
01.MPP
MPP
数仓构建包括模型定义和预计算两部分,数据工程师根据业务分析需要,使用星型或雪花模型设计数据仓库结构,利用数据仓库中间件完成模型构建和更新。一个普遍的共识是,没有一个 OLAP 引擎能同时在数据量,灵活性和性能这三个方面做到完美,用户需要基于自己的需求进行取舍和选型。预计算模式的 OLAP 引擎在查询响应时间上相较于 MPP 引擎(Impala、SparkSQL、Presto 等)有一定优势,但相对限制了灵活性。
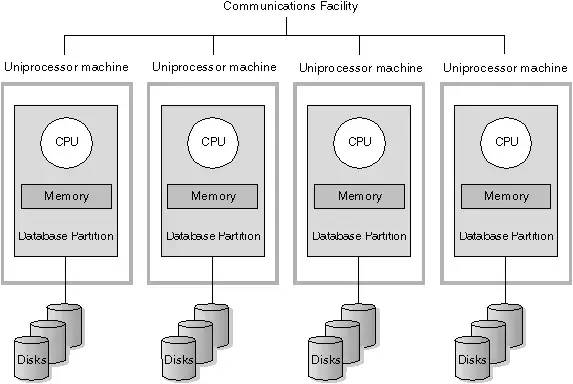
MPP 即大规模并行处理(Massively Parallel Processor)。在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据 库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
案例
-
Greenplum 是一种基于 PostgreSQL 的分布式数据库。其采用 shared nothing 架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享。也就是每个节点都是一个单独的数据库。节点之间的信息交互是通过节点互联网络实现。通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。这个就像是把小数据库组织起来,联合成一个大型数据库。将数据分片,存储在每个节点上。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
-
ElasticSearch 也是一种 MPP 架构的数据库,Presto、Impala 等都是 MPP engine,各节点不共享资源,每个 executor 可以独自完成数据的读取和计算,缺点在于怕 stragglers,遇到后整个 engine 的性能下降到该 straggler 的能力,所谓木桶的短板,这也是为什么 MPP 架构不适合异构的机器,要求各节点配置一样。Spark SQL 应该还是算做 Batching Processing, 中间计算结果需要落地到磁盘,所以查询效率没有 MPP 架构的引擎(如 Impala)高。
预计算/预聚合
开源领域,Apache Kylin 是预聚合模式 OLAP 代表,支持从 HIVE、Kafka、HDFS 等数据源加载原始表数据,并通过 Spark/MR 来完成 CUBE 构建和更新。
Druid 则是另一类预聚合 OLAP 的代表。在 Druid 的表结构模型中,分为时间列、维度列和指标列,允许对任意指标列进行聚合计算而无需定义维度数量。Druid 在数据存储时便可对数据进行聚合操作,这使得其更新延迟可以做到很低。在这些方面,Baidu 开源的 Palo 和 Druid 有类似之处。