
字符串
字符串
字符编码
Python2 的默认编码是 ascii,Python3 的默认编码是 utf-8,可以通过下面的方式获取:
- Python2
Python 2.7.11 (default, Feb 24 2016, 10:48:05)
[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
- Python3
Python 3.5.2 (default, Jun 29 2016, 13:43:58)
[GCC 4.2.1 Compatible Apple LLVM 7.3.0 (clang-703.0.31)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
Python2 中的字符类型
Python2 中有两种和字符串相关的类型:str 和 unicode,它们的父类是 basestring。其中,str 类型的字符串有多种编码方式,默认是 ascii,还有 gbk,utf-8 等,unicode 类型的字符串使用 u’…’ 的形式来表示,下面的图展示了 str 和 unicode 之间的关系:
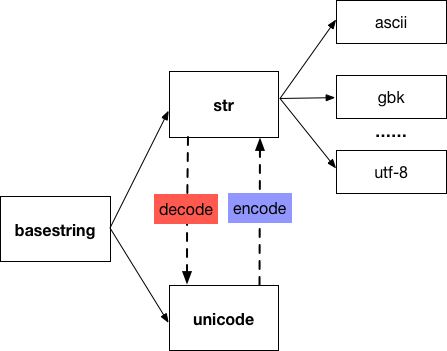
两种字符串的相互转换概括如下:
- 把 UTF-8 编码表示的字符串 ‘xxx’ 转换为 Unicode 字符串 u’xxx’ 用
decode('utf-8')方法:
>>> '中文'.decode('utf-8')
u'\u4e2d\u6587'
- 把 u’xxx’ 转换为 UTF-8 编码的 ‘xxx’ 用
encode('utf-8')方法:
>>> u'中文'.encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
常用操作
Python 字符串支持分片、模板字符串等常见操作:
var1 = 'Hello World!'
var2 = "Python Programming"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]
# var1[0]: H
# var2[1:5]: ytho
print "My name is %s and weight is %d kg!" % ('Zara', 21)
# My name is Zara and weight is 21 kg!
str[0:4]
len(str)
string.replace("-", " ")
",".join(list)
str.find(",")
str.index(",") # same, but raises IndexError
str.count(",")
str.split(",")
str.lower()
str.upper()
str.title()
str.lstrip()
str.rstrip()
str.strip()
str.islower()
# 移除所有的特殊字符
re.sub('[^A-Za-z0-9]+', '', mystring)
如果需要判断是否包含某个子字符串,或者搜索某个字符串的下标
# in 操作符可以判断字符串
if "blah" not in somestring:
continue
# find 可以搜索下标
s = "This be a string"
if s.find("is") == -1:
print "No 'is' here!"
else:
print "Found 'is' in the string."
find
find 方法用于在一个字符串中查找子串,它返回子串所在位置的最左端索引,如果没有找到,则返回 -1。
>>> motto = "to be or not to be, that is a question"
>>> motto.find('be') # 返回 'b' 所在的位置,即 3
3
>>> motto.find('be', 4) # 指定从起始位置开始找,找到的是第 2 个 'be'
16
>>> motto.find('be', 4, 7) # 指定起始位置和终点位置,没有找到,返回 -1
-1
split
split 方法用于将字符串分割成序列。
>>> '/user/bin/ssh'.split('/') # 使用 '/' 作为分隔符
['', 'user', 'bin', 'ssh']
>>> '1+2+3+4+5'.split('+') # 使用 '+' 作为分隔符
['1', '2', '3', '4', '5']
>>> 'that is a question'.split() # 没有提供分割符,默认使用所有空格作为分隔符
['that', 'is', 'a', 'question']
需要注意的是,如果不提供分隔符,则默认会使用所有空格作为分隔符(空格、制表符、换行等)。
join
join 方法可以说是 split 的逆方法,它用于将序列中的元素连接起来。
>>> '/'.join(['', 'user', 'bin', 'ssh'])
'/user/bin/ssh'
>>>
>>> '+'.join(['1', '2', '3', '4', '5'])
'1+2+3+4+5'
>>> ' '.join(['that', 'is', 'a', 'question'])
'that is a question'
>>> ''.join(['h', 'e', 'll', 'o'])
'hello'
>>> '+'.join([1, 2, 3, 4, 5]) # 不能是数字
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence item 0: expected string, int found
strip
strip 方法用于移除字符串左右两侧的空格,但不包括内部,当然也可以指定需要移除的字符串。
>>> ' hello world! '.strip() # 移除左右两侧空格
'hello world!'
>>> '%%% hello world!!! ####'.strip('%#') # 移除左右两侧的 '%' 或 '#'
' hello world!!! '
>>> '%%% hello world!!! ####'.strip('%# ') # 移除左右两侧的 '%' 或 '#' 或空格
'hello world!!!'
replace
replace 方法用于替换字符串中的所有匹配项。
>>> motto = 'To be or not To be, that is a question'
>>> motto.replace('To', 'to') # 用 'to' 替换所有的 'To',返回了一个新的字符串
'to be or not to be, that is a question'
>>> motto # 原字符串保持不变
'To be or not To be, that is a question'
translate
translate 方法和 replace 方法类似,也可以用于替换字符串中的某些部分,但 translate 方法只处理单个字符。
str.translate(table[, deletechars]);
其中,table 是一个包含 256 个字符的转换表,可通过 maketrans 方法转换而来,deletechars 是字符串中要过滤的字符集。
>>> from string import maketrans
>>> table = maketrans('aeiou', '12345')
>>> motto = 'to be or not to be, that is a question'
>>> motto.translate(table)
't4 b2 4r n4t t4 b2, th1t 3s 1 q52st34n'
>>> motto
'to be or not to be, that is a question'
>>> motto.translate(table, 'rqu') # 移除所有的 'r', 'q', 'u'
't4 b2 4 n4t t4 b2, th1t 3s 1 2st34n'
可以看到,maketrans 接收两个参数:两个等长的字符串,表示第一个字符串的每个字符用第二个字符串对应位置的字符替代,在上面的例子中,就是 ‘a’ 用 ‘1’ 替代,’e’ 用 ‘2’ 替代,等等,注意,是单个字符的代替,而不是整个字符串的替代。因此,motto 中的 o 都被替换为 4,e 都被替换为 2,等等。
lower/upper
lower/upper 用于返回字符串的大写或小写形式。
看看例子:
>>> x = 'PYTHON'
>>> x.lower()
'python'
>>> x
'PYTHON'
>>>
>>> y = 'python'
>>> y.upper()
'PYTHON'
>>> y
'python'
模板字符串
import datetime
name = 'Fred'
age = 50
anniversary = datetime.date(1991, 10, 12)
x = a + b
x = '%s, %s!' % (name, age)
x = 'name: %s; age: %d' % (name, age)
x = '{}, {}!'.format(name, age)
x = 'name: {}; age: {}'.format(name, age)
f'My name is {name}, my age next year is {age+1}, my anniversary is {anniversary:%A, %B %d, %Y}.'
# 'My name is Fred, my age next year is 51, my anniversary is Saturday, October 12, 1991.'
f'He said his name is {name!r}.'
# "He said his name is 'Fred'."