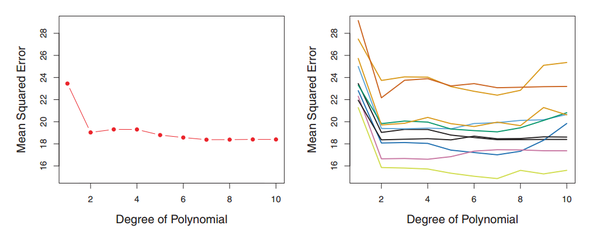
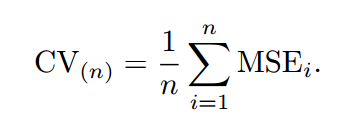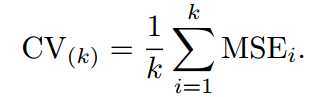右边是十种不同的训练集和测试集划分方法得到的 test MSE,可以看到,在不同的划分方法下,test MSE 的变动是很大的,而且对应的最优 degree 也不一样。所以如果我们的训练集和测试集的划分方法不够好,很有可能无法选择到最好的模型与参数。
LOOCV
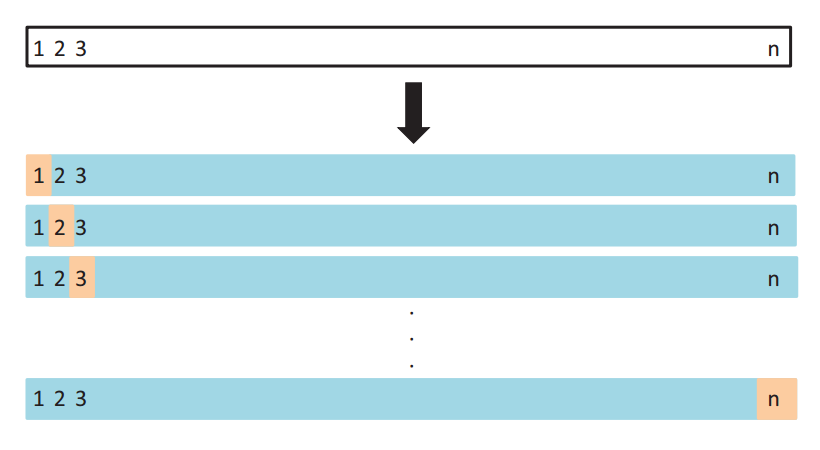
LOOCV(Leave-one-out cross-validation) 像 Test set approach 一样,LOOCV 方法也包含将数据集分为训练集和测试集这一步骤。但是不同的是,我们现在只用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复 N 次(N 为数据集的数据数量)。
如上图所示,假设我们现在有 n 个数据组成的数据集,那么 LOOCV 的方法就是每次取出一个数据作为测试集的唯一元素,而其他 n-1 个数据都作为训练集用于训练模型和调参。结果就是我们最终训练了 n 个模型,每次都能得到一个 MSE。而计算最终 test MSE 则就是将这 n 个 MSE 取平均。
比起 test set approach,LOOCV 有很多优点。首先它不受测试集合训练集划分方法的影响,因为每一个数据都单独的做过测试集。同时,其用了 n-1 个数据训练模型,也几乎用到了所有的数据,保证了模型的 bias 更小。不过 LOOCV 的缺点也很明显,那就是计算量过于大,是 test set approach 耗时的 n-1 倍。