味着在日志中丢弃重复的键,只保留每个键的最近更新。

而且,由于压缩经常会使得段变得很小(假设在一个段内键被平均重写了好几次),我们也可以在执行压缩的同时将多个段合并在一起,如下图所示。段被写入后永远不会被修改,所以合并的段被写入一个新的文件。冻结段的合并和压缩可以在后台线程中完成,在进行时,我们仍然可以继续使用旧的段文件来正常提供读写请求。合并过程完成后,我们将读取请求转换为使用新的合并段而不是旧段,然后可以简单地删除旧的段文件。

每个段现在都有自己的内存哈希表,将键映射到文件偏移量。为了找到一个键的值,我们首先检查最近段的哈希映射;如果键不存在,我们检查第二个最近的段,依此类推。合并过程保持细分的数量,所以查找不需要检查许多哈希映射大量的细节进入实践这个简单的想法工作。
其他挑战
-
文件格式:CSV 不是日志的最佳格式。使用二进制格式更快,更简单,首先以字节为单位对字符串的长度进行编码,然后使用原始字符串(不需要转义)。
-
删除记录:如果要删除一个键及其关联的值,则必须在数据文件(有时称为逻辑删除)中附加一个特殊的删除记录。当日志段被合并时,逻辑删除告诉合并过程放弃删除键的任何以前的值。
-
崩溃恢复:如果数据库重新启动,则内存哈希映射将丢失。原则上,您可以通过从头到尾读取整个段文件并在每次按键时注意每个键的最近值的偏移量来恢复每个段的哈希映射。但是,如果段文件很大,这可能需要很长时间,这将使服务器重新启动痛苦 Bitcask 通过存储加速恢复磁盘上每个段的哈希映射的快照,可以更快地加载到内存中。
-
部分写入记录:数据库可能随时崩溃,包括将记录附加到日志中途 Bitcask 文件包含校验和,允许检测和忽略日志的这些损坏部分。
并发控制
由于写操作是以严格顺序的顺序附加到日志中的,所以常见的实现选择是只有一个写入器线程。数据文件段是附加的,或者是不可变的,所以它们可以被多个线程同时读取。
为什么不更新文件,用新值覆盖旧值?但是只能追加设计的原因有几个:
- 追加和分段合并是顺序写入操作,通常比随机写入快得多,尤其是在磁盘旋转硬盘上。在某种程度上,顺序写入在基于闪存的 固态硬盘(SSD) 上也是优选的。
- 如果段文件是附加的或不可变的,并发和崩溃恢复就简单多了。例如,您不必担心在覆盖值时发生崩溃的情况,而将包含旧值和新值的一部分的文件保留在一起。
- 合并旧段可以避免数据文件随着时间的推移而分散的问题。
但是,哈希表索引也有局限性:
-
哈希表必须能放进内存:如果你有非常多的键,那真是倒霉。原则上可以在磁盘上保留一个哈希映射,不幸的是磁盘哈希映射很难表现优秀。它需要大量的随机访问 I/O,当它变满时增长是很昂贵的,并且哈希冲突需要很多的逻辑。
-
范围查询效率不高。例如,您无法轻松扫描 kitty00000 和 kitty99999 之间的所有键——您必须在哈希映射中单独查找每个键。