
Namespaces
Namespaces
简单的讲就是,Linux Namespace 允许用户在独立进程之间隔离 CPU 等资源。进程的访问权限及可见性仅限于其所在的 Namespaces。因此,用户无需担心在一个 Namespace 内运行的进程与在另一个 Namespace 内运行的进程冲突。甚至可以同一台机器上的不同容器中运行具有相同 PID 的进程。同样的,两个不同容器中的应用程序可以使用相同的端口。

Namespaces 用于环境隔离,Linux kernel 支持的 Namespace 包括 UTS, IPC, PID, NET, NS, USER 以及新加入的 CGROUP 等,UTS 用于隔离主机名和域名,使用标识 CLONE_NEWUTS,IPC 用于隔离进程间通信资源如消息队列等,使用标识 CLONE_NEWIPC,PID 隔离进程,NET 用于隔离网络,NS 用于隔离挂载点,USER 用于隔离用户组。默认情况下,通过 clone 系统调用创建子进程的 namespace 与父进程是一致的,而你可以在 clone 系统调用中通过 flag 参数设置隔离的名字空间来隔离,当然也可以更加方便的直接用 unshare 命令来创建新的 namespace。查看一个进程的各 Namespace 命令如下:
root@host:/home/vagrant# ls -ls /proc/self/ns/
0 lrwxrwxrwx 1 root root 0 May 17 22:04 cgroup -> cgroup:[4026531835]
0 lrwxrwxrwx 1 root root 0 May 17 22:04 ipc -> ipc:[4026531839]
0 lrwxrwxrwx 1 root root 0 May 17 22:04 mnt -> mnt:[4026531840]
0 lrwxrwxrwx 1 root root 0 May 17 22:04 net -> net:[4026531957]
0 lrwxrwxrwx 1 root root 0 May 17 22:04 pid -> pid:[4026531836]
0 lrwxrwxrwx 1 root root 0 May 17 22:04 user -> user:[4026531837]
0 lrwxrwxrwx 1 root root 0 May 17 22:04 uts -> uts:[4026531838]
PID Namespace
在容器中,有自己的 Pid namespace,因此我们看到的只有 PID 为 1 的初始进程以及它的子进程,而宿主机的其他进程容器内是看不到的。通常来说,Linux 启动后它会先启动一个 PID 为 1 的进程,这是系统进程树的根进程,根进程会接着创建子进程来初始化系统服务。PID namespace 允许在新的 namespace 创建一棵新的进程树,它可以有自己的 PID 为 1 的进程。在 PID namespace 的隔离下,子进程名字空间无法知道父进程名字空间的进程,如在 Docker 容器中无法看到宿主机的进程,而父进程名字空间可以看到子进程名字空间的所有进程。如图所示:
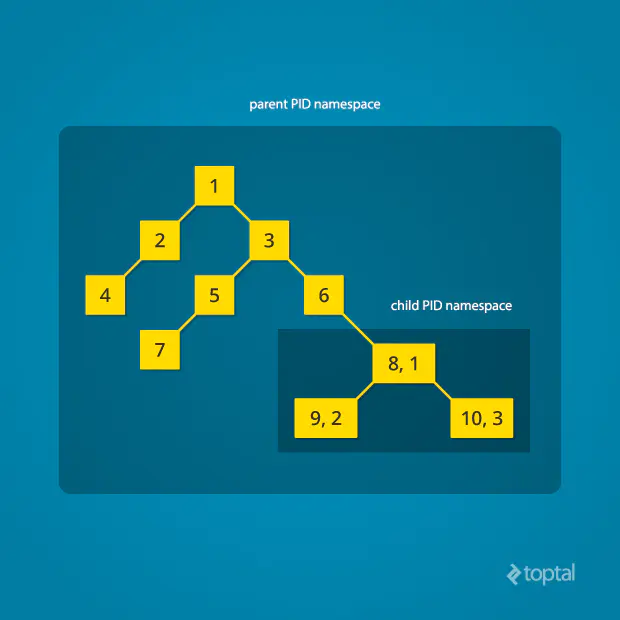
Linux 内核加入 PID Namespace 后,对 pid 结构进行了修改,新增的 upid 结构用于跟踪 namespace 和 pid。
## 加入PID Namespace之前的pid结构
struct pid {
atomic_t count; /* reference counter */
int nr; /* the pid value */
struct hlist_node pid_chain; /* hash chain */
...
};
## 加入PID Namespace之后的pid结构
struct upid {
int nr; /* moved from struct pid */
struct pid_namespace *ns;
struct hlist_node pid_chain; /* moved from struct pid */
};
struct pid {
...
int level; /* the number of upids */
struct upid numbers[0];
};
可以通过 unshare 测试下 PID namespace,可以看到新的 bash 进程它的 pid namespace 与父进程的不同了,而且它的 pid 是 1。
root@host:/home/vagrant# unshare --fork --pid bash
root@host:/home/vagrant# echo $$
1
root@host:/home/vagrant# ls -ls /proc/self/ns/
0 lrwxrwxrwx 1 root root 0 May 19 15:24 cgroup -> cgroup:[4026531835]
0 lrwxrwxrwx 1 root root 0 May 19 15:24 ipc -> ipc:[4026531839]
0 lrwxrwxrwx 1 root root 0 May 19 15:24 mnt -> mnt:[4026531840]
0 lrwxrwxrwx 1 root root 0 May 19 15:24 net -> net:[4026531957]
0 lrwxrwxrwx 1 root root 0 May 19 15:24 pid -> pid:[4026532232]
0 lrwxrwxrwx 1 root root 0 May 19 15:24 user -> user:[4026531837]
0 lrwxrwxrwx 1 root root 0 May 19 15:24 uts -> uts:[4026531838]
僵尸进程
容器的本质实际上是一个进程,是一个视图被隔离,资源受限的进程。容器里面 PID=1 的进程就是应用本身,这意味着管理虚拟机等于管理基础设施,因为我们是在管理机器,但管理容器却等于直接管理应用本身。这也是之前说过的不可变基础设施的一个最佳体现,这个时候,你的应用就等于你的基础设施,它一定是不可变的。
在容器中,1 号进程一般是 entry point 进程,针对上面这种将孤儿进程的父进程置为 1 号进程进而避免僵尸进程处理方式,容器是处理不了的。进而就会导致容器中在孤儿进程这种异常场景下僵尸进程无法彻底处理的窘境。所以说,容器的单进程模型的本质其实是容器中的 1 号进程并不具有管理多进程、多线程等复杂场景下的能力。如果一定在容器中处理这些复杂情况的,那么需要开发者对 entry point 进程赋予这种能力。这无疑是加重了开发者的心智负担,这是任何一项大众技术或者平台框架都不愿看到的尴尬之地。
例子里面有一个程序叫做 Helloworld,这个 Helloworld 程序实际上是由一组进程组成的,需要注意一下,这里说的进程实际上等同于 Linux 中的线程。因为 Linux 中的线程是轻量级进程,所以如果从 Linux 系统中去查看 Helloworld 中的 pstree,将会看到这个 Helloworld 实际上是由四个线程组成的,分别是 {api、main、log、compute}。也就是说,四个这样的线程共同协作,共享 Helloworld 程序的资源,组成了 Helloworld 程序的真实工作情况。这是操作系统里面进程组或者线程组中一个非常真实的例子,以上就是进程组的一个概念。
Helloworld 程序由四个进程组成,这些进程之间会共享一些资源和文件。那么现在有一个问题:假如说现在把 Helloworld 程序用容器跑起来,你会怎么去做?
当然,最自然的一个解法就是,我现在就启动一个 Docker 容器,里面运行四个进程。可是这样会有一个问题,这种情况下容器里面 PID=1 的进程该是谁? 比如说,它应该是我的 main 进程,那么问题来了,“谁”又负责去管理剩余的 3 个进程呢?
这个核心问题在于,容器的设计本身是一种“单进程”模型,不是说容器里只能起一个进程,由于容器的应用等于进程,所以只能去管理 PID=1 的这个进程,其他再起来的进程其实是一个托管状态。所以说服务应用进程本身就具有“进程管理”的能力。
比如说 Helloworld 的程序有 system 的能力,或者直接把容器里 PID=1 的进程直接改成 systemd,否则这个应用,或者是容器是没有办法去管理很多个进程的。因为 PID=1 进程是应用本身,如果现在把这个 PID=1 的进程给 kill 了,或者它自己运行过程中死掉了,那么剩下三个进程的资源就没有人回收了,这个是非常严重的一个问题。
反过来,如果真的把这个应用本身改成了 systemd,或者在容器里面运行了一个 systemd,将会导致另外一个问题:使得管理容器不再是管理应用本身了,而等于是管理 systemd,这里的问题就非常明显了。比如说我这个容器里面 run 的程序或者进程是 systemd,那么接下来,这个应用是不是退出了?是不是 fail 了?是不是出现异常失败了?实际上是没办法直接知道的,因为容器管理的是 systemd。这就是为什么在容器里面运行一个复杂程序往往比较困难的一个原因。
这里再帮大家梳理一下:由于容器实际上是一个“单进程”模型,所以如果你在容器里启动多个进程,只有一个可以作为 PID=1 的进程,而这时候,如果这个 PID=1 的进程挂了,或者说失败退出了,那么其他三个进程就会自然而然的成为孤儿,没有人能够管理它们,没有人能够回收它们的资源,这是一个非常不好的情况。
注意:Linux 容器的“单进程”模型,指的是容器的生命周期等同于 PID=1 的进程(容器应用进程)的生命周期,而不是说容器里不能创建多进程。当然,一般情况下,容器应用进程并不具备进程管理能力,所以你通过 exec 或者 ssh 在容器里创建的其他进程,一旦异常退出(比如 ssh 终止)是很容易变成孤儿进程的。
反过来,其实可以在容器里面 run 一个 systemd,用它来管理其他所有的进程。这样会产生第二个问题:实际上没办法直接管理我的应用了,因为我的应用被 systemd 给接管了,那么这个时候应用状态的生命周期就不等于容器生命周期。这个管理模型实际上是非常非常复杂的。
NS Namespace
NS Namespace 用于隔离挂载点,不同 NS Namespace 的挂载点互不影响。创建一个新的 Mount Namespace 效果有点类似 chroot,不过它隔离的比 chroot 更加完全。这是历史上的第一个 Linux Namespace,由此得到了 NS 这个名字而不是用的 Mount。
在最初的 NS Namespace 版本中,挂载点是完全隔离的。初始状态下,子进程看到的挂载点与父进程是一样的。在新的 Namespace 中,子进程可以随意 mount/umount 任何目录,而不会影响到父 Namespace。使用 NS Namespace 完全隔离挂载点初衷很好,但是也带来了某些情况下不方便,比如我们新加了一块磁盘,如果完全隔离则需要在所有的 Namespace 中都挂载一遍。为此,Linux 在 2.6.15 版本中加入了一个 shared subtree 特性,通过指定 Propagation 来确定挂载事件如何传播。比如通过指定 MS_SHARED 来允许在一个 peer group(子 namespace 和父 namespace 就属于同一个组)共享挂载点,mount/umount 事件会传播到 peer group 成员中。使用 MS_PRIVATE 不共享挂载点和传播挂载事件。其他还有 MS_SLAVE 和 NS_UNBINDABLE 等选项。可以通过查看 cat /proc/self/mountinfo 来看挂载点信息,若没有传播参数则为 MS_PRIVATE 的选项。
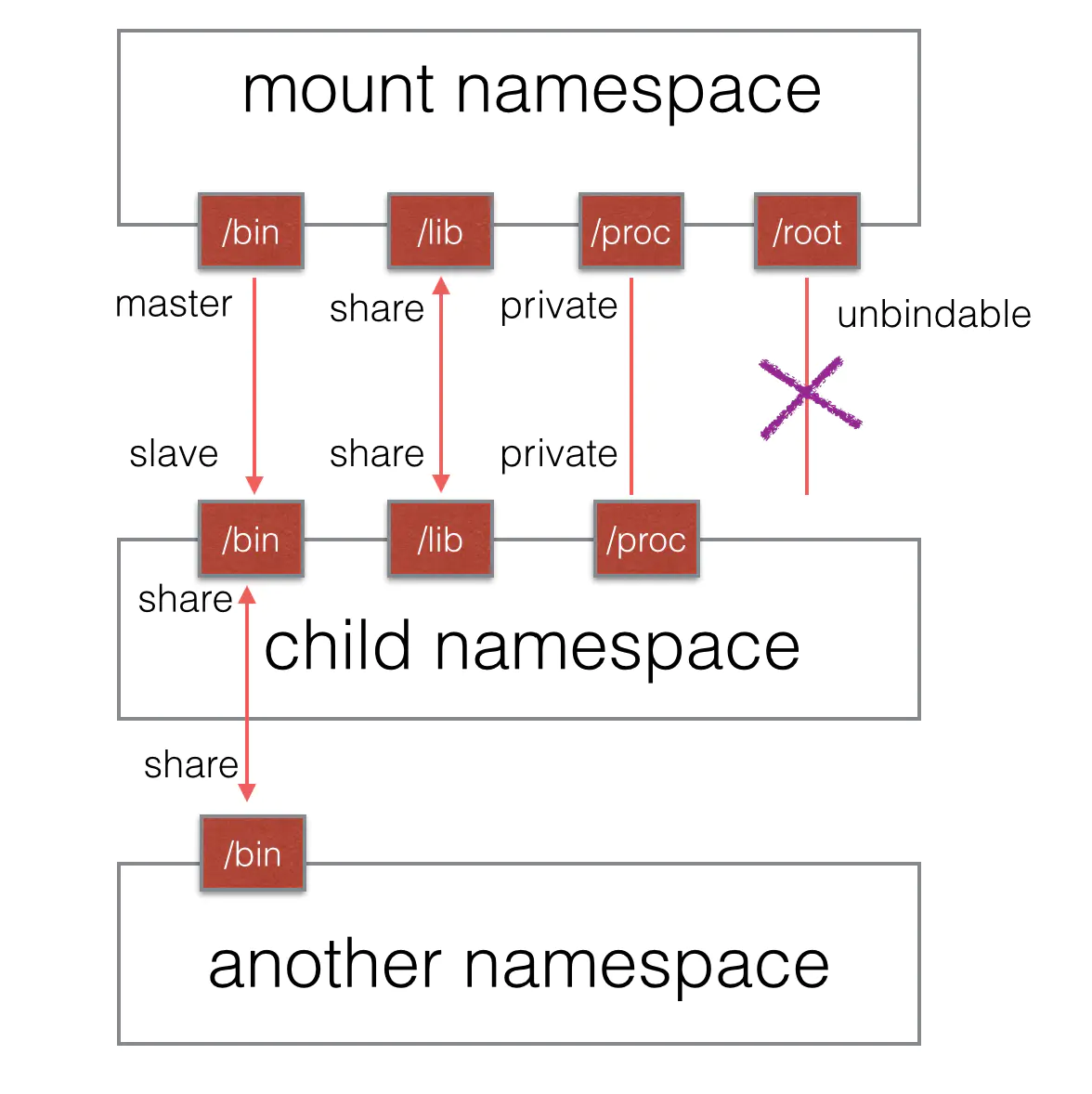
例如你在初始 namespace 有两个挂载点,通过 mount –make-shared /dev/sda1 /mntS 设置/mntS 为 shared 类型,mount –make-private /dev/sda1 /mntP 设置/mntP 为 private 类型。当你使用 unshare -m bash 新建一个 namespace 并在它们下面挂载子目录时,可以发现/mntS 下面的子目录 mount/umount 事件会传播到父 namespace,而/mntP 则不会。
在前面例子 Pid namespace 隔离后,我们在新的名字空间执行 ps -ef 可以看到宿主机进程,这是因为 ps 命令是从 /proc 文件系统读取的数据,而文件系统我们还没有隔离,为此,我们需要在新的 NS Namespace 重新挂载 proc 文件系统来模拟类似 Docker 容器的功能。
root@host:/home/vagrant# unshare --pid --fork --mount-proc bash
root@host:/home/vagrant# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 15:36 pts/1 00:00:00 bash
root 2 1 0 15:36 pts/1 00:00:00 ps -ef
可以看到,隔离了 NS namespace 并重新挂载了 proc 后,ps 命令只能看到 2 个进程了,跟我们在 Docker 容器中看到的一致。
NET Namespace
Docker 容器中另一个重要特性是网络独立(之所以不用隔离一词是因为容器的网络还是要借助宿主机的网络来通信的),使用到 Linux 的 NET Namespace 以及 vet。veth 主要的目的是为了跨 NET namespace 之间提供一种类似于 Linux 进程间通信的技术,所以 veth 总是成对出现,如下面的 veth0 和 veth1。它们位于不同的 NET namespace 中,在 veth 设备任意一端接收到的数据,都会从另一端发送出去。veth 实现了不同 namespace 的网络数据传输。
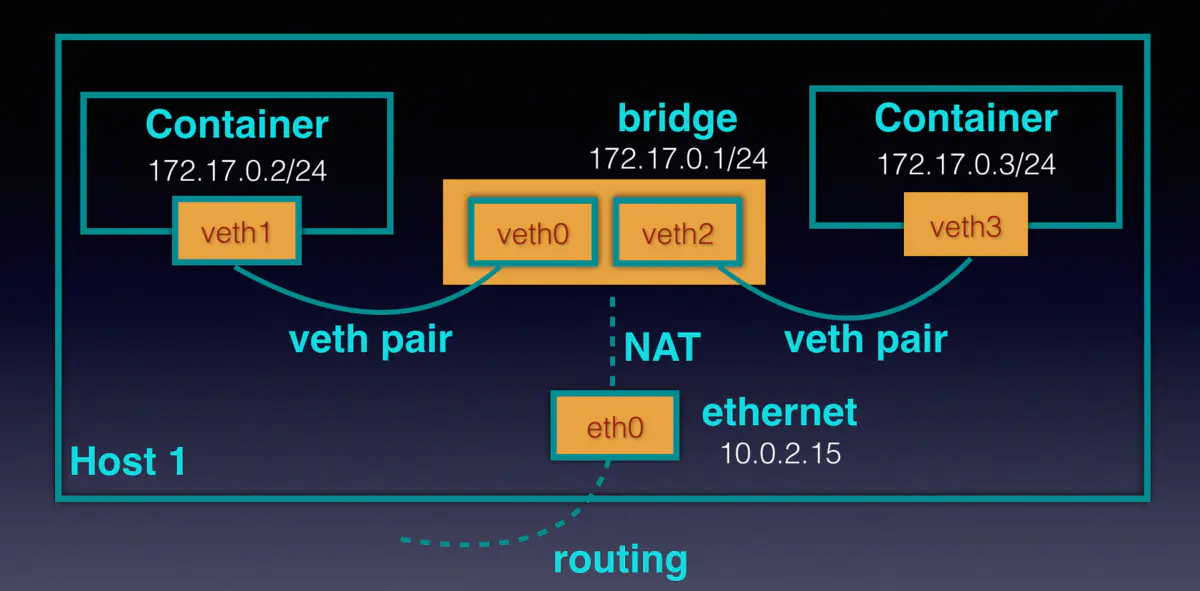
在 Docker 中,宿主机的 veth 端会桥接到网桥中,接收到容器中的 veth 端发过来的数据后会经由网桥 docker0 再转发到宿主机网卡 eth0,最终通过 eth0 发送数据。当然在发送数据前,需要经过 iptables MASQUERADE 规则将源地址改成宿主机 ip,这样才能接收到响应数据包。而宿主机网卡接收到的数据会通过 iptables DNAT 根据端口号修改目的地址和端口为容器的 ip 和端口,然后根据路由规则发送到网桥 docker0 中,并最终由网桥 docker0 发送到对应的容器中。
Docker 里面网络模式分为 bridge,host,overlay 等几种模式,默认是采用 bridge 模式网络如图所示。如果使用 host 模式,则不隔离直接使用宿主机网络。overlay 网络则是更加高级的模式,可以实现跨主机的容器通信。
USER Namespace
user namespace 用于隔离用户和组信息,在不同的 namespace 中用户可以有相同的 UID 和 GID,它们之间互相不影响。父子 namespace 之间可以进行用户映射,如父 namespace(宿主机)的普通用户映射到子 namespace(容器)的 root 用户,以减少子 namespace 的 root 用户操作父 namespace 的风险。user namespace 功能虽然在很早就出现了,但是直到 Linux kernel 3.8 之后这个功能才趋于完善。
创建新的 user namespace 之后第一步就是设置好 user 和 group 的映射关系。这个映射通过设置 /proc/PID/uid_map(gid_map) 实现,格式如下,ID-inside-ns 是容器内的 uid/gid,而 ID-outside-ns 则是容器外映射的真实 uid/gid。比如 0 1000 1 表示将真实的 uid=1000 映射为容器内的 uid=0,length 为映射的范围。
ID-inside-ns ID-outside-ns length
不是所有的进程都能随便修改映射文件的,必须同时具备如下条件:
-
修改映射文件的进程必须有 PID 进程所在 user namespace 的 CAP_SETUID/CAP_SETGID 权限。
-
修改映射文件的进程必须是跟 PID 在同一个 user namespace 或者 PID 的父 namespace。
-
映射文件 uid_map 和 gid_map 只能写入一次,再次写入会报错。
Docker1.10 之后的版本可以通过在 docker daemon 启动时加上 --userns-remap=[USERNAME] 来实现 USER Namespace 的隔离。我们指定了 username=test 启动 dockerd,查看 subuid 文件可以发现 test 映射的 uid 范围是 165536 到 165536+65536= 231072,而且在 docker 目录下面对应 test 有一个独立的目录 165536.165536 存在。
root@host:/home/vagrant# cat /etc/subuid
vagrant:100000:65536
test:165536:65536
root@host:/home/vagrant# ls /var/lib/docker/165536.165536/
builder/ containerd/ containers/ image/ network/ ...
运行 docker images -a 等命令可以发现在启用 user namespace 之前的镜像都看不到了。此时只能看到在新的 user namespace 里面创建的 docker 镜像和容器。而此时我们创建一个测试容器,可以在容器外看到容器进程的 uid_map 已经设置为 ssj,这样容器中的 root 用户映射到宿主机就是 test 这个用户了,此时如果要删除我们挂载的/bin 目录中的文件,会提示没有权限,增强了安全性。
### dockerd 启动时加了 --userns-remap=test
root@host:/home/vagrant# docker run -it -v /bin:/host/bin --name demo alpine /bin/ash
/ # rm /host/bin/which
rm: remove '/host/bin/which'? y
rm: can't remove '/host/bin/which': Permission denied
### 宿主机查看容器进程uid_map文件
root@host:/home/vagrant# CPID=`ps -ef|grep '\/bin\/ash'|awk '{printf $2}'`
root@host:/home/vagrant# cat /proc/$CPID/uid_map
0 165536 65536
其他 Namespace
UTS namespace 用于隔离主机名等。可以看到在新的 uts namespace 修改主机名并不影响原 namespace 的主机名。
root@host:/home/vagrant# unshare --uts --fork bash
root@host:/home/vagrant# hostname
host
root@host:/home/vagrant# hostname modified
root@host:/home/vagrant# hostname
modified
root@host:/home/vagrant# exit
root@host:/home/vagrant# hostname
host
IPC Namespace 用于隔离 IPC 消息队列等。可以看到,新老 ipc namespace 的消息队列互不影响。
root@host:/home/vagrant# ipcmk -Q
Message queue id: 0
root@host:/home/vagrant# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x26c3371c 0 root 644 0 0
root@host:/home/vagrant# unshare --ipc --fork bash
root@host:/home/vagrant# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
CGROUP Namespace 是 Linux4.6 以后才支持的新 namespace。容器技术使用 namespace 和 cgroup 实现环境隔离和资源限制,但是对于 cgroup 本身并没有隔离。没有 cgroup namespace 前,容器中一旦挂载 cgroup 文件系统,便可以修改整全局的 cgroup 配置。有了 cgroup namespace 后,每个 namespace 中的进程都有自己的 cgroup 文件系统视图,增强了安全性,同时也让容器迁移更加方便。