
事务日志
事务日志
当提交一个事务时,InnoDB 首先会把事务写入日志缓冲(Log buffer),日志缓冲把事务刷新到事务日志;然后存储引擎再把事务写入缓冲池(Buffer Pool)。由此可见,InnoDB 通过事务日志把随机 IO 变成顺序 IO,这大大的提高了 InnoDB 写入时的性能。因为把缓冲池的脏页数据刷新到磁盘可能会涉及大量随机 IO,这些随机 IO 会非常慢,通过事务日志,避开随机 IO,用顺序 IO 替代它。
Innodb 日志是环行方式写的:当写到日志的尾部,会重新跳转到开头继续写,但不会覆盖还没应用到数据文件的日志记录,因为这样会清理掉已提交事务的唯一持久化记录。日志文件太小,InnoDB 将必须做更多的检查点,导致更多的日志写,在日志没有空间继续写入前,必须等待变更被应用到数据文件,写语句可能会被拖累。但日志文件太大,在崩溃恢复时 InnoDB 可能不得不做大量的工作,增加恢复时间。应该在这之间找到平衡,设置合适的日志大小。
Redo Log
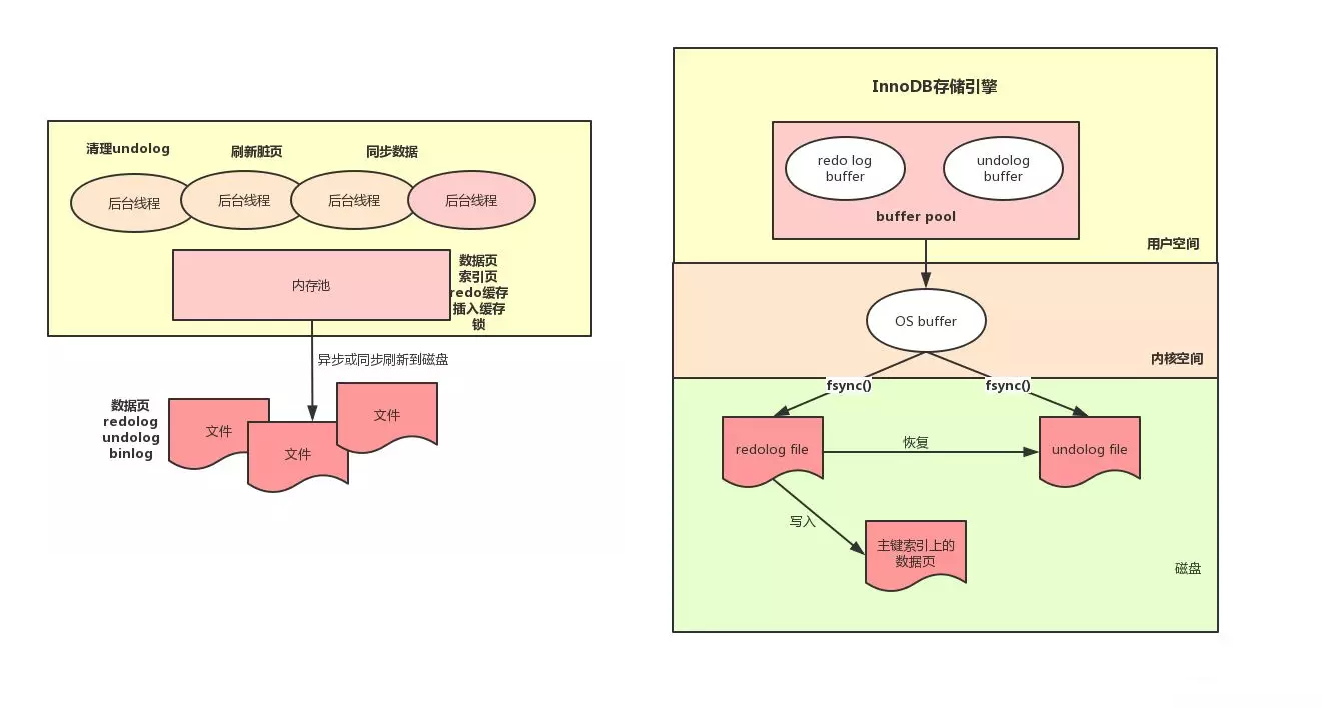
InnoDB 在更新数据的时候会采用 WAL 技术,也就是 Write Ahead Logging,这个日志就是 Redo Log 用来保证数据库宕机后可以通过该文件进行恢复。这个文件一般只会顺序写,只有在数据库启动的时候才会读取 Redo Log 文件看是否需要进行恢复。该文件记录了对某个数据页的物理操作,例如某个 SQL 把某一行的某个列的值改为 10,对应的 Redo Log 文件格式可能为:把第 5 个数据页中偏移量为 99 的位置写入一个值 10。Redo Log 不是无限大的,他的大小是可以配置的,并且是循环使用的,例如配置大小为 4G,一共 4 个文件,每个文件 1G。
Redo Log 中,存储引擎首先会从第一个文件开始顺序写,写到第四个文件后在从第一个文件开始写,类似一个环,用一个后台线程把 Redo Log 里的数据同步到聚簇索引上的数据页上。首先写入 Redo Log 的时候不能将没有同步到数据页上的记录覆盖,如果碰到这种情况会停下来先进行数据页同步然后在继续写入 Redo Log。另外执行更新操作的时候,会先更新缓冲池里的数据页,然后写入 Redo Log,这个时候真正存储数据的地方还没有更新,也就是说这时候缓冲池中的数据页和磁盘不一致,这种数据页称为脏页,当脏页由于内存不足或者其他原因需要丢弃的时候,一定要先将该脏页对应的 Redo Log 刷新到磁盘里的真实数据页,不然下次查询的时候由于 Redo Log 没有同步到磁盘,而查询直接通过索引定位到数据页就会查询出脏数据。
更新的时候先从磁盘或者缓冲池中读取对应的数据页,然后对数据页里的数据进行更改并生成 Redo Log 到对应的缓冲池(redolog buffer)进行缓存,当事务提交的时候将缓存写入到 Redo Log 的物理磁盘文件上。这里由于操作系统的文件写入 InnoDB 并没有使用 O_DIRECT 直接写入到文件,为了保证性能而是先写入操作系统的缓存,之后在进行 flush,所以事务提交的时候 InnoDB 需要在调用一次 fsync 的系统调用来确保数据落盘。
为了提高性能 InnoDB 可以通过参数 innodb_flush_log_at_trx_commit 来控制事务提交时是否强制刷盘。默认为 1,事务每次提交都需要调用 fsync 进行刷盘,0 表示事务提交的时候不会调用 Redo Log 的文件写入,通过后台线程每秒同步一次;2 表示事务提交的时候会写入文件但是只保证写入操作系统缓存,不进行 fsync 操作。Redo Log 文件只会顺序写,所以磁盘操作性能不会太慢,所以建议生产环境都设置为 1,以防止数据库宕机导致数据丢失。
Undo Log
Undo Log 存放在共享表空间中,也就是即使打开了 innodb_file_per_table 参数,所有的表的 Undo Log 都存储在同一个文件里。Undo Log 是逻辑日志,主要用于进行事务回滚与 MVCC 操作;譬如执行相反的操作回滚到之前的状态,譬如记录的和原 sql 相反的 sql,例如 insert 对应 delete,delete 对应 insert,update 对应另外一个 update。而 MVCC 是指可重复读,当一个事务需要查询某条记录,而该记录已经被其他事务修改,但该事务还没提交,而当前事务可以通过 Undo Log 计算到之前的值。
Undo Log 也是需要在执行 update 语句的时候在事务提交前需要写入到文件的。另外 Undo Log 的写入也会有对应的 Redo Log,因为 Undo Log 也需要持久化,通过 WAL 可以提高效率。这里可以总结下,在事务提交的时候要保证 Redo Log 写入到文件里,而这个 Redo Log 包含 主键索引上的数据页的修改,以及共享表空间的回滚段中 Undo Log 的插入。另外 Undo Log 的清理通过一个后台线程定时处理,清理的时候需要判断该 Undo Log 是否所有的事务都不会用到。