
01.Text Embeddings
Text Embeddings
在古老的未来主义电影中,如《2001 太空漫游》,主计算机(HAL)能够与人类交谈,并能非常容易地理解他们所说的话。当时,让计算机理解和产生语言似乎是一项不可能完成的任务,但最新的大型语言模型(LLM)能够做到这一点,使人类几乎无法分辨他们是在与另一个人,还是在与一台计算机交谈。
自然语言处理(NLP)的精髓任务是理解人类语言。然而,那里有一个很大的断层。人类用文字和句子说话,但计算机只理解和处理数字。我们如何才能将单词和句子连贯地转化为数字呢?将单词分配给数字的做法被称为单词嵌入。我们可以把单词嵌入看作是对单词的分数分配,有一些很好的属性(我们很快就会学到)。
What is a Word Embedding?
在我们讨论什么是词的嵌入之前,让我测试一下你的直觉。在下图中(测验 1),我在平面上找到了 12 个词。这些词是以下内容:
Banana
Basketball
Bicycle
Building
Car
Castle
Cherry
House
Soccer
Strawberry
Tennis
Truck
现在,问题是,在这个平面上,你会把 Apple 这个词放在哪里?它有很多地方可以去,但我允许有三种可能性,分别标为 A、B 和 C。
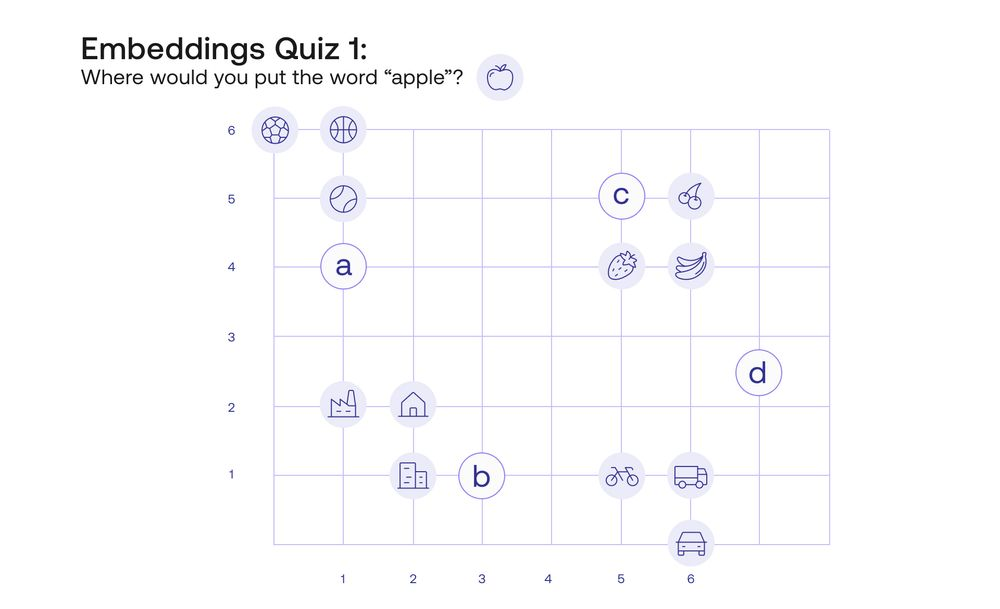
我会做的,是把它放在 C 点,因为让 “苹果” 这个词靠近 “香蕉”、“草莓 “和 “樱桃”,而远离 “房子”、“汽车 “或 “网球 “等其他词,这样才有意义。这正是一个词的嵌入。那么我们给每个词分配的数字是什么呢?很简单,就是该词位置的横坐标和纵坐标。这样,“苹果 “这个词被分配到数字[5,5],而 “自行车 “这个词被分配到坐标[5,1]。
为了冗余起见,让我们列举一下一个好的词嵌入应该具有的一些属性:
- 相似的词应该对应于相近的点(或者等同于相似的分数)。
- 不同的词应该对应于远处的点(或者说,对应于明显不同的分数)。
Word Embeddings Capture Features of the Word
上面的词嵌入满足了属性 1 和 2。就这样了吗?还不是。这些词嵌入还有更多的东西,那就是它们不仅能捕捉到词的相似性,而且还能捕捉到语言的其他属性。在语言中,单词可以被组合起来,得到更复杂的概念。在数学中,数字可以通过加减来得到其他数字。我们能不能建立一个词的嵌入,来捕捉词与词之间的关系,就像数字之间的关系一样?
让我们看一下四个词,“小狗”、“狗”、“小牛 “和 “牛”。这些词显然是相关的。现在,为了再次测试你的直觉,我要把 “小狗”、“狗 “和 “小牛 “这几个词放在平面上,然后我让你加上 “牛” 这个词。你会把它加在哪里,在标有 A、B 或 C 的地方?
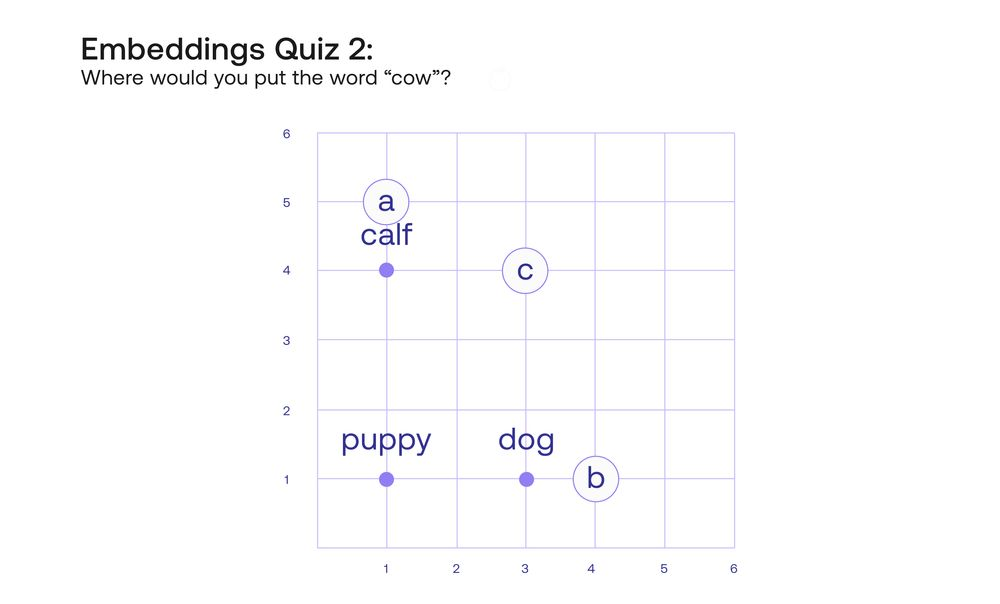
虽然把它放在 A 处是有道理的,因为它们都是牛,离 “小牛 “更近,或者放在 B 处,因为它是成年动物,像 “狗 “一样,但我要把它放在 C 处,坐标为[3,4]。为什么呢?因为这四个词所形成的矩形捕捉到了它们之间一些非常重要的关系。例如,这里捕获了两个类比。小狗之于狗就像小牛之于牛 “这个类比可以翻译成 “从小狗到狗的路径与从小牛到牛的路径相同”。狗对牛就像小狗对小牛一样 “的比喻也可以在这个矩形中得到体现,如下图所示。

然而,这还不是冰山一角。这里生效的词嵌入的主要属性是,两个轴(垂直和水平)代表不同的东西。如果你仔细观察,向右移动会把小狗变成狗,把小牛变成牛,这是年龄的增加。同样,向上移动会使小狗变成小牛,狗变成牛,这是动物体型的增加。看来,这个嵌入的理解是,其中的词有两个主要的属性,或特征:年龄和大小。此外,似乎这个嵌入物把年龄放在横轴上,把大小放在纵轴上。在这种情况下,你会想象 “鲸鱼” 这个词会在哪里?可能是在 “牛” 这个词上面的某个地方。如果有一个 “真正的老狗 “的词呢?这个词会在 “狗 “这个词的右边的某个地方。
一个好的单词嵌入不仅能够捕捉到年龄和大小,而且还能捕捉到单词的许多其他特征。由于每个特征都是一个新的轴或坐标,那么一个好的嵌入必须为每个词分配两个以上的坐标。例如,Cohere 的一个嵌入,有 4096 个坐标与每个词相关。这些由 4096 个(或多少个)坐标组成的行被称为向量,所以我们经常谈论对应于一个词的向量,并把向量内的每个数字作为一个坐标。这些坐标中的一些可能代表该词的重要属性,如年龄、性别、大小。有些可能代表各种属性的组合。但还有一些可能代表人类可能无法理解的晦涩的属性。但总的来说,单词嵌入可以被看作是将人类语言(单词)翻译成计算机语言(数字)的好方法,这样我们就可以开始用这些数字训练机器学习模型。
Sentence embeddings
因此,单词嵌入似乎相当有用,但实际上,人类语言要比简单地把一堆单词放在一起复杂得多。人类语言有结构,有句子,等等。例如,我们如何能够表示一个句子呢?嗯,这里有一个想法。所有单词的分数之和如何呢?例如,假设我们有一个词的嵌入,给这些词分配以下分数:
No: [1,0,0,0]
I: [0,2,0,0]
Am: [-1,0,1,0]
Good: [0,0,1,3]
那么句子 “No, I am good!” 就对应于向量[0,2,2,3]。然而,“I am no good” 这个句子也将对应于向量[0,2,2,3]。这不是一件好事,因为计算机对这两个句子的理解是完全相同的,然而它们是完全不同的,几乎是相反的句子!这就是为什么我们需要一个更好的嵌入!因此,我们需要更好的嵌入,考虑到单词的顺序、语言的语义和句子的实际含义。
这就是句子嵌入开始发挥作用的地方。句子嵌入就像单词嵌入一样,只不过它以一种连贯的方式将每个句子与一个充满数字的向量联系起来。所谓连贯性,我的意思是,它满足与单词嵌入相似的属性。例如,类似的句子被分配到类似的向量上,不同的句子被分配到不同的向量上,最重要的是,向量的每个坐标都标识了该句子的一些(无论是清晰的还是模糊的)属性。
Cohere 嵌入就是这样做的。使用变换器、注意机制和其他尖端算法,这个嵌入将每个句子发送到一个由 4096 个数字组成的向量,而且这个嵌入的效果非常好。作为一个小例子,这里是一个嵌入的热图,每个句子包含 10 个条目,有几个句子(写下整个 4096 个条目会占用太多的空间,所以我们用一种叫做主成分分析的降维算法来压缩它。
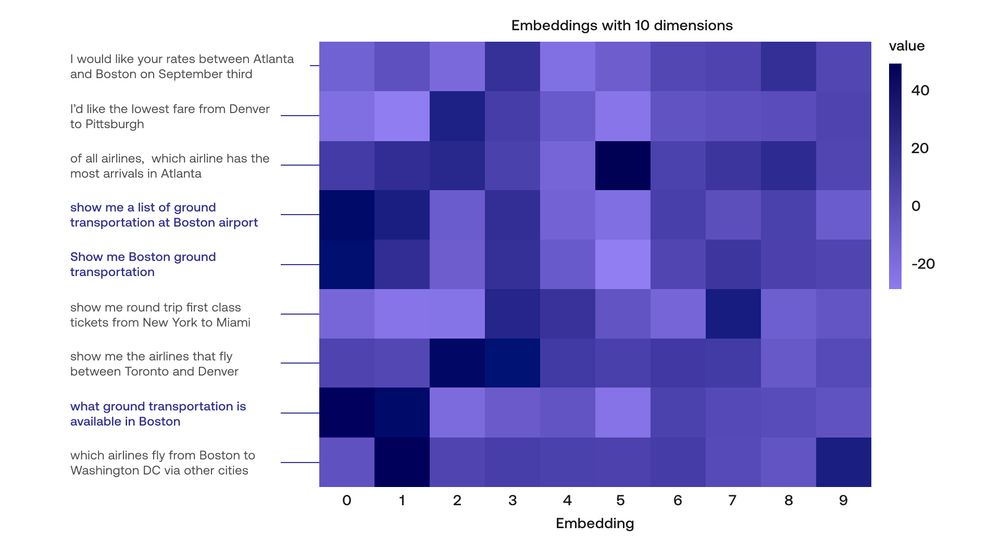
请注意,这些句子都非常相似。特别是,三个突出的句子几乎都有相同的含义。如果你看一下它们对应的向量,这些也是非常相似的。这正是一个嵌入应该做的事情。
How to Use These Embeddings?
Now that you’ve learned how useful these embeddings are, it’s time to start playing with them and finding good practical uses for them! The Cohere dashboard provides a very friendly interface to use them. Here is a small example, with the following phrases:
I like my dog
I love my dog
I adore my dog
Hello, how are you?
Hey, how's it going?
Hi, what's up?
I love watching soccer
I enjoyed watching the world cup
I like watching soccer matches
To see the results of the sentence embedding, go to the “Embed” tab in the Cohere dashboard, and type the sentences (click here for an embed demo you can play with).
The results come out as vectors with 4096 entries for each sentence. These are obviously hard to visualize, but there is a way to bring them down to 2 entries per sentence in order to be easily visualized. This visualization is in the plot below.
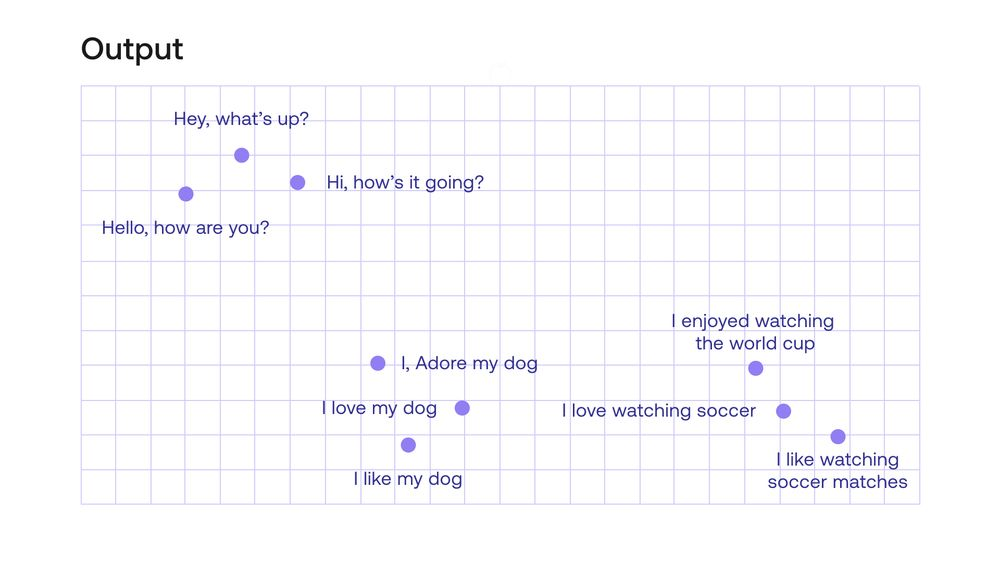
Notice that the embedding seemed to capture the essence of the sentences, and there are 3 clear clusters of sentences. In the top left corner you find the sentences that greet a person, in the middle, those that talk about a person’s dog, and in the bottom right corner, those that talk about soccer. Notice that sentences such as “Hey what’s up” and “Hello, how are you?” have no words in common, yet the model can tell that they have the same meaning.
Multilingual Sentence Embeddings
Most word and sentence embeddings are dependent on the language that the model is trained on. If you were to try to fit the French sentence “Bonjour, comment ça va?” (meaning: hello, how are you?) in the embedding from the previous section, it will struggle to understand that it should be close to the sentence “Hello, how are you?” in English. For the purpose of unifying many languages into one, and being able to understand text in all these languages, Cohere has trained a large multilingual model, that has showed wonderful results with more than 100 languages. Here is a small example, with the following sentences in English, French, and Spanish.
The bear lives in the woods
El oso vive en el bosque
L’ours vit dans la foret
The world cup is in Qatar
El mundial es en Qatar
La coupe du monde est au Qatar
An apple is a fruit
Una manzana es una fruta
Une pomme est un fruit
El cielo es azul
The sky is blue
Le ciel est bleu
The model returned the following embedding.

Notice that the model managed to identify the sentences about the bear, soccer, an apple, and the sky, even if they are in different languages.