
BIO
BIO
BIO 即同步阻塞式 IO,是面向流的,阻塞式的,串行的一个过程。对每一个客户端的 socket 连接,都需要一个线程来处理,而且在此期间这个线程一直被占用,直到 socket 关闭。
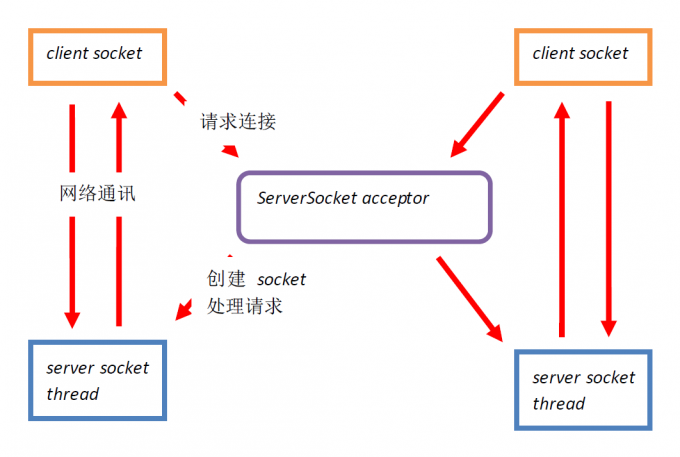
采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接,接收到客户端连接之后为客户端连接创建一个新的线程处理请求消息,处理完成之后,返回应答消息给客户端,线程销毁,这就是典型的一请求一应答模型。该架构最大的问题就是不具备弹性伸缩能力,当并发访问量增加后,服务端的线程个数和并发访问数成线性正比,由于线程是 Java 虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统的性能急剧下降,随着并发量的继续增加,可能会发生句柄溢出、线程堆栈溢出等问题,并导致服务器最终宕机。
还有一些并不是由于并发数增加而导致的系统负载增加:连接服务器的一些客户端,由于网络或者自身性能处理的问题,接收端从 socket 读取数据的速度跟不上发送端写入数据的速度。而在 TCP/IP 网络编程过程中,已经发送出去的数据依然需要暂存在 send buffer,只有收到对方的 ack,kernel 才从 buffer 中清除这一部分数据,为后续发送数据腾出空间。接收端将收到的数据暂存在 receive buffer 中,自动进行确认。但如果 socket 所在的进程不及时将数据从 receive buffer 中取出,最终导致 receive buffer 填满,由于 TCP 的滑动窗口和拥塞控制,接收端会阻止发送端向其发送数据。作为发送端,服务器由于迟迟不能释放被占用的线程,导致内存占用率不断升高,堆回收的效率越来越低,导致 Full GC,最终导致服务宕机。
多进程/多线程模式
BIO 的一个缺陷在于某个 Socket 在其连接到断上期间会独占线程,那么解决这个问题的一个朴素想法就是利用多进程多线程的办法,即是创建一个新的线程来处理新的连接,这样就保证了并发 IO 的实现。最早的服务器端程序都是通过多进程、多线程来解决并发 IO 的问题。进程模型出现的最早,从 Unix 系统诞生就开始有了进程的概念。最早的服务器端程序一般都是 Accept 一个客户端连接就创建一个进程,然后子进程进入循环同步阻塞地与客户端连接进行交互,收发处理数据。

多线程模式出现要晚一些,线程与进程相比更轻量,而且线程之间是共享内存堆栈的,所以不同的线程之间交互非常容易实现。比如聊天室这样的程序,客户端连接之间可以交互,比聊天室中的玩家可以任意的其他人发消息。
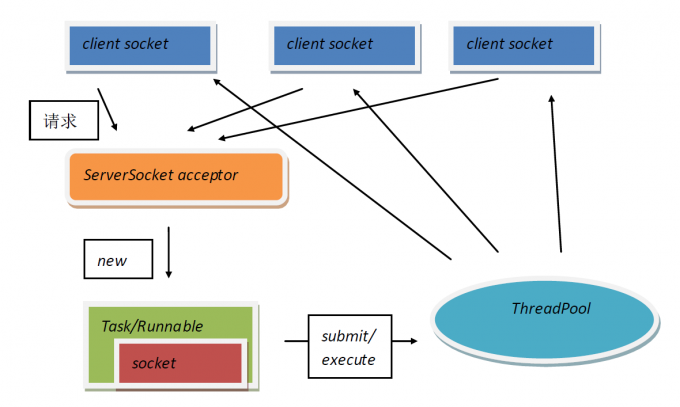
用多线程模式实现非常简单,线程中可以直接读写某一个客户端连接。而多进程模式就要用到管道、消息队列、共享内存实现数据交互,统称进程间通信(IPC)复杂的技术才能实现。
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(9696);
Socket socket = serverSocket.accept();
new Thread(() -> {
try {
byte[] byteRead = new byte[1024];
socket.getInputStream().read(byteRead);
String req = new String(byteRead, StandardCharsets.UTF_8);//encode
// do something
byte[] byteWrite = "Hello".getBytes(StandardCharsets.UTF_8);//decode
socket.getOutputStream().write(byteWrite);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
} catch (IOException e) {
e.printStackTrace();
}
}
多进程/线程模型的流程如下:
- 创建一个 socket,绑定服务器端口(bind),监听端口(listen),在 PHP 中用 stream_socket_server 一个函数就能完成上面 3 个步骤,当然也可以使用 php sockets 扩展分别实现。
- 进入 while 循环,阻塞在 accept 操作上,等待客户端连接进入。此时程序会进入随眠状态,直到有新的客户端发起 connect 到服务器,操作系统会唤醒此进程。accept 函数返回客户端连接的 socket
- 主进程在多进程模型下通过 fork(php: pcntl_fork)创建子进程,多线程模型下使用 pthread_create(php: new Thread)创建子线程。下文如无特殊声明将使用进程同时表示进程/线程。
- 子进程创建成功后进入 while 循环,阻塞在 recv(php: fread)调用上,等待客户端向服务器发送数据。收到数据后服务器程序进行处理然后使用 send(php: fwrite)向客户端发送响应。长连接的服务会持续与客户端交互,而短连接服务一般收到响应就会 close。
- 当客户端连接关闭时,子进程退出并销毁所有资源。主进程会回收掉此子进程。
Leader-Follow 模型
上文描述的多进程/多线程模型最大的问题是,进程/线程创建和销毁的开销很大。所以上面的模式没办法应用于非常繁忙的服务器程序。对应的改进版解决了此问题,这就是经典的 Leader-Follower 模型。

它的特点是程序启动后就会创建 N 个进程。每个子进程进入 Accept,等待新的连接进入。当客户端连接到服务器时,其中一个子进程会被唤醒,开始处理客户端请求,并且不再接受新的 TCP 连接。当此连接关闭时,子进程会释放,重新进入 Accept,参与处理新的连接。这个模型的优势是完全可以复用进程,没有额外消耗,性能非常好。很多常见的服务器程序都是基于此模型的,比如 Apache、PHP-FPM。多进程模型也有一些缺点。
- 这种模型严重依赖进程的数量解决并发问题,一个客户端连接就需要占用一个进程,工作进程的数量有多少,并发处理能力就有多少。操作系统可以创建的进程数量是有限的。
- 启动大量进程会带来额外的进程调度消耗。数百个进程时可能进程上下文切换调度消耗占 CPU 不到 1%可以忽略不接,如果启动数千甚至数万个进程,消耗就会直线上升。调度消耗可能占到 CPU 的百分之几十甚至 100%。
另外有一些场景多进程模型无法解决,比如即时聊天程序(IM),一台服务器要同时维持上万甚至几十万上百万的连接(经典的 C10K 问题),多进程模型就力不从心了。还有一种场景也是多进程模型的软肋。通常 Web 服务器启动 100 个进程,如果一个请求消耗 100ms,100 个进程可以提供 1000qps,这样的处理能力还是不错的。但是如果请求内要调用外网 Http 接口,像 QQ、微博登录,耗时会很长,一个请求需要 10s。那一个进程 1 秒只能处理 0.1 个请求,100 个进程只能达到 10qps,这样的处理能力就太差了。