
2023-吴英俊-重新思考流处理与流数据库
重新思考流处理与流数据库

在过去的数年里,我们见证了流处理技术的飞速进步与普及。我第一次接触流处理是在 2012 年。那时候的我有幸在微软亚洲研究院实习,在系统组里做分布式流处理系统。之后我分别在新加坡国立大学、卡耐基梅隆大学、IBM Almaden 研究院、AWS Redshift 从事流处理与数据库系统的研究与开发。如今,我正在 RisingWave Labs(RisingWave: A Cloud-Native Streaming Database)搭建下一代流数据库系统。
一晃 11 年过去,当时在微软亚研院实习的我万万没想到,我在这个领域持续做了十多年,并不断突破边界,从纯技术开发逐步转向探索该领域商业化的道路。在创业公司里,最令人兴奋也最具有挑战的事情便是预测未来 — 根据历史的轨迹思考与判断行业的发展方向。在过去的数月中,我一直在思考几个问题:**为什么需要流处理?为什么需要流数据库?流处理系统真的能够颠覆批处理系统吗?**在这篇文章中,我将结合自己的软件开发与客户沟通经验,从实践角度探讨流处理与流数据库的过去、现在与未来。
流处理系统的正确使用姿势
说到流处理系统,大家自然而然的会想到一些低延迟用例:股票交易、异常监控、广告计算等等。然而,在这些用例中,流处理系统到底如何被使用的呢?使用流处理系统时,用户期望的延迟到底有多低?为什么不用一些批处理系统来解决问题?在这里,我来结合自己的经验回答这些问题。
典型流处理场景
无论什么具体的用例,流处理系统通常被应用在以下两个场景中:数据接入与数据分析。
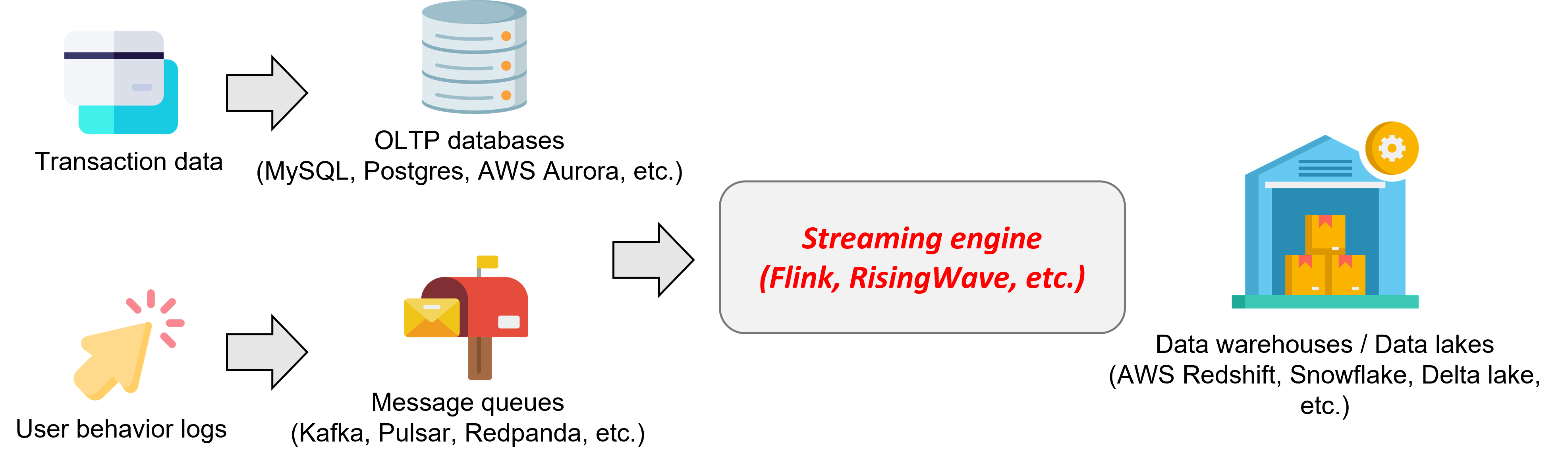
数据接入:将 OLTP 数据库与消息队列中的数据做 join 操作之后插入到数据仓库与数据湖中。
- **数据接入(data ingestion)。**所谓数据接入,就是将数据从一个(或多个)数据系统经过一定计算之后插入到另一个(或多个)数据系统中。另一种常见的说法便是 ETL。用户为什么要做数据接入?我举几个简单例子大家就明白了。我们可以考虑有个电商网站,使用一个 OLTP 数据库(比如 AWS Aurora、CockroachDB、TiDB 等)支撑线上交易。同时,为了更好的分析用户的行为,网站也可能使用了一个程序采集用户行为(比如点击广告等),并将用户行为日志插入了消息队列(如 Kafka、Pulsar、Redpanda 等)中。为了更好的提升销量,电商网站通常会将交易数据与用户行为日志导入到同一个数据系统,如 Snowflake 或是 Redshift 这样的数据仓库中,以便进行分析。在这里,电商网站的工程师们便可以使用流处理系统将数据从 OLTP 数据库与消息队列实时的搬到数据仓库里。在数据搬运的过程中,流处理系统会做各类计算,来进行脏数据清理、多个数据源 join 等操作。在我们接触过的场景中, 数据的源头往往是 OLTP 数据库、消息队列、存储系统等,而数据的终点除了 OLTP 数据库、消息队列、存储系统外,更常见的便是数据仓库与数据湖。值得一提的是,我们目前没有见过从数据仓库与数据湖导出数据到其他系统的案例,主要原因还是用户通常将数据仓库与数据湖看作是数据的终点,同时由于数据仓库与数据湖一般不提供数据变更日志,这使得数据实时导出更加困难。
- **数据分析(data analytics)。**数据分析很容易理解,就是对一个(或多个)数据系统中的数据进行计算得到分析结果,并将结果推送给用户。当使用流处理系统做数据分析时,往往意味着用户希望是对最近(比如 30 分钟、1 小时、7 天等)的数据更加感兴趣,而不是去到数仓中批量处理数月甚至数年的数据。在数据分析场景中,流数据系统的上游往往还是 OLTP 数据库、消息队列、存储系统等,而下游通常是个 key-value store(如 Cassandra、DynamoDB 等)或者是个缓存系统(如 Redis 等)。当然,也有些用户会直接将流处理的结果发送给应用层,这种使用方式一般在告警系统中比较普遍。
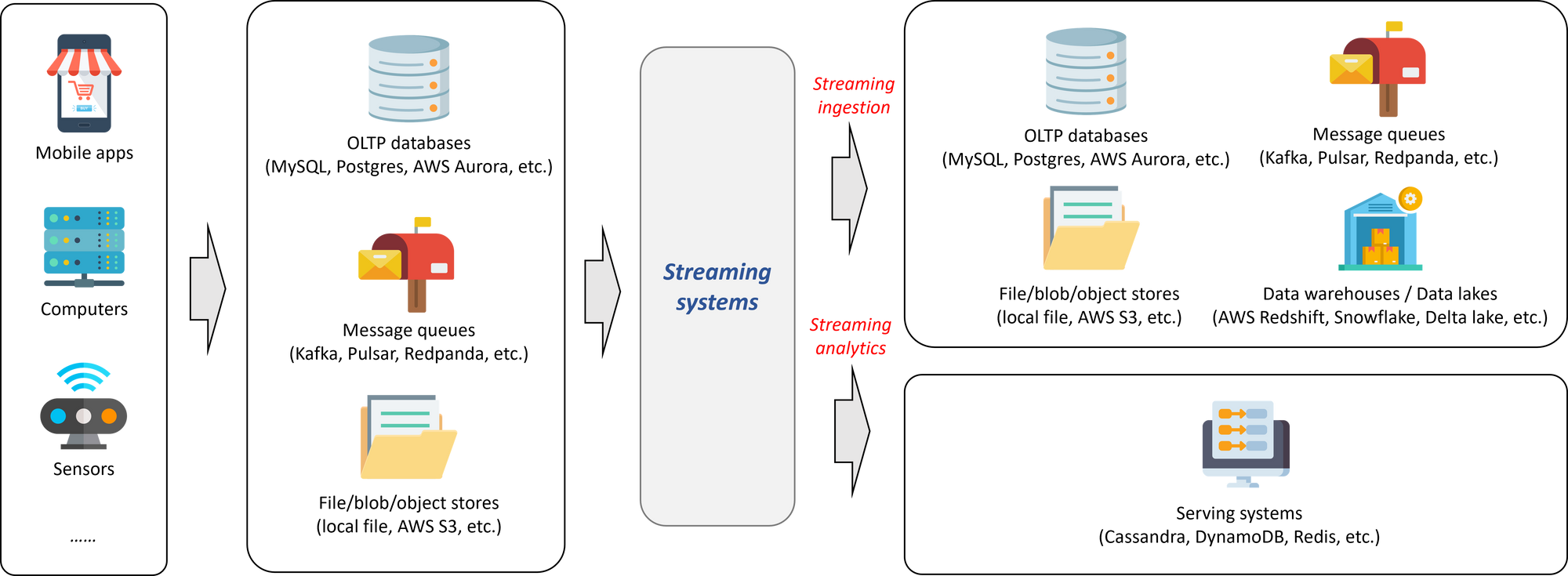
流处理的两个典型场景:数据接入与数据分析。
尽管批处理系统同样能做数据接入与数据分析,但是流处理系统相比于批处理系统,能够将延迟从小时或者天级别降低到秒级或者分钟级。这在一些业务中将带来巨大好处。对于数据接入这个场景中,降低延迟可以让下游系统(比如数据仓库)用户更及时的得到最新的数据,并对最新的数据进行处理。而在数据分析这个场景中,下游系统可以实时看到最新的数据处理结果,从而能够将结果及时呈现给用户。
有朋友一定会问:
- 对于数据接入(或者 ETL)这个场景,我们拿个编排工具(比如 Apache Airflow)定时触发批处理系统(比如 Apache Spark)做计算不就可以了吗?
- 对于数据分析场景,许多实时分析系统(比如 Clickhouse、Apache Pinot、Apache Doris 等)都能对数据进行在线分析,为什么还要用流处理系统?
这两个问题非常值得深入探讨,我们将会在文章最后一节进行讨论。
用户的期望:延迟到底需要有多低?
对于流处理系统的用户来说,他们期望的延迟到底是多少呢?秒?毫秒?微秒?越低越好?根据我们的客户访谈结果,多数流处理系统用户的用例所需要的延迟在百毫秒到数十分钟不等。在我们的用户访谈中,不少科技企业的在线数据系统工程师对我们说:“使用了流处理系统之后,我们的计算延迟从天级别降到了分钟级,这样的转变已经让我们非常满意了,并没有特别的需求进一步降低延迟。”所谓”延迟越低越好“,在我们看来,听上去很美好,但实际上并没有太多实际用例做支撑。事实上,在一些超低延迟场景中,通用的流处理系统也达不到其所需的延迟需求。
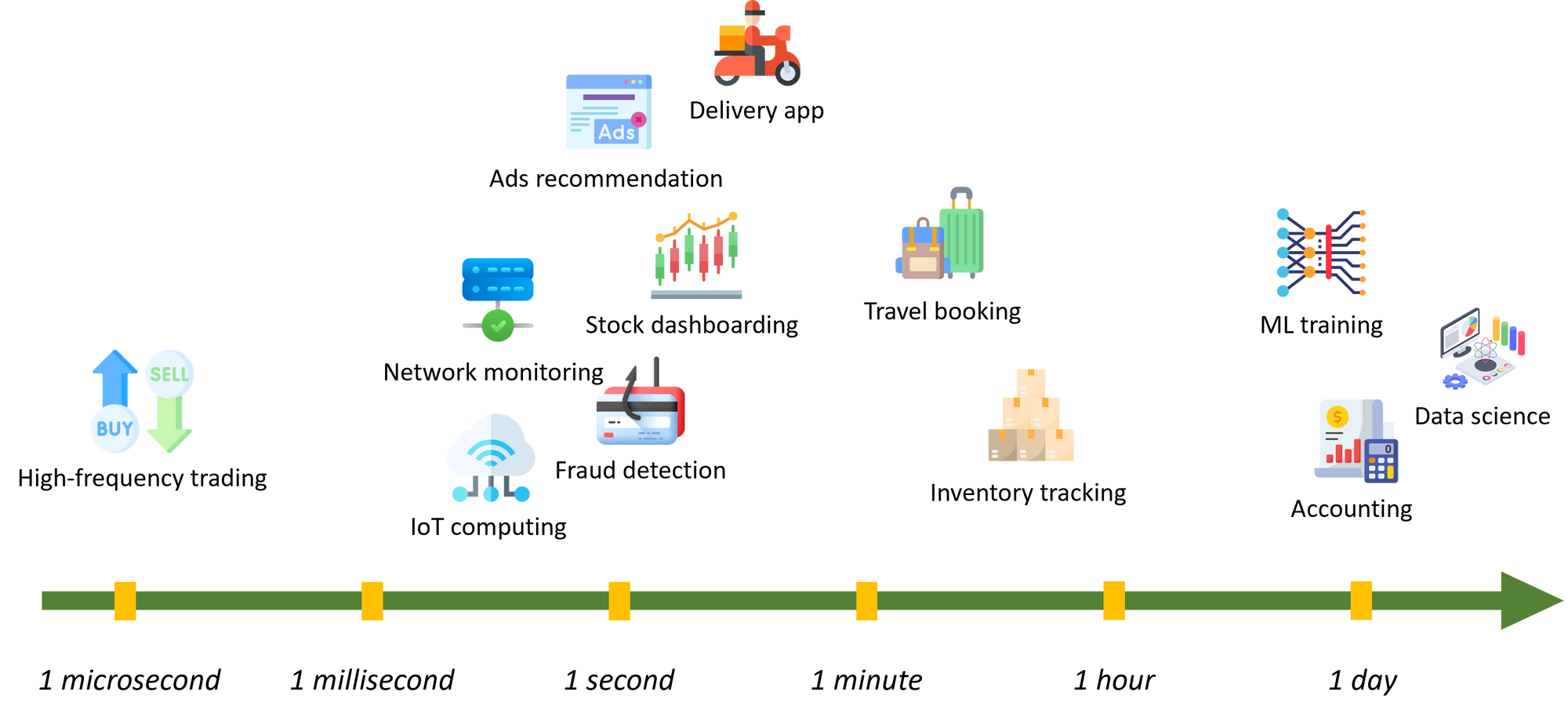
各类真实场景对延迟的需求。
一个很典型的超低延迟场景便是高频量化交易场景。量化公司都期望自己的系统能够在极短时间内响应市场的波动,从而对股票或者期货进行买入卖出。量化公司需要的延迟通常在微秒级别。为了达到这种级别的延迟,许多量化公司都会将自己的机房搬去离交易所物理位置更近的大楼,并精心挑选网络运营商来减少由于网络通信造成的延迟。在这种场景中,量化公司几乎都会选择自己自建系统,而非采用市面上的通用流处理系统(如 Flink、RisingWave 等)。这不仅是因为通用流处理系统往往由于封装达不到延迟的需求,也是因为量化交易通常需要一些特殊的自定义算子,而这些算子一般都不会被通用流处理系统所支持。
还有一些低延迟场景是 IoT(物联网)与网络监控。这类场景的延迟通常在毫秒级,可能是几毫秒,也可能是几百毫秒。在这类场景中,通用流处理系统(如 Flink、RisingWave 等)可能可以做到很好的支撑。但在一些用例中,还是需要使用特化的系统。一个很好的例子就是车载传感器。车载传感器可能会监控车辆的行驶速度、车辆坐标、踩油门与刹车的频率等等信息。这类信息可能由于隐私、网络带宽等原因,一般不会回传给数据中心。因此,常见的解决方案就是在车辆上直接装处理器(或者说是嵌入式设备)来进行数据处理。在这类设备上安装通用流处理系统还是不太合适的。
接下来要谈的便是一些大家耳熟能详的低延迟场景了:广告推荐、欺诈检测、股市大盘报表、订餐 APP 等。这类场景的延迟通常来说都是在百毫秒或者数分钟之间。更低的延迟听起来可能更好,但不一定有必要。就拿股票大盘报表来举例。普通散户通常通过盯着网站或者手机看股票波动来进行交易决策。这些散户真的有需求知道 10 毫秒之前的股票交易信息吗?其实是没有必要的。人眼看到的极限频率是 60Hz,也就是人眼根本分辨不出 16 毫秒以下的刷新。同时,人做决策的反应速度都是在秒级,哪怕是训练有素的运动员听到枪声的反应速度也只能在 100-200 毫秒左右。因此,对于股票大盘这种给人提供决策信息的场景,低于百毫秒的延迟都是没有必要的。而这类需求百毫秒到分钟级的场景,便是通用流处理系统(如 Flink、RisingWave 等)最擅长的场景了。
然后就到了一些对延迟没有很高要求的场景了:酒店预订、库存管理等。对于这类延迟不敏感场景来说,流处理系统与批处理系统其实都能做比较好的支持,因此在用户选择系统的时候,考虑的点往往不是性能,而是成本、灵活性等方面了。
对于机器学习模型训练、数据科学、财务报表等这些对延迟完全没有要求的场景,很显然批处理系统更加适用。当然了,随着技术的不断进步,我们也看到了在线机器学习、在线数据科学等方向的兴起,而不少公司也的确开始使用流处理系统来将这些应用实时化。在本文,我们就不对这类场景进行过多讨论了。
回顾(被遗忘的)历史
上一节讲了流处理系统的使用场景。在这一节里,我们来谈谈流处理系统的历史。
Apache Storm 与其之后的系统
对于许多资深工程师来说,Apache Storm 也许是他们接触过的第一个流处理的系统。Storm 是使用一门称为 Clojure 的小众 JVM 编程语言编写的分布式流计算引擎。相信很多新一代的程序员可能都没听说过 Clojure 这种语言。Storm 在 2011 年被 Twitter 公司开源。在那个被 Apache Hadoop 统治的年代,Storm 的出现改变了许多人对数据处理的认知。传统来讲,用户处理数据的方式都是将大量数据首先导入到 HDFS,再用 Hadoop 等批计算引擎对数据进行分析。而有了 Storm,用户可以在数据刚流入系统的时候就被处理。用户也能够在几秒钟或者几分钟内获得结果,而不是要等待数小时或者数天。
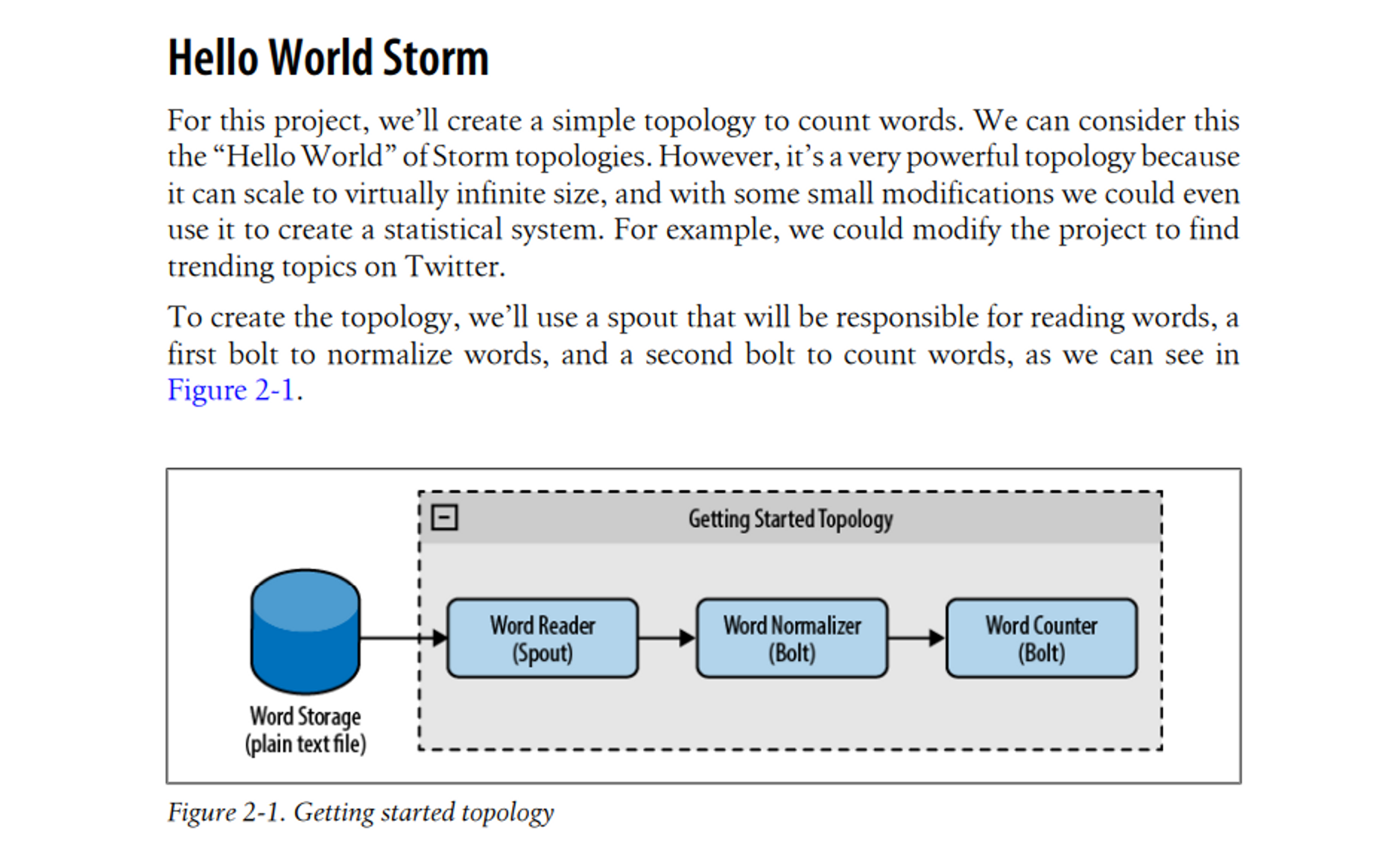
想要使用 Storm 做最简单的 work count 操作,用户也必须学许多 Storm 特有的概念。图片来源:书籍 “Getting started with Storm”
Storm 在当时是相当有突破性的。然而,早期 Storm 的设计远远没有达到用户预期的完美:它所要求的编程方式过于复杂,并缺少很多现代流处理系统中默认提供的基本功能,例如状态管理、exactly-once 语义、动态扩缩容等等。当然也正是因为这些设计的不完美,才使得诸多才华横溢的工程师去搭建下一代流计算引擎。在 Storm 开源之后两三年内,我们鉴证了一批流计算引擎的诞生:Apache Spark Streaming,Apache Flink,Apache Samza,Apache Heron,Apache S4 等等。 而如今,Spark Streaming 与 Flink 成了非常成功的两个流计算引擎。
Apache Storm 之前的历史
如果你认为流处理系统的历史起源于 Storm 的诞生,那就错了。 事实上,流处理系统的历史远比很多人想象的精彩。不算特别意外的是,流处理这一概念来自于数据库圈。在 2002 年的数据库领域顶级会议 VLDB 上,布朗大学与 MIT 的学者发表了“Monitoring Streams – A New Class of Data Management Applications”论文,指出了流处理这一新的需求。在这篇文章中,作者提出,为了处理流数据,我们应该抛弃传统的“Human-Active, DBMS-Passive”传统数据库处理模式,而转向“DBMS-Active, Human-Passive”这一新型处理模式。也就是说,在新型的流处理系统中,数据库应该主动接收数据并触发查询,而人只需要被动接受结果即可。在学术界,最早的流处理系统叫做 Aurora,随后又有 Borealis、STREAM 等系统在同时代诞生。
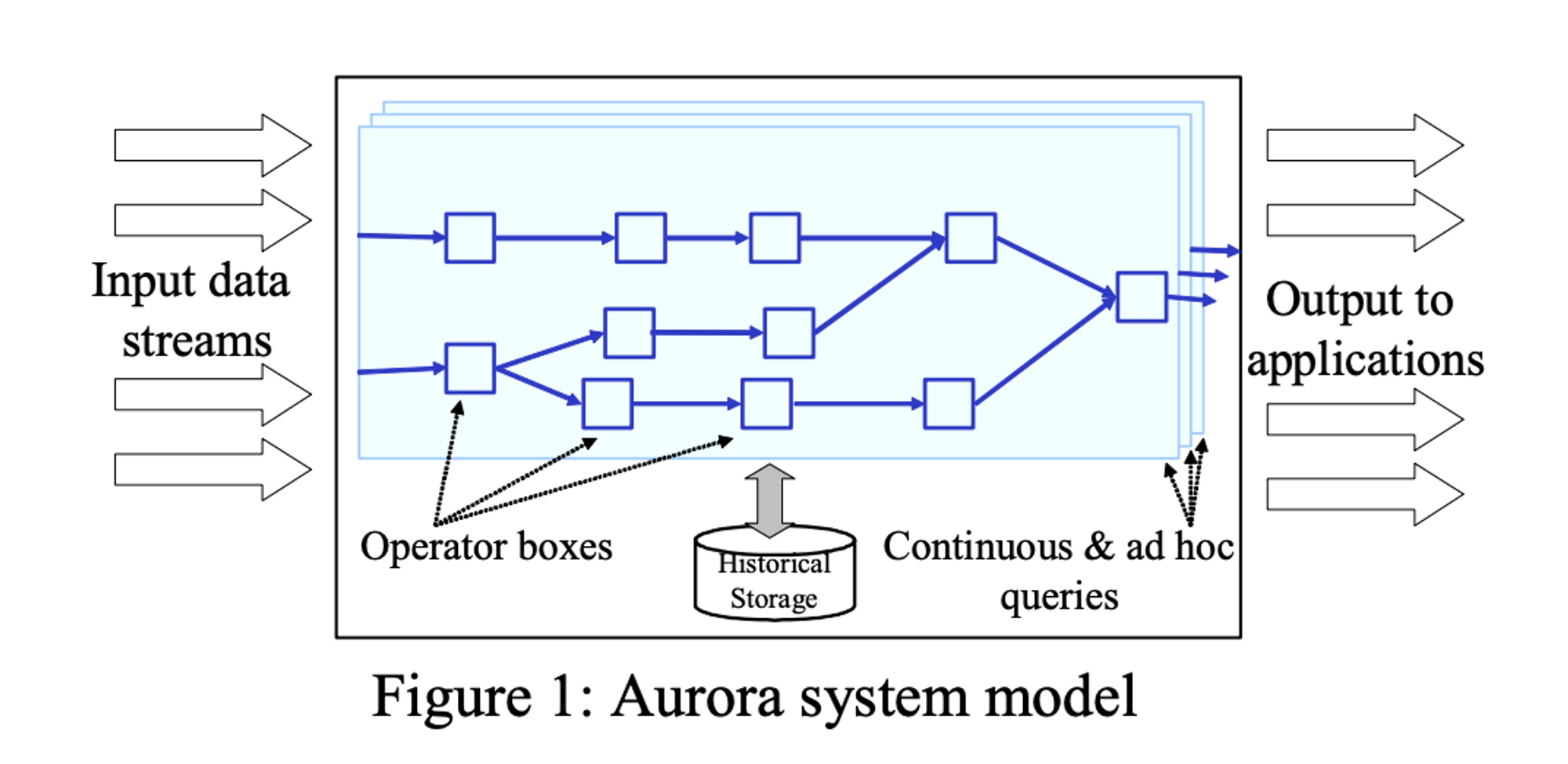
Aurora: 学术界的第一个流数据处理系统。
在被学术界提出的几年后,流处理技术便在大型数据库厂商中得到了应用。数据库领域的三大老牌厂商 Oracle、IBM、Microsoft 分别推出了他们自己的流处理解决方案,分别称为 Oracle CQL、IBM System S、Microsoft SQL Sever StreamInsight。非常一致的是,三个厂商都选择了在自己现有系统中集成流处理功能,而非将流处理功能单独拿出来开发成独立系统。
2002 年至今:到底什么被改变了?
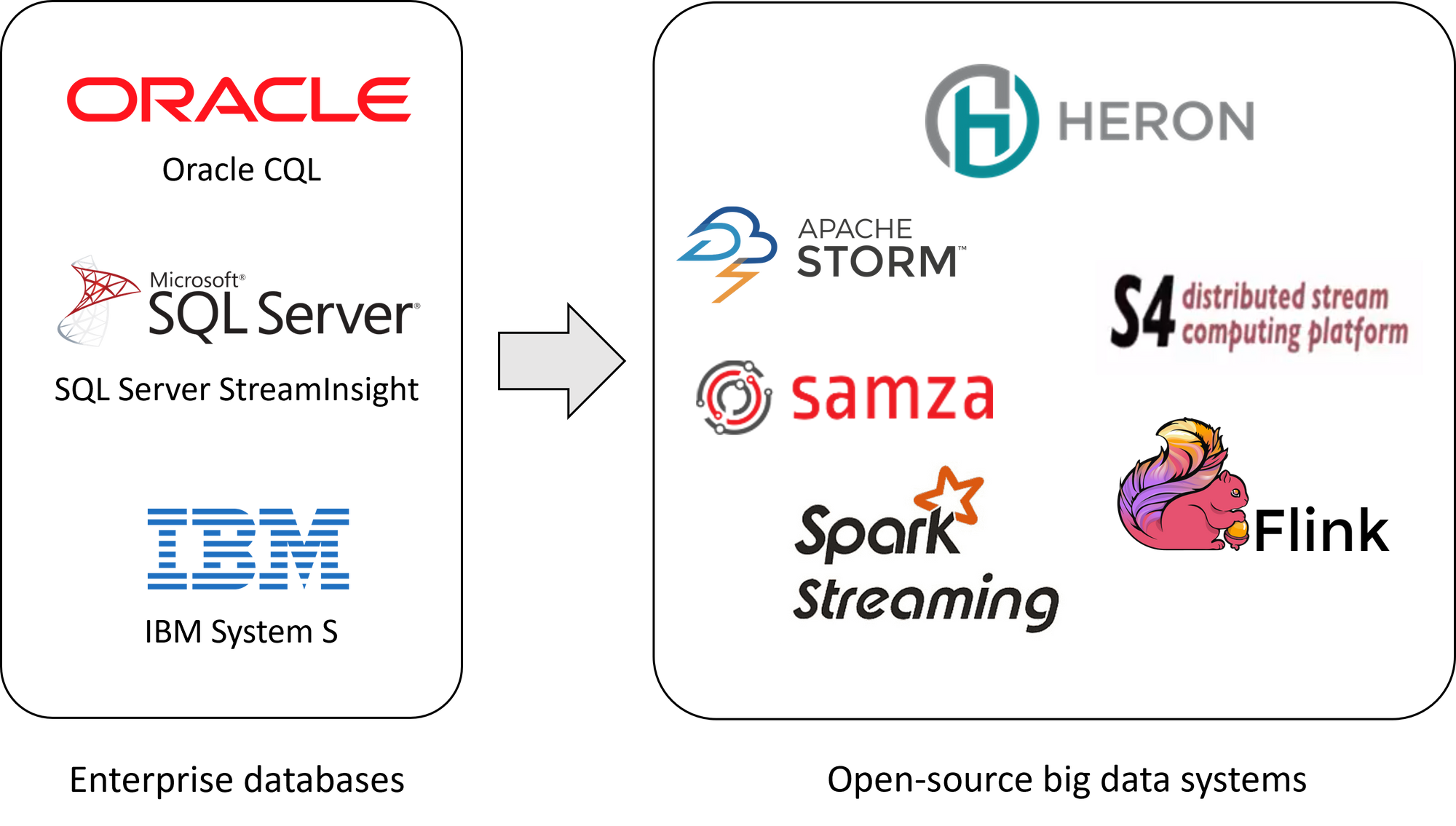
流处理系统的变革:从商业化数据库系统的一个功能组件转变成独立的开源大数据系统。
通过以上的讨论,大家可以看到,在 2002 年第一个流处理系统 Aurora 在学术界诞生之后,很快被数据库巨头吸收进自身产品中。但在 2010 年前后,该领域出现了一个重大转变,那便是流处理模块被从数据库系统中独立出来,并单独发展成了完整的、可扩展的分布式流计算引擎。是什么造成了这一变革?我认为是与 Hadoop(或者说 MapReduce)的诞生与发展息息相关。在传统单机数据库世界中,计算与存储都被封装在同一个系统中。尽管这样可以大大简化系统架构,给用户单一接口进行操作,但这种架构无法很好的扩展到集群环境中。Hadoop 所统治的大数据时代的理念便是将计算与持久化存储分割成独立的系统(注意这里所说的“分割成独立的系统”跟人们时常讨论的“存算分离”还是有不少区别),并暴露底层接口给用户,依赖用户提供足够多的信息(例如并行度、partition key 等)来去做水平扩展。这样的模式完美的满足了工程师驱动的新一批互联网公司(如 Twitter、LinkedIn、Uber 等)的需求。我们现在看到的 Storm 及其之后的大数据流计算引擎,无一不是这种设计思路:只负责计算层、暴露底层接口、通过 partition 方式暴力使用资源进行无限扩展。很显然,Storm、Flink 所代表的大数据时代流计算引擎的发展规律,与 Hadoop、Spark 所代表的同一时代的批计算引擎的发展规律完全吻合。
流数据库的复兴
回望历史我们发现,流数据库这一概念在 20 多年前便已被提出并实现。然而,大数据时代所带来的巨大技术变革推动了 Storm、Flink、Spark Streaming 等一批流计算引擎的诞生与发展,并推翻了 Oracle、IBM、Microsoft 这三巨头在流处理技术上的垄断。历史总是螺旋形上升的。在批处理系统领域,我们看到了 Redshift、Snowflake、Clickhouse 等系统重新将人们从“计算引擎”拉回到“数据库“这一理念中来。同样,在流处理领域,我们也看到了如 RisingWave、Materialize 等流数据库的诞生。为什么会这样?我们在这一节详细分析。
PipelineDB 与 ksqlDB 的故事
随着 2011 年 Storm 开源之后,流计算引擎便进入了发展的快车道。但流数据库并没有就此销声匿迹。有两个知名流数据库系统就诞生在大数据时代中。一个名叫 PipelineDB,另一个名叫 ksqlDB。先不说技术,这两个系统在商业上有着不小的联系。PipelineDB 是于 2013 年创立,2014 年 PipelineDB 团队加入了硅谷知名孵化器 Y Combinator 孵化, 2019 年 PipelineDB 被 Apache Kafka 原创团队所成立的商业化公司 Confluent 收购。而 ksqlDB 正是由 Confluent 公司于 2016 年创立(其实最早是先做了 Kafka Stream)。PipelineDB 与 ksqlDB 尽管都是流数据库,但它们在技术路线上的选择截然不同。PipelineDB 是完全基于 PostgreSQL 的。更准确的说,PipelineDB 使用了 PostgreSQL 的扩展接口。也就是说,只要用户安装了 PostgreSQL,就可以像安装插件一样安装 PipelineDB。这一理念对用户非常友好:用户无需迁移自己的数据库,便可以使用 PipelineDB。PipelineDB 非常核心的卖点就是实时更新的物化视图。当用户将数据插入 PipelineDB 之后,用户所创建的物化视图上便会实时显示最新结果。KsqlDB 选择了与 Kafka 强耦合的策略:在 ksqlDB 中,计算的中间结果存储在 Kafka 中;节点之间的通信使用 Kafka。这种技术路线的优势与缺陷非常鲜明:其优势是高度复用成熟组件,大大降低开发成本,缺陷是强绑 Kafka,严重缺乏灵活性,使得系统的性能与可扩展性大打折扣。
PipelineDB 与 ksqlDB 从用户认可度来讲还是逊色于 Spark Streaming 与 Flink:PipelineDB 已于 2019 年被收购之后停止了更新,而 ksqlDB 由于强绑 Kafka 以及技术成熟度等原因,在 Kafka 生态以外并没有得到足够多的关注。而在最近(2023 年 1 月),Confluent 公司又收购了由 Flink 核心成员创立的 Flink 商业化公司 Immerok,并高调宣布会推出基于 Flink SQL 的计算平台。这使得 ksqlDB 未来在 Confluent 内部的地位变得更加扑朔迷离。
云原生流数据库的兴起
经历了 Hadoop、Spark 领导的大数据时代, 我们便来到了云时代。近年来,诸多云原生系统逐步超越并颠覆了其所对标的大数据系统。一个最为人所知的例子便是 Snowflake 的崛起。Snowflake 基于云构建出的存算分离的新一代云数据仓库形成了对 Impala 等上一代大数据系统的降维打击,在市场上实现了称霸。在流数据库领域,类似的事情可能会再次发生。RisingWave、Materialize、DeltaStream、TimePlus 等就是近几年涌现出来的云上流数据库。尽管商业化路线、技术路线等方面的选择有着各种差异,但它们的大方向都是希望为用户在云上提供流数据库服务。在云上构建流数据库,重点就在于如何使用云的架构来实现无限水平扩展与成本降低。如果能够很好的选择技术路线与产品方向,相信会逐步挑战上一代流处理系统(如 Flink 与 Spark Streaming)的地位。
流计算引擎与流数据库
上面两段简述了流数据库在最近几年的兴起。相信大家都能够看出云原生是个趋势,但为什么大家在云上构建的是“云原生流数据库”,而不是“云原生流计算引擎”?
也许有人会认为是 SQL 的影响。云服务带来的一大变革便是普及数据系统的使用。在大数据时代,系统用户基本都是工程师,他们熟悉 Java 等编程语言进行应用开发。而云服务的兴起急需系统提供一种简单易懂的语言使广大没有编程基础的工作者受益。SQL 这种标准化的数据库语言很显然满足了这个需求。看起来,SQL 的广泛应用推动了“数据库”这个概念在流处理领域的普及。然而,SQL 只是间接因素,而非直接因素。证据很清晰:诸多流计算引擎(如 Flink 与 Spark Streaming)已经提供了 SQL 接口。尽管这些系统的 SQL 接口与 MySQL、PostgreSQL 等传统数据库的 SQL 使用体验有极大区别,但至少证明了有 SQL 不一定代表要有数据库。
我们回看“流数据库”与“流计算引擎”的区别,会发现流数据库拥有自的存储,而流计算引擎并没有。在这一表象底下更加深层的理念是:流数据库将存储视为一等公民(first-class citizen)。这一理念使得流数据库很好的满足了用户的两个最根本需求:简单、好用。这是如何做到呢?我们列举以下几个方面。
- **统一数据操作对象。**在流计算引擎中,流(stream)是基本的数据操作对象;在数据库中,表(table)是基本的数据操作对象。在流数据库中,流与表的概念得到了完美的统一:用户不再需要考虑流与表的区别,而是可以把流看做是无限大小的表,并使用操作传统数据库的方式对表这个概念进行处理。
- 简化用户数据栈。相比于流计算引擎,流数据库拥有了对数据的所有权:用户可以直接将数据存储在表中。当用户通过流数据库处理完数据之后,可以直接将处理后的结果存储在同一系统中,供用户进行并发访问。而由于流计算引擎无法存储数据,这就意味着其进行计算之后,必须将结果导出到 key-value store 或缓存系统中,才能供用户访问。这也就是说,用户可以使用单一的流数据库系统替换掉之前 Flink+Cassandra/DynamoDB 等服务组合。简化用户的数据栈,削减运维成本,这很显然是很多公司期待的。
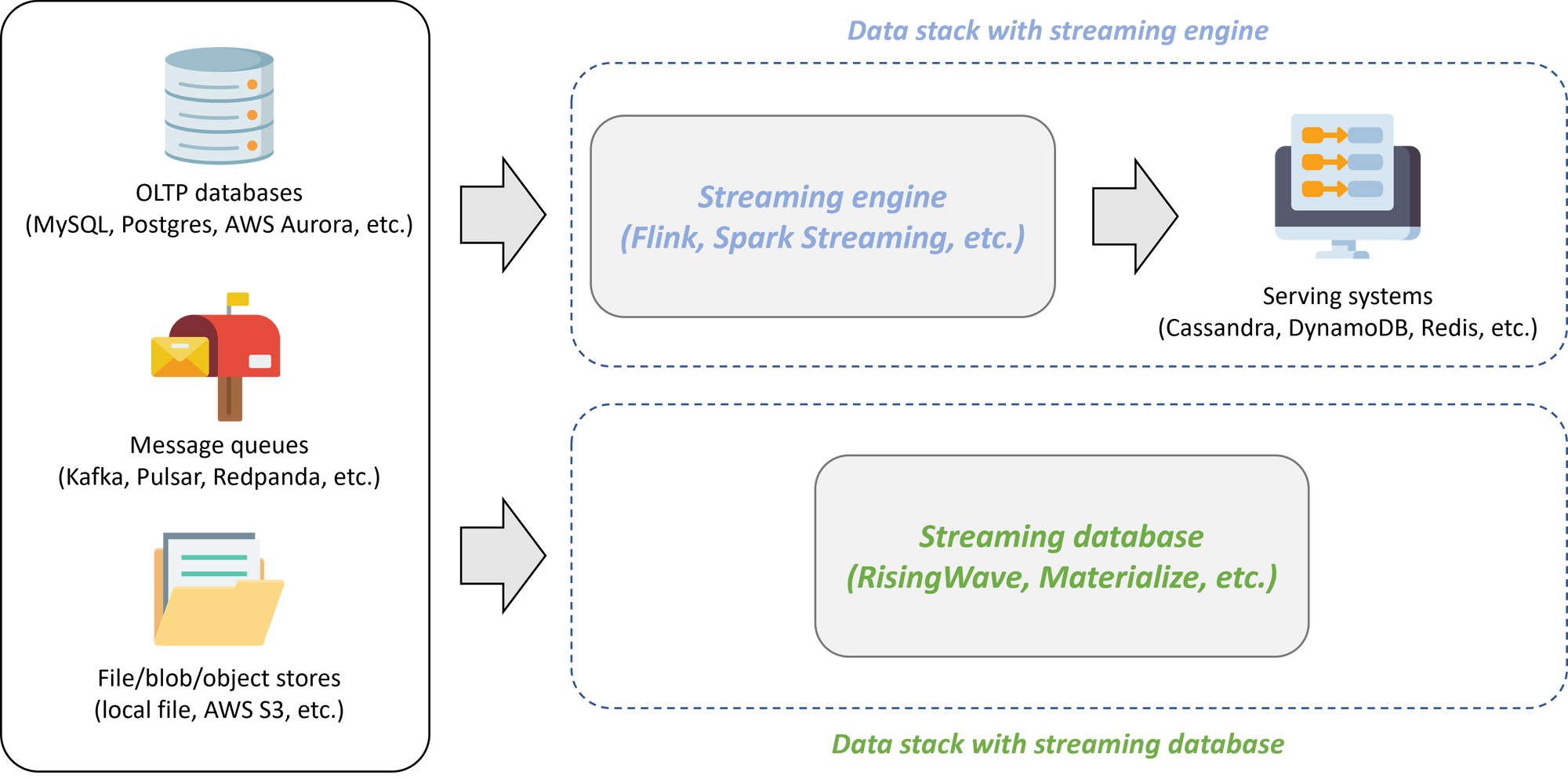
流数据库这一系统可以替代流计算引擎+服务系统这一系统组合。
- **减少外部访问开销。**现代企业的数据源是多样的。当使用流处理系统的时候,用户往往需要访问外部系统数据(考虑要将 Kafka 导出的数据流与 MySQL 中的一个表做 join)。对于流计算引擎来说,要想访问 MySQL 中的数据,必须进行一次跨系统外部调用。这种调用造成的性能代价是巨大的。当流数据库拥有存储数据的能力之后,很显然能将外部系统中的数据保存(或缓存)在流数据库内部,从而大幅提升数据访问性能。
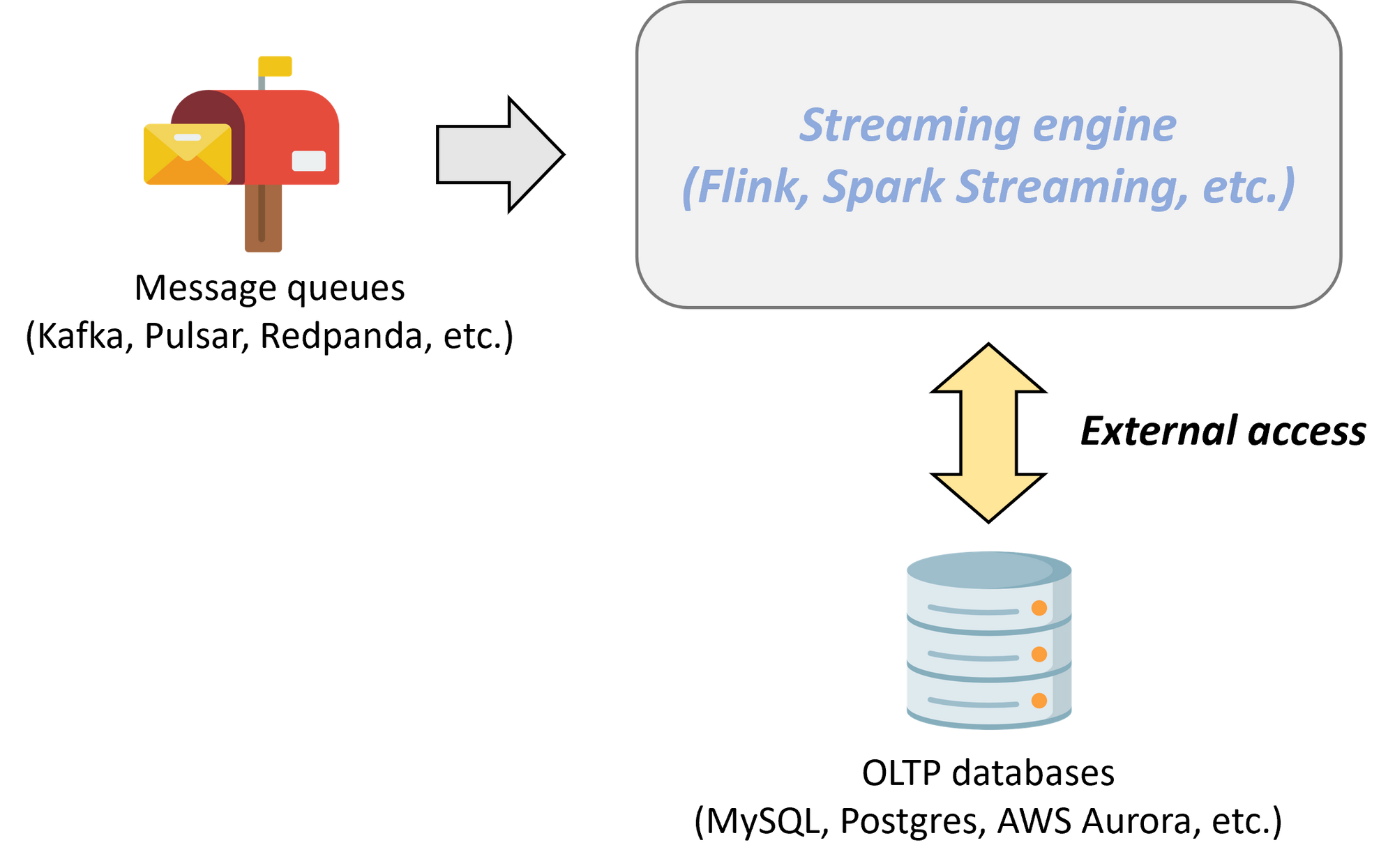
在流计算引擎中, 跨系统外部调用会造成巨大性能代价。
-
提供结果可解释性与一致性保证。流计算引擎的一大痛点在于计算结果缺乏可解释性与一致性保证。我们考虑一个非常简单的例子:用户使用 Flink 提交了两个 job,一个是求过去十分钟内 Tesla 股票的被买入次数,另一个是求过去十分钟内 Tesla 股票的被卖出次数。在 Flink 中,不同 job 独立运行,两个 job 不断向下游系统输出结果。由于流计算引擎的计算进度不同、输入输出不被系统管理,导致下游系统接收到的两个结果缺乏一致性(比如一个可能是 8 点 10 分的结果,另一个可能是 8 点 11 分的结果),也无法被溯源。看到这样的结果,用户是非常困惑的:他们无法判断结果是否正确、如何得出、如何演变。而当流数据库可以拥有对输入、输出数据的所有权之后,系统的计算行为从理论来说都变得可观测、可解释、强一致了。毕竟,在流数据库中,一切计算的输入数据都可以被存储到表中并打上时间戳,一切计算产生的结果都可以保存在物化视图中并通过时间戳溯源。这样,用户就可以很好的理解计算结果了。当然理论归理论,实际还得看系统是否实现。RisingWave 就是实现了这种强一致性并提供可解释性的系统之一。
-
**深度优化计算执行。**将“存储被视为一等公民”,意味着流数据库的计算层可以感知存储,而这种感知能力使得系统能够在查询优化层以及计算执行层进行大幅优化。一个简单的例子就是可以更好的共享计算状态节省资源开销。由于涉及大量技术细节,我们不在这里进行过多讨论,有兴趣的朋友可以参考其他一些文章:https://zhuanlan.zhihu.com/p/521759464。
云原生流数据库的设计准则
(这一节的讨论可能会显得无趣,因为已经有太多文章讨论过云原生系统的设计与实现了。大家可以选择跳过。)
云与集群的最大区别在于,云可以被认为是资源无限,且资源解耦;而集群是资源有限,且资源耦合。什么意思呢?第一,云上用户已经不再需要感知物理机器的数量:他们只需要付钱就可以获得他们想要的资源;而大数据时代的集群用户往往只拥有有限的物理机器;第二,云对用户暴露出来的是分类资源:用户可以根据需求单独购买计算、存储、缓存等资源。而大数据集群暴露出来的就是一台一台物理机器,用户只能是按机器数量来请求资源。第一点区别使得数据系统的设计目标发生了本质转变:大数据系统的目标是在有限资源内最大化系统性能,而云系统的目标是在无限资源内最小化成本开销;第二点区别则使得数据系统的实现方式发生了本质转变:大数据系统通过存算耦合的 shared-nothing 架构实现暴力并行,而云系统则通过存算分离的 shared-storage 架构实现按需伸缩。在流处理系统中,所谓中间计算结果即是存储。当中间计算结果需要从计算节点剥离出来放到 S3 等持久化云存储服务上时,大家会很自然的想到,S3 带来的数据访问延迟可能大幅影响流处理系统这种低延迟系统的性能。因此,云原生流处理系统不得不去考虑使用计算节点的本地存储以及外挂存储(如 EBS 等)去缓存数据,从而最大化减小 S3 访问带来的性能下降问题。

大数据系统与云系统的优化目标不同。
流处理还是批处理:替代还是共存?
流处理技术因其能够极大降低数据处理延迟,被很多人视为一种可以颠覆批处理的技术。当然也有另一种观点认为,大多数批处理系统都已经“升级”成实时分析系统,流处理系统的价值将非常有限。我自己投身于流处理技术的研发与商业化,自然对流处理的前景极度乐观。而我并不认同流处理与批处理会互相取代。在本章,我们详细探究流处理与批处理各自的独特之处。
流处理与实时分析
目前多数的批处理系统,包括 Snowflake、Redshift、Clickhouse 等,都宣称自己是实时分析系统,能够对数据进行实时大规模分析。我们在第一章也提到一个问题:对于数据分析场景,在已有许多实时分析系统的情况下,为什么还要用流处理系统?”我认为这完全是对所谓”实时“定义的不同。在流处理系统中,查询被用户事先定义,而查询处理由数据驱动;在实时分析系统中,查询由用户随时定义,而查询处理由用户驱动。流处理系统所说的“实时”是指系统对用户预定义的查询实时给出最新的结果,而实时分析系统所说的”实时“是指用户随时给出的查询实时给出结果。没看出来区别?那更简化一下,就是流处理系统强调计算结果的实时性,而实时分析系统强调用户交互的实时性。对于股票交易、广告计算、网络异常监控等对数据结果新鲜度要求很高的场景,流处理系统也许是最佳选择;而对于交互式自定义报表、用户行为日志查询等对用户交互式体验要求很高的场景,实时分析系统可能会更胜一筹。
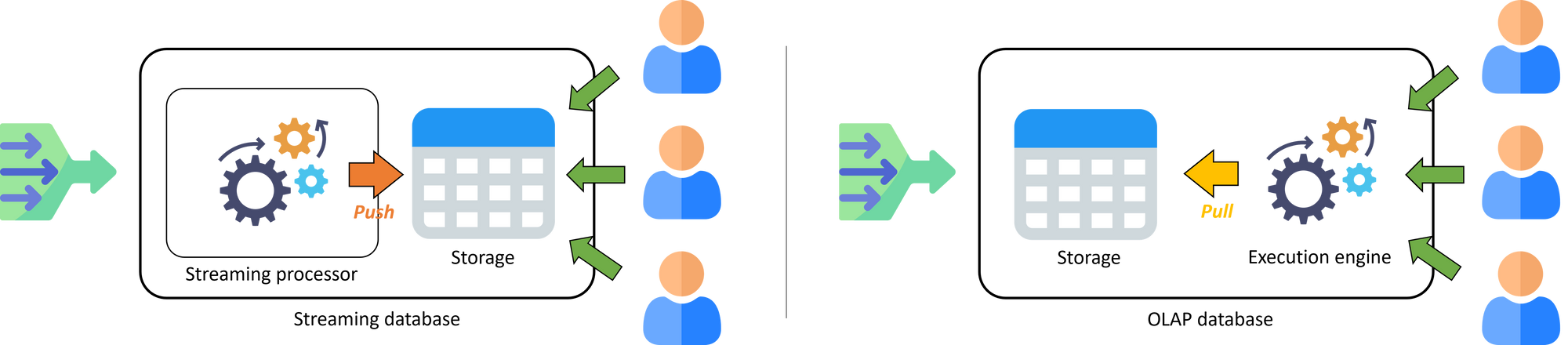
流数据库与实时分析数据库的区别。流数据库先计算后存储,计算由数据驱动,注重结果的实时性;实时分析数据库先存储后计算,计算由用户驱动,注重用户交互的实时性。
也许有人会说,既然实时分析系统能够对用户发送的查询实时给出结果,那么只要用户一直向实时分析系统中发送相同的查询,岂不是就能时刻保证结果的新鲜度,实现流处理系统的效果?这种想法有两个问题。第一个问题是实现复杂。用户毕竟不是机器,无法一直守在电脑前不间断的发送查询。想要实现这一效果无非只有两条路:要么是自己写程序定时发送查询,要么是自己运维编排工具(如 Airflow 等)循环发送查询。无论是哪条路,都意味着用户需要付出额外的代价运维外部系统(或程序)。第二个问题(也是最根本的问题)是成本过高。原因很简单:实时分析系统进行的是全量计算,而流处理系统进行的是增量计算。当所需处理的数据量较大时,实时分析系统不得不进行大量冗余的计算,带来巨量资源浪费。说到这里,相信大家应该也对之前本文第一章“为什么不拿个编排工具定时触发批处理系统做计算”这个问题有了答案。
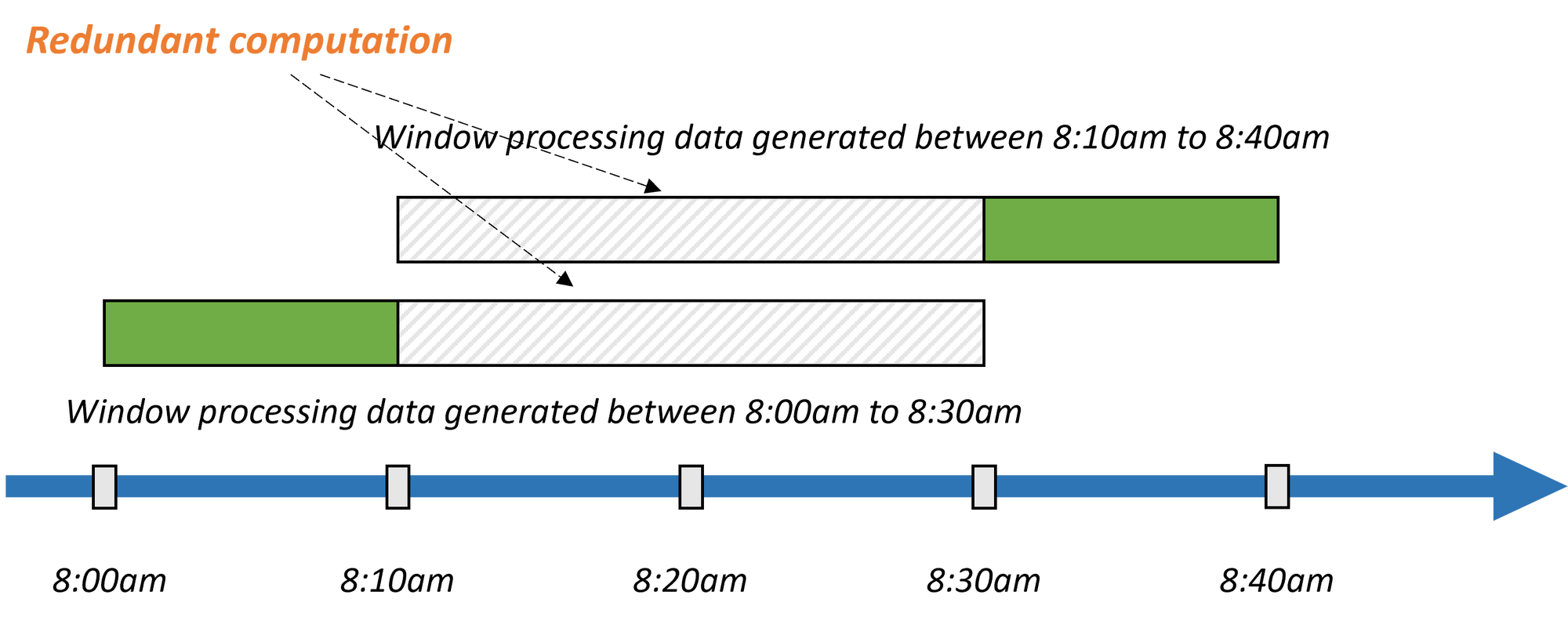
流处理系统采用增量计算方式避免不必要的重复计算。
流处理与实时物化视图
如今诸多实时分析系统都已经提供了实时物化视图功能,而实时物化视图就是流处理在数据库内的表达形式。有种观点认为,有了带有实时物化视图的分析系统,我们就不再需要需要单独的流处理系统。我认为这个观点并不成立。我们可以从以下几个方面考虑。
- **资源竞争。**分析型数据库要解决的核心问题是在大规模数据集上高效的对复杂查询进行处理。在这类系统中, 物化视图的定位本质上与数据库索引无异:都是计算的缓存。创建这样的缓存有两个好处:一方面,为经常处理的查询创建物化视图可以有效避免重复计算;另一方面,为不同查询的共享子查询创建物化视图可以加速查询执行。这样的定位实质上使得物化视图几乎不可能得到及时更新:积极主动的更新物化视图势必会持续抢占计算与内存资源,导致用户发送的查询得不到及时响应。为了防止这种“本末倒置”的事情发生,几乎所有分析性数据库采用的都是被动更新(也就是需要用户主动驱动)或是延迟更新(等到系统空闲时再更新)的方式。
- **正确性保证。**如果说资源竞争问题可以通过多加计算节点来解决,那么正确性问题就不是实时分析系统的物化视图能够解决的问题了。批处理系统处理的是有限有边界数据,而流处理系统处理的是无限无边界数据。在处理无边界数据时,由于网络通信等各种原因可能产生数据乱序问题。而流处理系统特别设计了水位线等概念来解决这一问题。当乱序数据只有当按照某一特定顺序至行之后,输出的结果才被认为是完全正确的。然而,实时分析系统缺少水位线等基础设计,这使得无法达到流处理系统所能达到的正确性。而这种正确性保证在各种流处理场景(比如风险控制、广告计算等)中至关重要。缺少了正确性保证的系统,自然无法替代流处理系统。
流处理的软肋
流处理并不是万能的,流处理也不无法彻底替代批处理。有几方面的原因。
- **灵活性。**流处理要求用户事先预定义好查询,从而来实现不间断的对最新数据进行实时计算。这一要求使得流处理在灵活性方面弱于批处理。正如本文之前所提到的,尽管流处理对查询相对固定的场景有很好的支持,但是当面对需要与用户频繁交互的场景时,批处理系统会更加适合。
- **表达性。**我们在上文提到,流处理使用增量计算的方式通过避免冗余计算来减小资源开销。但增量计算也带来了一大问题,就是系统的表达性受限。主要原因就是并非所有计算都能够被增量的处理。一个很简单的例子就是求中位数:并没有增量算法保证精确求出中位数值。因此,当面对一些及其复杂的场景时,流处理系统难以胜任。
- **计算成本。**流处理可以大幅降低实时计算的成本。但这并不意味着,流处理在任何场景下都能够比批处理更具成本优势。事实上,在对计算结果新鲜度不敏感的场景中(比如财务报表统计等),批处理才能更加节约成本。这是因为,为了在数据进入系统时便进行增量计算,流处理系统不得不持续维护计算状态,消耗资源。相比之下,批处理在只有用户请求到达时才进行计算,自然在无需实时结果的场景下节省成本。
流处理与批处理的融合
讨论了这么多,相信大家也看出来,流处理与批处理各具特点,很难在全场景中实现完全替代。既然这两种处理模式会共存,那很自然有些人会想到在同一套系统中同时支持流处理与批处理。不少系统已经进行了一些探索,这里就包括了 Flink、Spark 等这类老牌大数据系统。尽管这些系统的流批一体方案已经在一些场景落地,但是从实际的市场接受度来看,至少目前来讲,大多数用户仍然选择分别部署流处理、批处理两套系统。这其中不仅包含性能、稳定性的考量,同时也能在功能上各取所长:既保证了实时性,又同时能对归档数据运行复杂的 AI 算法、ad-hoc 分析等等。
目前阶段, RisingWave 还是更加专注于流处理本身,但也会通过 Sink、开放格式以及第三方 connector 等方式,方便用户使用第三方实时分析系统进行数据分析。事实上,在现在的 RisingWave 版本中,用户可以很轻松的将数据导出到 Snowflake、Redshift、Spark、ClickHouse 等系统中。我认可流批一体方案的意义,从长期来讲,RisingWave 也会进行这方面的探索。实际上,流数据库就是在做流处理与批处理的统一:当有新的数据流入流数据库时,流数据库就进行流计算;当有用户发起随机查询请求时,流数据库就进行批计算。至于内部实现如何,本文就不再展开赘述了,我们可以开一篇新文章详细探讨流批一体的设计。
后记
在文章最开始的时候,我提到自己已经在流处理领域做了 11 年的时间。然而,在 2015 到 2016 年的时候,我一度认为流处理的这座大厦已经建成,剩下的工作仅是小修小补。那时的我并没有想到,云计算的快速发展与普及让流处理系统在 2020 年之后重新回到了舞台的正中央,越来越多的人正在研究、开发、使用这一技术。本文是我最近几个月结合技术与商业化对流处理进行的思考。希望能够抛砖引玉,欢迎大家一起讨论!