
依赖管理结构
依赖管理结构
npm/yarn 的依赖管理结构
主要分为两个部分, 首先,执行 npm/yarn install 之后,包如何到达项目 node_modules 当中。其次,node_modules 内部如何管理依赖。执行命令后,首先会构建依赖树,然后针对每个节点下的包,会经历下面四个步骤:
-
- 将依赖包的版本区间解析为某个具体的版本号
-
- 下载对应版本依赖的 tar 包到本地离线镜像
-
- 将依赖从离线镜像解压到本地缓存
-
- 将依赖从缓存拷贝到当前目录的 node_modules 目录
然后,对应的包就会到达项目的 node_modules 当中。那么,这些依赖在 node_modules 内部是什么样的目录结构呢,换句话说,项目的依赖树是什么样的呢?在 npm1、npm2 中呈现出的是嵌套结构,比如下面这样:
node_modules
└─ foo
├─ index.js
├─ package.json
└─ node_modules
└─ bar
├─ index.js
└─ package.json
如果 bar 当中又有依赖,那么又会继续嵌套下去。试想一下这样的设计存在什么问题:
- 依赖层级太深,会导致文件路径过长的问题,尤其在 window 系统下。
- 大量重复的包被安装,文件体积超级大。比如跟 foo 同级目录下有一个 baz,两者都依赖于同一个版本的 lodash,那么 lodash 分别在两者的 node_modules 中被安装,也就是重复安装。
- 模块实例不能共享。比如 React 有一些内部变量,在两个不同包引入的 React 不是同一个模块实例,因此无法共享内部变量,导致一些不可预知的 bug。
接着,从 npm3 开始,包括 yarn,都着手来通过扁平化依赖的方式来解决这个问题。相比之前的嵌套结构,现在的目录结构类似下面这样:
node_modules
├─ foo
| ├─ index.js
| └─ package.json
└─ bar
├─ index.js
└─ package.json
所有的依赖都被拍平到 node_modules 目录下,不再有很深层次的嵌套关系。这样在安装新的包时,根据 node require 机制,会不停往上级的 node_modules 当中去找,如果找到相同版本的包就不会重新安装,解决了大量包重复安装的问题,而且依赖层级也不会太深。之前的问题是解决了,但仔细想想这种扁平化的处理方式,它真的就是无懈可击吗?并不是。它照样存在诸多问题,梳理一下:
- 依赖结构的不确定性。
- 扁平化算法本身的复杂性很高,耗时较长。
- 项目中仍然可以非法访问没有声明过依赖的包
后面两个都好理解,那第一点中的不确定性是什么意思?这里来详细解释一下。假如现在项目依赖两个包 foo 和 bar,这两个包的依赖又是这样的:
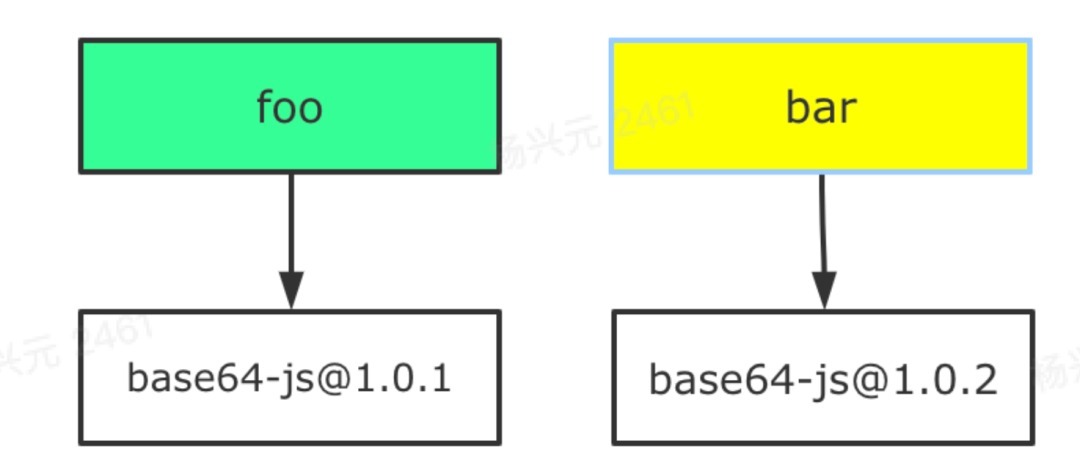
那么 npm/yarn install 的时候,通过扁平化处理之后,可能是以下任一方式:
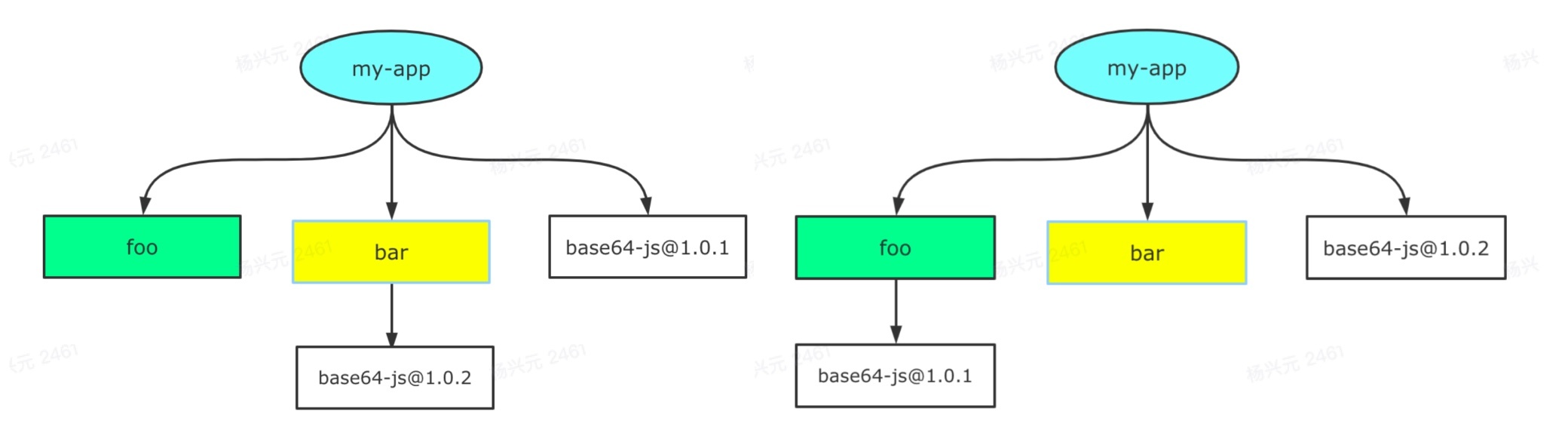
取决于 foo 和 bar 在 package.json 中的位置,如果 foo 声明在前面,那么就是前面的结构,否则是后面的结构。这就是为什么会产生依赖结构的不确定问题,也是 lock 文件诞生的原因,无论是 package-lock.json(npm 5.x 才出现)还是 yarn.lock,都是为了保证 install 之后都产生确定的 node_modules 结构。
尽管如此,npm/yarn 本身还是存在扁平化算法复杂和 package 非法访问的问题,影响性能和安全。
pnpm 依赖管理
pnpm 的作者 Zoltan Kochan 发现 yarn 并没有打算去解决上述的这些问题,于是另起炉灶,写了全新的包管理器,开创了一套新的依赖管理机制,现在就让我们去一探究竟。
▾ node_modules
▾ .pnpm
▸ accepts@1.3.7
▸ array-flatten@1.1.1
...
▾ express@4.17.1
▾ node_modules
▸ accepts -> ../accepts@1.3.7/node_modules/accepts
▸ array-flatten -> ../array-flatten@1.1.1/node_modules/array-flatten
...
▾ express
▸ lib
History.md
index.js
LICENSE
package.json
Readme.md
将包本身和依赖放在同一个 node_module 下面,与原生 Node 完全兼容,又能将 package 与相关的依赖很好地组织到一起,设计十分精妙。现在我们回过头来看,根目录下的 node_modules 下面不再是眼花缭乱的依赖,而是跟 package.json 声明的依赖基本保持一致。即使 pnpm 内部会有一些包会设置依赖提升,会被提升到根目录 node_modules 当中,但整体上,根目录的 node_modules 比以前还是清晰和规范了许多。
pnpm 这种依赖管理的方式也很巧妙地规避了非法访问依赖的问题,也就是只要一个包未在 package.json 中声明依赖,那么在项目中是无法访问的。但在 npm/yarn 当中是做不到的,那你可能会问了,如果 A 依赖 B, B 依赖 C,那么 A 就算没有声明 C 的依赖,由于有依赖提升的存在,C 被装到了 A 的 node_modules 里面,那我在 A 里面用 C,跑起来没有问题呀,我上线了之后,也能正常运行啊。不是挺安全的吗?
- 第一,你要知道 B 的版本是可能随时变化的,假如之前依赖的是C@1.0.1,现在发了新版,新版本的 B 依赖 C@2.0.1,那么在项目 A 当中 npm/yarn install 之后,装上的是 2.0.1 版本的 C,而 A 当中用的还是 C 当中旧版的 API,可能就直接报错了。
- 第二,如果 B 更新之后,可能不需要 C 了,那么安装依赖的时候,C 都不会装到 node_modules 里面,A 当中引用 C 的代码直接报错。
还有一种情况,在 monorepo 项目中,如果 A 依赖 X,B 依赖 X,还有一个 C,它不依赖 X,但它代码里面用到了 X。由于依赖提升的存在,npm/yarn 会把 X 放到根目录的 node_modules 中,这样 C 在本地是能够跑起来的,因为根据 node 的包加载机制,它能够加载到 monorepo 项目根目录下的 node_modules 中的 X。但试想一下,一旦 C 单独发包出去,用户单独安装 C,那么就找不到 X 了,执行到引用 X 的代码时就直接报错了。