
动态全文索引
动态索引
在真实环境中,搜索引擎需要处理的文档集合内有些文档可能被删除或者内容被修改。如果要在内容被删除或修改之后马上在搜索结果中体现出来,动态索引可以实现这种实时性需求。动态索引有三个关键的索引结构:倒排索引、临时索引和已删除文档列表。临时索引:在内存中实时建立的倒排索引,当有新文档进入系统时,实时解析文档并将其追加进这个临时索引结构中。已删除列表:存储已被删除的文档的相应文档 ID,形成一个文档 ID 列表。当文档被修改时,可以认为先删除旧文档,然后向系统增加一篇新文档,通过这种间接方式实现对内容更改的支持。当系统发现有新文档进入时,立即将其加入临时索引中。有新文档被删除时,将其加入删除文档队列。文档被更改时,则将原先文档放入删除队列,解析更改后的文档内容,并将其加入临时索引。这样就可以满足实时性的要求。在处理用户的查询请求时,搜索引擎同时从倒排索引和临时索引中读取用户查询单词的倒排列表,找到包含用户查询的文档集合,并对两个结果进行合并,之后利用删除文档列表进行过滤,将搜索结果中那些已经被删除的文档从结果中过滤,形成最终的搜索结果,并返回给用户。
索引更新策略
动态索引可以满足实时搜索的需求,但是随着加入文档越来越多,临时索引消耗的内存也会随之增加。因此要考虑将临时索引的内容更新到磁盘索引中,以释放内存空间来容纳后续的文档,此时就需要考虑合理有效的索引更新策略。
Complete Re-Build: 完全重建策略
对所有文档重新建立索引。新索引建立完成后,老的索引被遗弃释放,之后对用户查询的响应完全由新的索引负责。在重建过程中,内存中仍然需要维护老的索引对用户的查询做出响应。如图所示

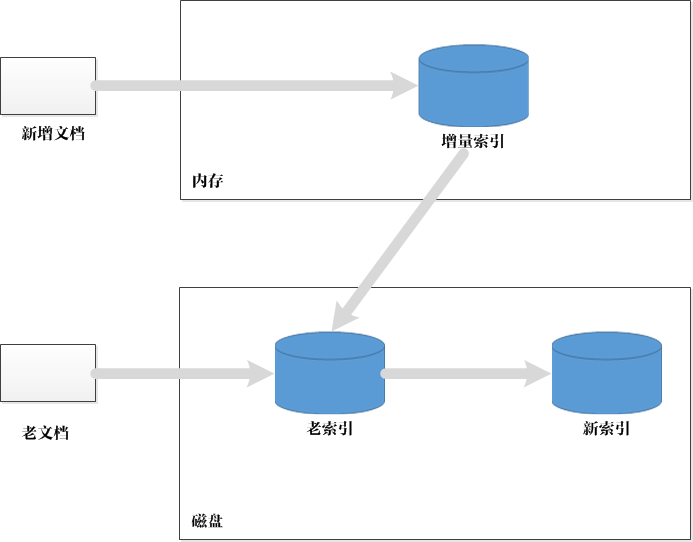
Re-Merge: 再合并策略
有新文档进入搜索系统时,搜索系统在内存维护临时倒排索引来记录其信息,当新增文档达到一定数量,或者指定大小的内存被消耗完,则把临时索引和老文档的倒排索引进行合并,以生成新的索引。过程如下图所示:

更新步骤: 1、当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排列表末尾追加倒排列表项,这个临时索引可称为增量索引 2、一旦增量索引将指定的内存消耗光,增量索引和老的倒排索引内容需要进行合并。高效的原因:在对老的倒排索引进行遍历时,因为已经按照索引单词的词典序由低到高排好顺序,所以可以顺序读取文件内容,减少磁盘寻道时间。缺点:因为要生成新的倒排索引文件,所以老索引中的倒排列表没发生变化也需要读出来并写入新索引中。增加了 IO 的消耗。
In-Place: 原地更新策略
原地更新策略的出发点是为了解决再合并策略的缺点。在索引合并时,并不生成新的索引文件,而是直接在原先老的索引文件里进行追加操作,将增量索引里单词的倒排列表项追加到老索引相应位置的末尾,这样就可达到上述目标,即只更新增量索引里出现的单词相关信息,其他单词相关信息不变动。为了能够支持追加操作,原地更新策略在初始建立的索引中,会在每个单词的倒排列表末尾预留出一定的磁盘空间,这样,在进行索引合并时,可以将增量索引追加到预留空间中。如下图:
实验数据证明,原地更新策略的索引更新效率比再合并策略低,原因: 1、由于需要做快速迁移,此策略需要对磁盘可用空间进行维护和管理,成本非常高。2、做数据迁移时,某些单词及其对应倒排列表会从老索引中移出,破坏了单词连续性,因此需要维护一个单词到其倒排文件相应位置的映射表。降低了磁盘读取速度及消耗大量内存(存储映射信息)。
Hybrid: 混合策略
将单词根据其不同性质进行分类,不同类别的单词,对其索引采取不同的索引更新策略。常见做法:根据单词的倒排列表长度进行区分,因为有些单词经常在 不同文档中出现,所以其对应的倒排列表较长,而有些单词很少见,则其倒排列表就较短。根据这一性质将单词划分为长倒排列表单词和短倒排列表单词。长倒排列 表单词采取原地更新策略,而短倒排列表单词则采取再合并策略。因为长倒排列表单词的读 / 写开销明显比短倒排列表单词大很多,所以采用原地更新策略能节省磁盘读 / 写次数。而大量短倒排列表单词读 / 写开销相对而言不算太大,所以利用再合并策略来处理,则其顺序读 / 写优势也能被充分利用。