
距离与相似性
数值点距离:numeric data points Numeric Data Points
闵可夫斯基距离
闵可夫斯基距离(Minkowski distance)是衡量数值点之间距离的一种非常常见的方法,假设数值点 P 和 Q 坐标如下:

那么,闵可夫斯基距离定义为:

该距离最常用的 p 是 2 和 1, 前者是欧几里得距离(Euclidean distance),后者是曼哈顿距离(Manhattan distance)。假设在曼哈顿街区乘坐出租车从 P 点到 Q 点,白色表示高楼大厦,灰色表示街道:

绿色的斜线表示欧几里得距离,在现实中是不可能的。其他三条折线表示了曼哈顿距离,这三条折线的长度是相等的。
当 p 趋近于无穷大时,闵可夫斯基距离转化成切比雪夫距离(Chebyshev distance):

我们知道平面上到原点欧几里得距离(p = 2)为 1 的点所组成的形状是一个圆,当 p 取其他数值的时候呢?

注意,当 p < 1 时,闵可夫斯基距离不再符合三角形法则,举个例子:当 p < 1, (0,0) 到 (1,1) 的距离等于(1+1)^{1/p} > 2, 而 (0,1) 到这两个点的距离都是 1。
闵可夫斯基距离比较直观,但是它与数据的分布无关,具有一定的局限性,如果 x 方向的幅值远远大于 y 方向的值,这个距离公式就会过度放大 x 维度的作用。所以,在计算距离之前,我们可能还需要对数据进行 z-transform 处理,即减去均值,除以标准差:
: 该维度上的均值
: 该维度上的标准差
可以看到,上述处理开始体现数据的统计特性了。这种方法在假设数据各个维度不相关的情况下利用数据分布的特性计算出不同的距离。如果维度相互之间数据相关(例如:身高较高的信息很有可能会带来体重较重的信息,因为两者是有关联的),这时候就要用到马氏距离(Mahalanobis distance)了。
马氏距离
考虑下面这张图,椭圆表示等高线,从欧几里得的距离来算,绿黑距离大于红黑距离,但是从马氏距离,结果恰好相反:

马氏距离实际上是利用 Cholesky transformation 来消除不同维度之间的相关性和尺度不同的性质。假设样本点(列向量)之间的协方差对称矩阵是

下图蓝色表示原样本点的分布,两颗红星坐标分别是(3, 3),(2, -2):

由于 x,y 方向的尺度不同,不能单纯用欧几里得的方法测量它们到原点的距离。并且,由于 x 和 y 是相关的(大致可以看出斜向右上),也不能简单地在 x 和 y 方向上分别减去均值,除以标准差。最恰当的方法是对原始数据进行 Cholesky 变换,即求马氏距离(可以看到,右边的红星离原点较近):

将上面两个图的绘制代码和求马氏距离的代码贴在这里,以备以后查阅:
# -*- coding=utf-8 -*-
# code related at: http://www.cnblogs.com/daniel-D/
import numpy as np
import pylab as pl
import scipy.spatial.distance as dist
def plotSamples(x, y, z=None):
stars = np.matrix([[3., -2., 0.], [3., 2., 0.]])
if z is not None:
x, y = z * np.matrix([x, y])
stars = z * stars
pl.scatter(x, y, s=10) # 画 gaussian 随机点
pl.scatter(np.array(stars[0]), np.array(stars[1]), s=200, marker='*', color='r') # 画三个指定点
pl.axhline(linewidth=2, color='g') # 画 x 轴
pl.axvline(linewidth=2, color='g') # 画 y 轴
pl.axis('equal')
pl.axis([-5, 5, -5, 5])
pl.show()
# 产生高斯分布的随机点
mean = [0, 0] # 平均值
cov = [[2, 1], [1, 2]] # 协方差
x, y = np.random.multivariate_normal(mean, cov, 1000).T
plotSamples(x, y)
covMat = np.matrix(np.cov(x, y)) # 求 x 与 y 的协方差矩阵
Z = np.linalg.cholesky(covMat).I # 仿射矩阵
plotSamples(x, y, Z)
# 求马氏距离
print '\n到原点的马氏距离分别是:'
print dist.mahalanobis([0,0], [3,3], covMat.I), dist.mahalanobis([0,0], [-2,2], covMat.I)
# 求变换后的欧几里得距离
dots = (Z * np.matrix([[3, -2, 0], [3, 2, 0]])).T
print '\n变换后到原点的欧几里得距离分别是:'
print dist.minkowski([0, 0], np.array(dots[0]), 2), dist.minkowski([0, 0], np.array(dots[1]), 2)
马氏距离的变换和 PCA 分解的白化处理颇有异曲同工之妙,不同之处在于:就二维来看,PCA 是将数据主成分旋转到 x 轴(正交矩阵的酉变换),再在尺度上缩放(对角矩阵),实现尺度相同。而马氏距离的 L 逆矩阵是一个下三角,先在 x 和 y 方向进行缩放,再在 y 方向进行错切(想象矩形变平行四边形),总体来说是一个没有旋转的仿射变换。
类别点距离(categorical data points)
$distance_{final} = α.distance_{numeric} + (1- α).distance_{categorical}$
汉明距离
汉明距离(Hamming distance)是指,两个等长字符串 s1 与 s2 之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。举个维基百科上的例子:

还可以用简单的匹配系数来表示两点之间的相似度——匹配字符数/总字符数。在一些情况下,某些特定的值相等并不能代表什么。举个例子,用 1 表示用户看过该电影,用 0 表示用户没有看过,那么用户看电影的的信息就可用 0,1 表示成一个序列。考虑到电影基数非常庞大,用户看过的电影只占其中非常小的一部分,如果两个用户都没有看过某一部电影(两个都是 0),并不能说明两者相似。反而言之,如果两个用户都看过某一部电影(序列中都是 1),则说明用户有很大的相似度。在这个例子中,序列中等于 1 所占的权重应该远远大于 0 的权重,这就引出下面要说的杰卡德相似系数(Jaccard similarity)。
Jacard 相似度
Jacard 相似性直观的概念来自,两个集合有多相似,显然,Jacard 最好是应用在离散的变量几何上。先看公式:
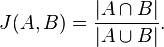
分子是集合交集,分母是集合并集,画个图,马上就明白咋回事了。
和 Jacard index 相似的一个公式是 Dice‘ coefficient, 它也很直观,

向量内积
向量内积是线性代数里最为常见的计算,实际上它还是一种有效并且直观的相似性测量手段。向量内积的定义如下:
直观的解释是:如果 x 高的地方 y 也比较高,x 低的地方 y 也比较低,那么整体的内积是偏大的,也就是说 x 和 y 是相似的。举个例子,在一段长的序列信号 A 中寻找哪一段与短序列信号 a 最匹配,只需要将 a 从 A 信号开头逐个向后平移,每次平移做一次内积,内积最大的相似度最大。信号处理中 DFT 和 DCT 也是基于这种内积运算计算出不同频域内的信号组分(DFT 和 DCT 是正交标准基,也可以看做投影)。向量和信号都是离散值,如果是连续的函数值,比如求区间[-1, 1] 两个函数之间的相似度,同样也可以得到(系数)组分,这种方法可以应用于多项式逼近连续函数,也可以用到连续函数逼近离散样本点(最小二乘问题,OLS coefficients)中,扯得有点远了- -!。
余弦相似度
向量内积的结果是没有界限的,一种解决办法是除以长度之后再求内积,这就是应用十分广泛的余弦相似度(Cosine similarity):
余弦相似度与向量的幅值无关,只与向量的方向相关,在文档相似度(TF-IDF)和图片相似性(histogram)计算上都有它的身影。
皮尔逊相关系数(Pearson Correlation Coefficient)
需要注意一点的是,余弦相似度受到向量的平移影响,上式如果将 x 平移到 x+1, 余弦值就会改变。怎样才能实现平移不变性?这就是下面要说的皮尔逊相关系数(Pearson correlation),有时候也直接叫相关系数。皮尔逊相关系数是一种度量两个变量间相关程度的方法。它是一个介于 1 和 -1 之间的值,其中,1 表示变量完全正相关,0 表示无关,-1 表示完全负相关。
=
$\frac{\sum x_iy_i-\frac{\sum x_i\sum y_i}{n}}{\sqrt{\sum x_i^2-\frac{(\sum x_i)^2}{n}}\sqrt{\sum y_i^2-\frac{(\sum y_i)^2}{n}}}$
在推荐系统中,我们常用皮尔逊相关系数来衡量两个用户兴趣的相似度,它是判断两组数据与某一直线拟合程度的一种度量。它在用户对物品的评分数据差别大时(如有些用户评分普遍较高,有些用户评分普遍偏低)时的效果更好。也即它修正了“夸大分值”的情况,如果某个用户总是倾向于给出比另一个人更高的分值,而两者的分值之差又始终保持一致,则两者间依然可能存在很好地相关性。

在统计学中,皮尔逊积矩相关系数(Pearson product-moment correlation coefficient)用于度量两个变量 X 和 Y 之间的相关(线性相关),其值介于-1 与 1 之间。系数的值为 1 意味着X 和 Y可以很好的由直线方程来描述,所有的数据点都很好的落在一条 直线上,且 Y 随着 X 的增加而增加。系数的值为?1 意味着所有的数据点都落在直线上,且 Y 随着 X 的增加而减少。系数的值为 0 意味着两个变量之间没有线性关系。当两个变量独立时,相关系数为 0.但反之并不成立。这是因为相关系数仅仅反映了两个变量之间是否线性相关。比如说,X是区间[-1,1]上的一个均匀分布的随机变量。Y = X2. 那么Y是完全由X确定。因此Y 和X是不独立的。但是相关系数为 0。或者说他们是不相关的。当Y 和X服从联合正态分布时,其相互独立和不相关是等价的。当且仅当 X**i and Y**i 均落在他们各自的均值的同一侧,则(X**i ? X)(Y**i ? Y) 的值为正。也就是说,如果X**i 和 Y**i 同时趋向于大于, 或同时趋向于小于他们各自的均值,则相关系数为正。如果 X**i 和 Y**i 趋向于落在他们均值的相反一侧,则相关系数为负。
皮尔逊相关系数具有平移不变性和尺度不变性,计算出了两个向量(维度)的相关性。不过,一般我们在谈论相关系数的时候,将 x 与 y 对应位置的两个数值看作一个样本点,皮尔逊系数用来表示这些样本点分布的相关性。

由于皮尔逊系数具有的良好性质,在各个领域都应用广泛,例如,在推荐系统根据为某一用户查找喜好相似的用户,进而提供推荐,优点是可以不受每个用户评分标准不同和观看影片数量不一样的影响。
例如,假设五个国家的国民生产总值分别是 1、2、3、5、8(单位 10 亿美元),又假设这五个国家的贫困比例分别是 11%、12%、13%、15%、18%。
创建 2 个向量.(R 语言)
x<-c(1,2,3,5,8)
y<-c(0.11,0.12,0.13,0.15,0.18)
按照维基的例子,应计算出相关系数为 1 出来.我们看看如何一步一步计算出来的.
x 的平均数是:3.8
y 的平均数是 0.138
所以,
sum((x-mean(x))*(y-mean(y)))=0.308
用大白话来写就是:
(1-3.8)*(0.11-0.138)=0.0784
(2-3.8)*(0.12-0.138)=0.0324
(3-3.8)*(0.13-0.138)=0.0064
(5-3.8)*(0.15-0.138)=0.0144
(8-3.8)*(0.18-0.138)=0.1764
0.0784+0.0324+0.0064+0.0144+0.1764=0.308
同理, 分号下面的,分别是:
sum((x-mean(x))^2)=30.8
sum((y-mean(y))^2)= 0.00308
用大白话来写,分别是:
(1-3.8)^2=7.84 #平方
(2-3.8)^2=3.24 #平方
(3-3.8)^2=0.64 #平方
(5-3.8)^2=1.44 #平方
(8-3.8)^2=17.64 #平方
7.84+3.24+0.64+1.44+17.64=30.8
同理,求得:
sum((y-mean(y))^2)= 0.00308
然后再开平方根,分别是:
30.8^0.5=5.549775
0.00308^0.5=0.05549775
用分子除以分母,就计算出最终结果:
0.308/(5.549775*0.05549775)=1
#皮尔逊相关度
def sim_pearson(prefs,p1,p2):
si={}
for item in prefs[p1]:
if item in prefs[p2]: si[item]=1
if len(si)==0: return 0
n=len(si)
#计算开始
sum1=sum([prefs[p1][it] for it in si])
sum2=sum([prefs[p2][it] for it in si])
sum1Sq=sum([pow(prefs[p1][it],2) for it in si])
sum2Sq=sum([pow(prefs[p2][it],2) for it in si])
pSum=sum([prefs[p1][it]*prefs[p2][it] for it in si])
num=pSum-(sum1*sum2/n)
den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
#计算结束
if den==0: return 0
r=num/den
return r
序列距离(String,TimeSeries)
DTW(Dynamic Time Warp)
汉明距离可以度量两个长度相同的字符串之间的相似度,如果要比较两个不同长度的字符串,不仅要进行替换,而且要进行插入与删除的运算,在这种场合下,通常使用更加复杂的编辑距离(Edit distance, Levenshtein distance)等算法。编辑距离是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。编辑距离求的是最少编辑次数,这是一个动态规划的问题,有兴趣的同学可以自己研究研究。
时间序列是序列之间距离的另外一个例子。DTW 距离(Dynamic Time Warp)是序列信号在时间或者速度上不匹配的时候一种衡量相似度的方法。神马意思?举个例子,两份原本一样声音样本 A、B 都说了“你好”,A 在时间上发生了扭曲,“你”这个音延长了几秒。最后 A:“你~~~~~~~好”,B:“你好”。DTW 正是这样一种可以用来匹配 A、B 之间的最短距离的算法。
DTW 距离在保持信号先后顺序的限制下对时间信号进行“膨胀”或者“收缩”,找到最优的匹配,与编辑距离相似,这其实也是一个动态规划的问题:

#!/usr/bin/python2
# -*- coding:UTF-8 -*-
# code related at: http://blog.mckelv.in/articles/1453.html
import sys
distance = lambda a,b : 0 if a==b else 1
def dtw(sa,sb):
'''
>>>dtw(u"干啦今今今今今天天气气气气气好好好好啊啊啊", u"今天天气好好啊")
2
'''
MAX_COST = 1<<32
#初始化一个len(sb) 行(i),len(sa)列(j)的二维矩阵
len_sa = len(sa)
len_sb = len(sb)
# BUG:这样是错误的(浅拷贝): dtw_array = [[MAX_COST]*len(sa)]*len(sb)
dtw_array = [[MAX_COST for i in range(len_sa)] for j in range(len_sb)]
dtw_array[0][0] = distance(sa[0],sb[0])
for i in xrange(0, len_sb):
for j in xrange(0, len_sa):
if i+j==0:
continue
nb = []
if i > 0: nb.append(dtw_array[i-1][j])
if j > 0: nb.append(dtw_array[i][j-1])
if i > 0 and j > 0: nb.append(dtw_array[i-1][j-1])
min_route = min(nb)
cost = distance(sa[j],sb[i])
dtw_array[i][j] = cost + min_route
return dtw_array[len_sb-1][len_sa-1]
def main(argv):
s1 = u'干啦今今今今今天天气气气气气好好好好啊啊啊'
s2 = u'今天天气好好啊'
d = dtw(s1, s2)
print d
return 0
if __name__ == '__main__':
sys.exit(main(sys.argv))
网络节点距离
分布距离
前面我们谈论的都是两个数值点之间的距离,实际上两个概率分布之间的距离是可以测量的。在统计学里面经常需要测量两组样本分布之间的距离,进而判断出它们是否出自同一个 population,常见的方法有卡方检验(Chi-Square)和 KL 散度( KL-Divergence),下面说一说 KL 散度吧。
先从信息熵说起,假设一篇文章的标题叫做“黑洞到底吃什么”,包含词语分别是 {黑洞, 到底, 吃什么}, 我们现在要根据一个词语推测这篇文章的类别。哪个词语给予我们的信息最多?很容易就知道是“黑洞”,因为“黑洞”这个词语在所有的文档中出现的概率太低啦,一旦出现,就表明这篇文章很可能是在讲科普知识。而其他两个词语“到底”和“吃什么”出现的概率很高,给予我们的信息反而越少。如何用一个函数 h(x) 表示词语给予的信息量呢?第一,肯定是与 p(x) 相关,并且是负相关。第二,假设 x 和 y 是独立的(黑洞和宇宙不相互独立,谈到黑洞必然会说宇宙),即 p(x,y) = p(x)p(y), 那么获得的信息也是叠加的,即 h(x, y) = h(x) + h(y)。满足这两个条件的函数肯定是负对数形式:
对假设一个发送者要将随机变量 X 产生的一长串随机值传送给接收者,接受者获得的平均信息量就是求它的数学期望:
这就是熵的概念。另外一个重要特点是,熵的大小与字符平均最短编码长度是一样的(shannon)。设有一个未知的分布 p(x), 而 q(x) 是我们所获得的一个对 p(x) 的近似,按照 q(x) 对该随机变量的各个值进行编码,平均长度比按照真实分布的 p(x) 进行编码要额外长一些,多出来的长度这就是 KL 散度(之所以不说距离,是因为不满足对称性和三角形法则),即:

KL 散度又叫相对熵(relative entropy)。了解机器学习的童鞋应该都知道,在 Softmax 回归(或者 Logistic 回归),最后的输出节点上的值表示这个样本分到该类的概率,这就是一个概率分布。对于一个带有标签的样本,我们期望的概率分布是:分到标签类的概率是 1,其他类概率是 0。但是理想很丰满,现实很骨感,我们不可能得到完美的概率输出,能做的就是尽量减小总样本的 KL 散度之和(目标函数)。这就是 Softmax 回归或者 Logistic 回归中 Cost function 的优化过程啦。(PS:因为概率和为 1,一般的 logistic 二分类的图只画了一个输出节点,隐藏了另外一个)