
执行语义
执行语义
随着这些年来架构和运行时的发展和变化,实现 futures/promises 的技术也是如此,以至于抽象化转化为系统资源的有效利用。在本节中,我们将介绍三种主要执行模型,在这些模型上以流行的语言和库为基础构建 futures/promises。也就是说,我们将看到 futures 和 promises 在其 API 下实际执行和解决的不同方式。
Thread Pools
线程池是一种使用户可以访问可以进行工作的一组就绪的空闲线程的抽象。线程池的实现会照顾到工作线程的创建,管理和调度,如果不小心处理,它们很容易变得棘手且代价高昂。线程池具有许多不同的风格,具有许多用于调度和执行任务的技术,并且具有固定数量的线程,或者具有根据负载动态调整自身大小的能力。Java 的 Executor 就是典型的线程池的实现,Executor 包含了一系列 Runnable 的任务,它对上屏蔽了任务具体执行细节的抽象。这些详细信息(例如选择运行任务的线程,任务的计划方式)由 Executor 接口的基础实现管理。
类似于 Executor,Scala 在 scala.concurrent 包中提供了 ExecutionContext 类,其基础的特性类似于 Java 的 Executor;它负责并发高效地执行计算,而无需池中的用户去担心诸如调度之类的事情。更重要地是,ExecutionContext 同样可被当做接口,我们能够改变线程池地底层实现而保证上层接口的一致性。在诸多的实现中,Scala 的默认 ExecutionContext 的实现是基于 Java 的 ForkJoinPool,一种具有 work-stealing 算法的线程池实现,其中空闲线程拾取先前安排给其他繁忙线程的任务。ForkJoinPool 是一种流行的线程池实现,因为它比 Executors 的性能有所提高,能够更好地避免池引起的死锁,并最大程度地减少了在线程之间切换所花费的时间。
Scala 的 futures & promsies 就是基于 ExecutionContext,虽然通常用户使用由 ForkJoinPool 支持的基础默认 ExecutionContext,但如果用户需要特定行为(例如阻止 futures),他们还可以选择提供(或实现)自己的 ExecutionContext。n Scala,对 Future 或 Promise 的每次使用都需要传递某种 ExecutionContext。此参数是隐式的,通常是 ExecutionContext.global(默认的基础 ForkJoinPool ExecutionContext)。例如,创建并运行一个基本的 future:
implicit val ec = ExecutionContext.global
val f : Future[String] = Future { “hello world` }
在此示例中,全局执行上下文用于异步运行所创建的 Future。如前所述,Future 的 ExecutionContext 参数是隐式的。这意味着,如果编译器在所谓的隐式范围内找到 ExecutionContext 的实例,则它将自动传递给对 Future 的调用,而用户不必显式传递它。在上面的示例中,在声明 ec 时使用隐式关键字将 ec 置于隐式范围内。如前所述,Scala 中的 Future 和 Promise 是异步的,这是通过使用回调实现的。例如:
implicit val ec = ExecutionContext.global
val f = Future {
Http("http://api.fixed.io/latest?base=USD").asString
}
f.onComplete {
case Success(response) => println(response)
case Failure(t) => println(t.getMessage())
}
在此示例中,我们首先创建一个 Future f,然后当它完成时,我们提供两个可能的表达式,这些表达式可以根据 Future 是否成功执行或是否有错误来调用。在这种情况下,如果成功,我们将获得计算结果的 HTTP 字符串,并将其打印出来。如果引发了异常,我们将获取包含在异常中的消息字符串并进行打印。那么,它们如何一起工作?
如前所述,Future 需要一个 ExecutionContext,这是几乎所有 Future API 的隐式参数。此 ExecutionContext 用于执行 Future。Scala 足够灵活,可以让用户实现自己的 ExecutionContext,但是让我们谈谈默认的 ExecutionContext,它是一个 ForkJoinPool。ForkJoinPool 非常适合生成许多小计算然后又重新组合在一起的小型计算。Scala 的 ForkJoinPool 要求提交给它的任务是 ForkJoinTask。提交给全局 ExecutionContext 的任务被安静地包装在 ForkJoinTask 中,然后执行。ForkJoinPool 还使用 ManagedBlock 方法来支持可能的阻塞任务,该方法将在需要时创建备用线程,以确保在当前线程被阻塞时确保足够的并行度。总而言之,ForkJoinPool 是一个非常好的通用 ExecutionContext,它在大多数情况下都非常有效。
Event Loops
现代平台和运行时通常依赖于许多底层系统层进行操作。例如,给定的语言实现,库或框架可能会依赖基础文件系统,数据库系统和其他网络服务。与这些组件的交互通常需要一段时间,我们除了等待响应外什么也不做。这可能会浪费大量的计算资源。JavaScript 是单线程异步运行时。现在,通常异步编程通常与多线程相关联,但是我们不允许在 JavaScript 中创建新线程。而是使用事件循环机制实现 JavaScript 中的异步性。历史上一直使用 JavaScript 与 DOM 和浏览器中的用户交互进行交互,因此事件驱动的编程模型自然适用于该语言:而令人惊讶的是,即使在 Node.js 的高吞吐率场景中,该特性已然能够被较好地应用。
事件驱动的编程模型背后的总体思想是,逻辑流控制由事件处理的顺序决定。这种机制的基础是不断侦听事件并在检测到事件时触发回调。简而言之,这是 JavaScript 的事件循环。典型的 JavaScript 引擎具有一些基本组件。他们是:
- Heap Used to allocate memory for objects
- Stack Function call frames go into a stack from where they’re picked up from top to be executed.
- Queue A message queue holds the messages to be processed.
每条消息都有一个回调函数,在处理该消息时会触发该函数。这些消息可以通过按钮单击或滚动之类的用户操作或 HTTP 请求之类的操作,请求数据库以获取记录或读取/写入文件的方式来生成。将邮件何时排入队列与执行时间分开,意味着单线程不必等待操作完成就可以继续进行操作。我们在要执行的操作上附加了回调,当时间到了时,回调将以我们的操作结果运行。回调在孤立的情况下可以很好地工作,但是它们迫使我们进入一种继续传递执行方式的方式,即所谓的回调地狱(Callback hell)。
getData = function (param, callback) {
$.get("http://example.com/get/" + param, function (responseText) {
callback(responseText);
});
};
getData(0, function (a) {
getData(a, function (b) {
getData(b, function (c) {
getData(c, function (d) {
getData(d, function (e) {
// ...
});
});
});
});
});
Promise 则能提供给我们更好地代码可读性:
getData = function (param, callback) {
return new Promise(function (resolve, reject) {
$.get("http://example.com/get/" + param, function (responseText) {
resolve(responseText);
});
});
};
getData(0).then(getData).then(getData).then(getData).then(getData);
Promise 是一种抽象,使使用 JavaScript 中的异步操作更加有趣。回调会导致控制反转,这很难大规模扩展。从继续传递样式继续,在继续传递样式中,您指定操作完成后需要执行的操作,被调用方仅返回 Promise 对象。这使责任链倒置了,因为现在,呼叫者负责在 Promise 完成后处理 Promise 的结果。ES2015 规范规定 Promise 不得在创建事件循环的同一时刻触发其解析/拒绝功能。这是重要的属性,因为它确保确定的执行顺序。而且,一旦 Promise 兑现或失败,就不得更改 Promise 的值。这确保了 Promise 不能被多次解决。
让我们举一个例子来了解在 JavaScript 引擎中发生的 Promise 解决工作流程。假设我们执行一个函数 g(),该函数又调用另一个函数 f()。函数 f 返回一个 Promise,在递减计数 1000 毫秒后,将使用单个值 true 解析该 Promise。一旦 f 得到解决,就会基于 Promise 的值来提醒值 true 或 false。
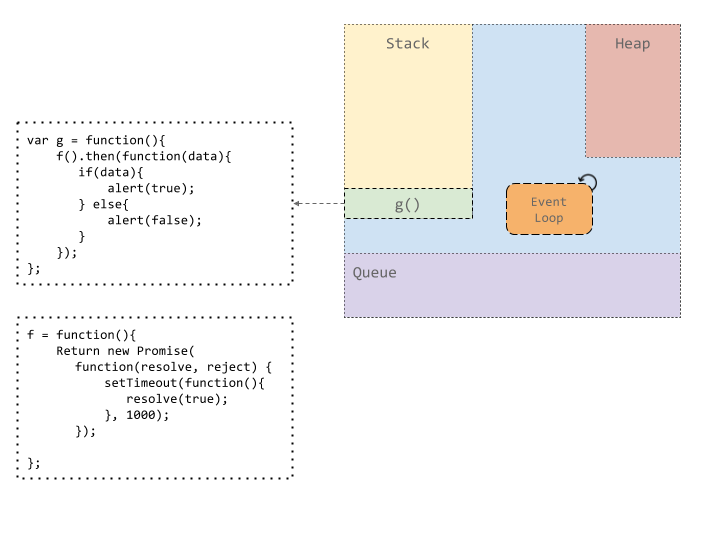
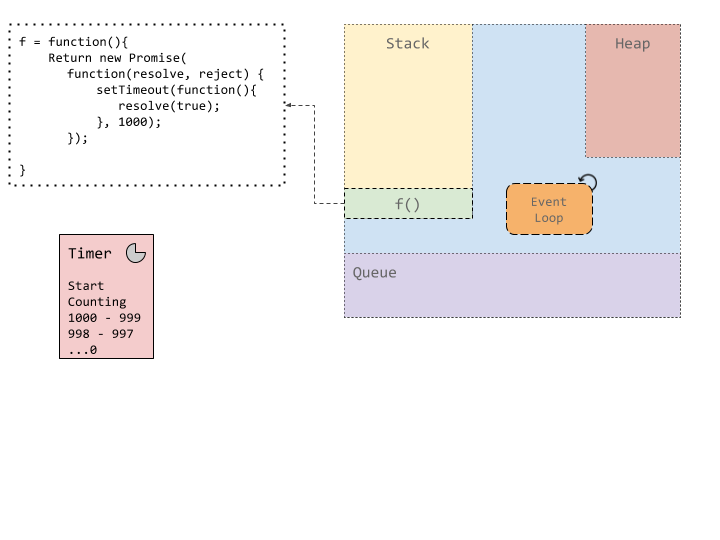
现在,JavaScript 的运行时是单线程的。这个说法即对也不对。执行用户代码的线程是单线程的。它执行堆栈顶部的内容,将其运行至完成,然后移至堆栈上的下一个内容。但是,也有许多帮助程序线程可以处理诸如网络或计时器/setTimeout 类型事件之类的事件。该计时线程处理 setTimeout 的计数器。
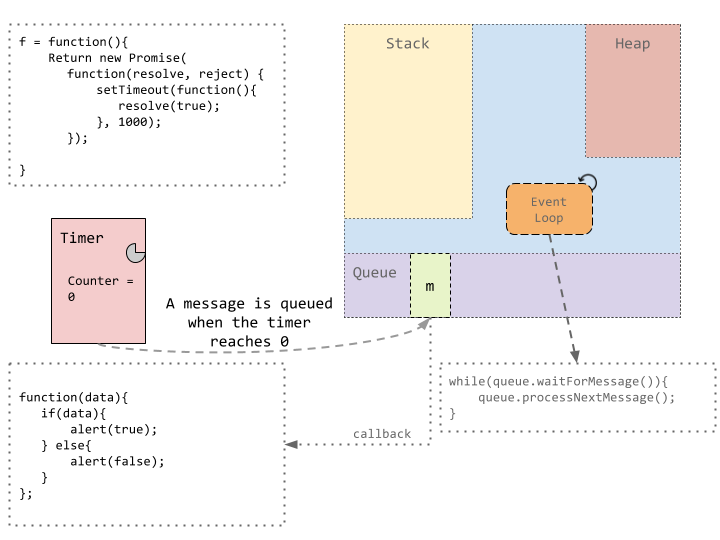
计时器到期后,计时器线程将一条消息放入消息队列中。然后由事件循环处理排队的消息。如上所述,事件循环只是一个无限循环,它检查消息是否已准备好进行处理,将其拾取并将其放入堆栈中以执行回调。
在这里,由于 future 的值为 true,所以在选择执行回调时会向我们发出 true 值的警报。
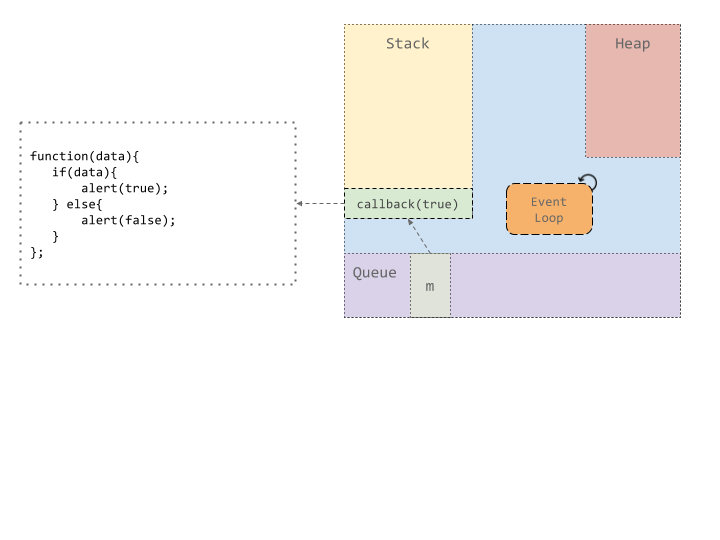
我们在这里忽略了堆,但是所有函数,变量和回调都存储在堆中。正如我们在这里看到的,即使据说 JavaScript 是单线程的,也有许多帮助程序线程可以帮助主线程执行超时,UI,网络操作,文件操作等操作。Run-to-completion 可以帮助我们以一种很好的方式对代码进行推理。每当函数启动时,它需要在产生主线程之前完成。它访问的数据不能被其他人修改。这也意味着每个功能都需要在合理的时间内完成,否则程序似乎已挂起。这使得 JavaScript 非常适合排队等待完成后又要拾取的 I/O 任务,而不适合通常需要很长时间才能完成的数据处理密集型任务。
我们还没有讨论错误处理,但是它的处理方式完全相同,错误回调由 Promise 被拒绝的错误对象调用。事件循环已被证明具有惊人的性能。当网络服务器是围绕多线程设计的时,一旦您建立了数百个并发连接,CPU 就会花费大量的时间进行任务切换,从而开始失去整体性能。从一个线程切换到另一个线程会产生开销,这在规模上可能会相加很大。当使用每个连接一个线程时,Apache 过去甚至阻塞了数百个并发用户,而 Node.js 可以基于事件循环和异步 IO 扩展到 100,000 个并发连接。
Thread Model
Oz 编程语言引入了数据流并发模型的思想。在 Oz 中,只要程序遇到未绑定的变量,它就会等待其解析。变量的数据流属性有助于我们在 Oz 中编写线程,这些线程通过生产者-消费者模式通过流进行通信。基于数据流的并发模型的主要优点是它具有确定性-使用相同参数调用的同一操作始终会产生相同的结果。如果代码没有副作用,则使并发程序的推理变得容易得多。
Alice ML 是 Standard ML 的方言,支持惰性计算,并发,分布式和约束编程。Alice 项目的早期目标是在一种类型化的编程语言之上重建 Oz 编程语言的功能。以 Standard ML 方言为基础,Alice 还通过使用 Future 的类型将并发功能作为语言的一部分提供。Alice 的 Future 代表并发操作的不确定结果。Alice ML 中的 Promise 是 Future 的显式句柄。
可以使用 spawn 关键字在自己的线程中计算 Alice 中的任何表达式。Spawn 总是返回一个 Future,该 Future 充当操作结果的占位符。从某种意义上说,Alice 中的线程总会有结果,Alice ML 中的 Future 可以被认为是功能线程。如果线程执行的操作要求将 Future 的值用作占位符,则称该线程正在接触 Future。阻塞所有涉及 Future 的线程,直到解决 Future。如果线程引发异常,则 Future 失败,并且在接触该异常的线程中重新引发该异常。Future 也可以作为价值传递。这有助于我们在 Alice 中实现并发数据流模型。
Alice 还允许对表达式进行延迟计算。带有 lazy 关键字的表达式将被计算为延迟的 Future。需要时可以计算懒惰的 Future。如果与并发或延迟的 Future 关联的计算以异常结束,则将导致失败的 Future。请求失败的 Future 不会受到阻碍,只会引发导致失败的异常。