
Beam
Apache Beam
在大数据的浪潮之下,技术的更新迭代十分频繁。受技术开源的影响,大数据开发者提供了十分丰富的工具。但也因为如此,增加了开发者选择合适工具的难度。在大数据处理一些问题的时候,往往使用的技术是多样化的。这完全取决于业务需求,比如进行批处理的 MapReduce,实时流处理的 Flink,以及 SQL 交互的 Spark SQL 等等。而把这些开源框架,工具,类库,平台整合到一起,所需要的工作量以及复杂度,可想而知。这也是大数据开发者比较头疼的问题。
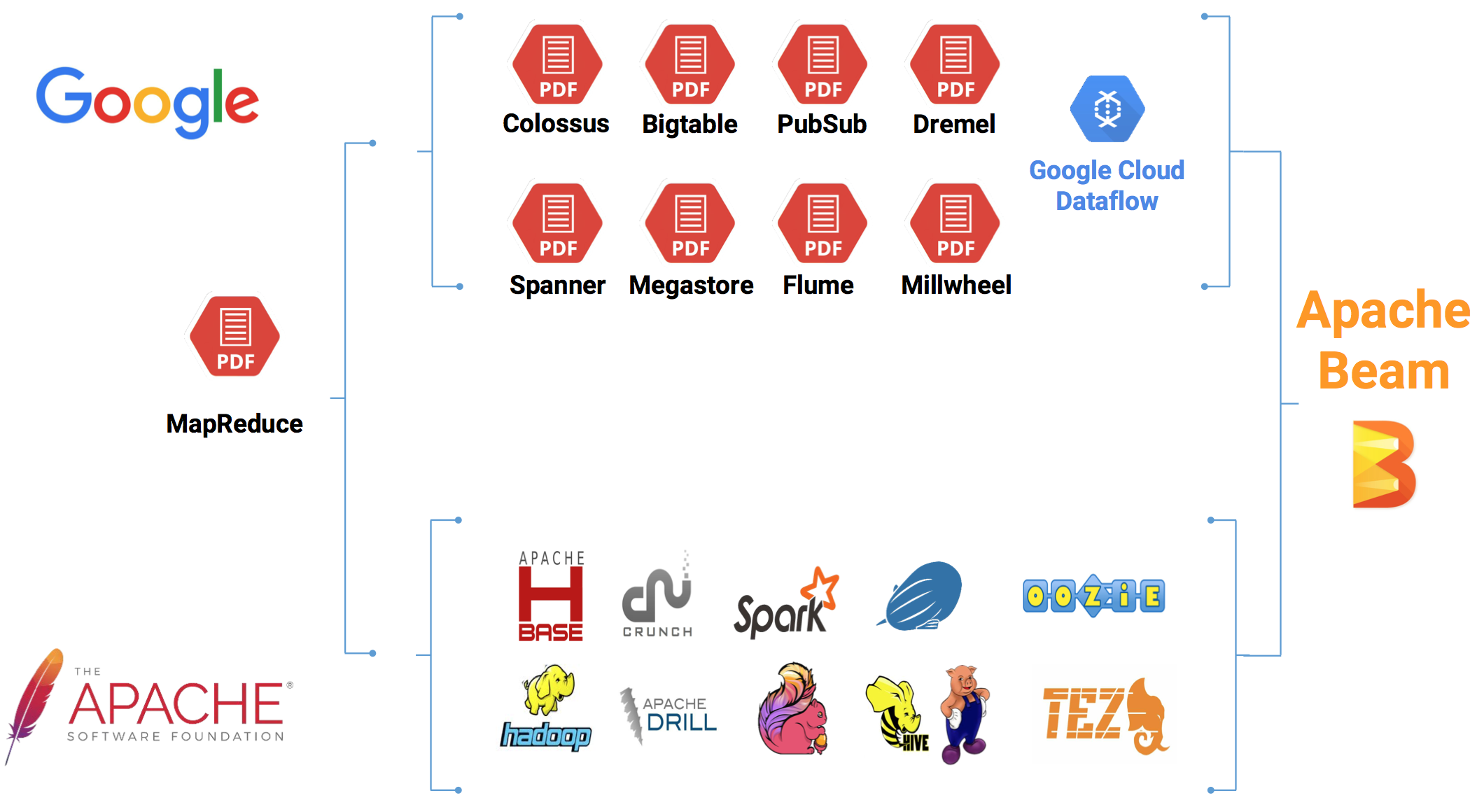
Apache Beam 最初叫 Apache Dataflow,由谷歌和其合作伙伴向 Apache 捐赠了大量的核心代码,并创立孵化了该项目。该项目的大部分大码来自于 Cloud Dataflow SDK,其特点有以下几点:
- 统一数据批处理(Batch)和流处理(Stream)编程的范式
- 能运行在任何可执行的引擎之上
整个技术的发展流向;一部分是谷歌派系,另一部分则是 Apache 派系。在开发大数据应用时,我们有时候使用谷歌的框架,API,类库,平台等,而有时候我们则使用 Apache 的,比如:HBase,Flink,Spark 等。而我们要整合这些资源则是一个比较头疼的问题,Apache Beam 的问世,整合这些资源提供了很方便的解决方案。

Beam SDK 提供了一个统一的编程模型,来处理任意规模的数据集,其中包括有限的数据集,无限的流数据。Apache Beam SDK 使用相同的类来表达有限和无限的数据,同样使用相同的转换方法对数据进行操作。Beam 提供了多种 SDK,你可以选择一种你熟悉的来建立数据处理管道,如上述的图,我们可以知道,目前 Beam 支持 Java,Python 以及其他待开发的语言。
在 Beam 管道上运行引擎会根据你选择的分布式处理引擎,其中兼容的 API 转换你的 Beam 程序应用,让你的 Beam 应用程序可以有效的运行在指定的分布式处理引擎上。因而,当运行 Beam 程序的时候,你可以按照自己的需求选择一种分布式处理引擎。当前 Beam 支持的管道运行引擎有以下几种:Apache Apex,Apache Flink,Apache Spark,Google Cloud Dataflow。