
03.日志与持久化
日志与持久化
数据库中带有持久化的写操作分为如下几个步骤:
1.客户端发送写操作命令和数据;(数据在客户端内存)2.服务端通过网络收到客户端发来的写操作和数据;(数据在服务端内存)3.服务端修改内存中的数据,同时调用系统函数 write 进行操作,将数据往磁盘中写;(数据在服务端的系统内存缓冲区)4.操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)5.磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)
众所周知,访问磁盘中的数据往往速度较慢,换言之,内存中数据的访问速度还是远快于 SSD 中的数据访问速度。基于这个考量,基本上所有数据库引擎都尽可能地避免访问磁盘数据。并且无论数据库表还是数据库索引都被划分为了固定大小的数据页(譬如 8KB,或 16KB)。当我们需要读取表或者索引中的数据时,关系型数据库会将磁盘中的数据页映射入存储缓冲区。当我们需要修改数据时,关系型数据库首先会修改内存页中的数据,然后利用 fsync 这样的同步工具将改变同步回磁盘中。
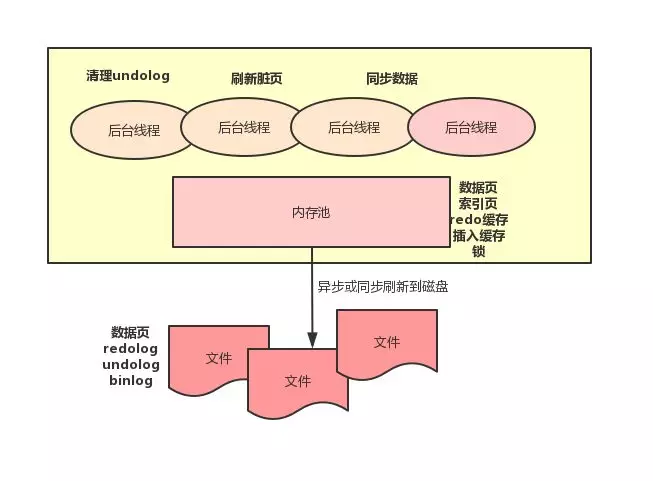
日志管理器(Log Manager)
数据库事务由具体的 DBMS 系统来保障操作的原子性,同一个事务当中,如果有某个操作执行失败,则事务当中的所有操作都需要进行回滚,回到事务执行前的状态。导致事务失败的原因有很多,可能是因为修改不符合表的约束规则,也有可能是网络异常,甚至是存储介质故障等,而一旦事务失败,则需要对所有已作出的修改操作进行还原,使数据库的状态恢复到事务执行前的状态,以保障数据的一致性,使修改操作要么全部成功、要么全部失败,避免存在中间状态。
为了实现数据库状态的恢复,DBMS 系统通常需要维护事务日志以追踪事务中所有影响数据库数据的操作,以便执行失败时进行事务的回滚。以 MySQL 的 innodb 存储引擎为例,innodb 存储引擎通过预写事务日志的方式,来保障事务的原子性、一致性以及持久性。它包含 redo 日志和 undo 日志,redo 日志在系统需要的时候,对事务操作进行重做,如当系统宕机重启后,能够对内存中还没有持久化到磁盘的数据进行恢复,而 undo 日志,则能够在事务执行失败的时候,利用这些 undo 信息,将数据还原到事务执行前的状态。
事务日志可以提高事务执行的效率,存储引擎只需要将修改行为持久到事务日志当中,便可以只对该数据在内存中的拷贝进行修改,而不需要每次修改都将数据回写到磁盘。这样做的好处是,日志写入是一小块区域的顺序 IO,而数据库数据的磁盘回写则是随机 IO,磁头需要不停地移动来寻找需要更新数据的位置,无疑效率更低,通过事务日志的持久化,既保障了数据存储的可靠性,又提高了数据写入的效率。
Undo Log
由于同时可能由多个事务并发地对内存中的数据进行修改,因此关系型数据库往往需要依赖于某个并发控制机制 2PL 或者 MVCC 来保证数据一致性。因此,当某个事务需要去更改数据表中某一行时,未提交的改变会被写入到内存数据中,而之前的数据会被追加写入到 Undo Log 文件中。
Oracle 或者 MySQL 中使用了所谓 undo log 数据结构,而 SQL Server 中则是使用 transaction log 完成此项工作。PostgreSQL 并没有 undo log,不过其内建支持所谓多版本的表数据,即同一行的数据可能同时存在多个版本。总而言之,任何关系型数据库都采用的类似的数据结构都是为了允许回滚以及数据的原子性。
如果当前运行的事务发生了回滚,undo log 会被用于重建事务起始阶段时候的内存页。
Redo Log
某个事务提交之后,内存中的改变就需要同步到磁盘中。不过并不是所有的事务提交都会立刻触发同步,过高频次的同步反而会对应用性能造成损伤。不过根据 ACID 原则,提交之后的事务必须要保证持久性,也就是即使此时数据库引擎宕机了,提交之后的更改也应该被持久化存储下来。这里关系型数据库就是依靠 Redo Log 来达成这一点。
它是一个仅允许追加写入的基于磁盘的数据结构,它会记录所有尚未执行同步的事务操作。相较于一次性写入固定数目的数据页到磁盘中,顺序地写入到 Redo Log 会比随机访问快上很多。因此,关于事务的 ACID 特性的保证与应用性能之间也就达成了较好的平衡。该数据结构在 Oracle 与 MySQL 中就是叫 Redo Log,而 SQL Server 中则是由 transaction log 执行,在 PostgreSQL 中则是使用 Write-Ahead Log( WAL )。下面我们继续回到上面的那个问题,应该在何时将内存中的数据写入到磁盘中。关系型数据库系统往往使用检查点来同步内存的脏数据页与磁盘中的对应部分。为了避免 IO 阻塞,同步过程往往需要等待较长的时间才能完成。因此,关系型数据库需要保证即使在所有内存脏页同步到磁盘之前引擎就崩溃的时候不会发生数据丢失。同样地,在每次数据库重启的时候,数据库引擎会基于 Redo Log 重构那些最后一次成功的检查点以来所有的内存数据页。
WAL
InnoDB 在更新数据的时候会采用 WAL 技术,也就是 Write Ahead Logging,这个日志就是 Redo Log 用来保证数据库宕机后可以通过该文件进行恢复。这个文件一般只会顺序写,只有在数据库启动的时候才会读取 Redo Log 文件看是否需要进行恢复。该文件记录了对某个数据页的物理操作,例如某个 sql 把某一行的某个列的值改为 10,对应的 Redo Log 文件格式可能为:把第 5 个数据页中偏移量为 99 的位置写入一个值 10。redolog 不是无限大的,他的大小是可以配置的,并且是循环使用的,例如配置大小为 4G,一共 4 个文件,每个文件 1G。首先从第一个文件开始顺序写,写到第四个文件后在从第一个文件开始写,类似一个环,用一个后台线程把 Redo Log 里的数据同步到聚簇索引上的数据页上。写入 Redo Log 的时候不能将没有同步到数据页上的记录覆盖,如果碰到这种情况会停下来先进行数据页同步然后在继续写入 Redo Log。另外执行更新操作的时候,会先更新缓冲池里的数据页,然后写入 Redo Log,这个时候真正存储数据的地方还没有更新,也就是说这时候缓冲池中的数据页和磁盘不一致,这种数据页称为脏页,当脏页由于内存不足或者其他原因需要丢弃的时候,一定要先将该脏页对应的 Redo Log 刷新到磁盘里的真实数据页,不然下次查询的时候由于 Redo Log 没有同步到磁盘,而查询直接通过索引定位到数据页就会查询出脏数据。
更新的时候先从磁盘或者缓冲池中读取对应的数据页,然后对数据页里的数据进行更改并生成 Redo Log 到对应的缓冲池(redolog buffer)进行缓存,当事务提交的时候将缓存写入到 Redo Log 的物理磁盘文件上。这里由于操作系统的文件写入 InnoDB 并没有使用 O_DIRECT 直接写入到文件,为了保证性能而是先写入操作系统的缓存,之后在进行 flush,所以事务提交的时候 InnoDB 需要在调用一次 fsync 的系统调用来确保数据落盘。