
范式
范式与正则化
正则化是为了防止过拟合
交叉验证是为了选择 hyperparameter
Model Evaluation
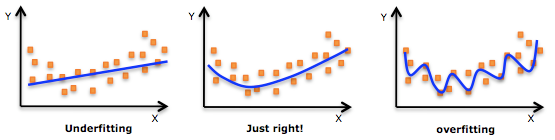
Overfitting
(1)对于机器来说,在使用学习算法学习数据的特征的时候,样本数据的特征可以分为局部特征和全局特征,全局特征就是任何你想学习的那个概念所对应的数据都具备的特征,而局部特征则是你用来训练机器的样本里头的数据专有的特征. (2)在学习算法的作用下,机器在学习过程中是无法区别局部特征和全局特征的,于是机器在完成学习后,除了学习到了数据的全局特征,也可能习得一部分局部特征,而习得的局部特征比重越多,那么新样本中不具有这些局部特征但具有所有全局特征的样本也越多,于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题. (3)所谓过拟合,就是指把学习进行的太彻底,把样本数据的所有特征几乎都习得了,于是机器学到了过多的局部特征,过多的由于噪声带来的假特征,造成模型的“泛化性”和识别正确率几乎达到谷点,于是你用你的机器识别新的样本的时候会发现就没几个是正确识别的. (4)解决过拟合的方法,其基本原理就是限制机器的学习,使机器学习特征时学得不那么彻底,因此这样就可以降低机器学到局部特征和错误特征的几率,使得识别正确率得到优化. (5)从上面的分析可以看出,要防止过拟合,训练数据的选取也是很关键的,良好的训练数据本身的局部特征应尽可能少,噪声也尽可能小.
(1)打个形象的比方,给一群天鹅让机器来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个“2”且略大于鸭子.这时候你的机器已经基本能区别天鹅和其他动物了。
(2)然后,很不巧你的天鹅全是白色的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅.
(3)好,来分析一下上面这个例子:(1)中的规律都是对的,所有的天鹅都有的特征,是全局特征;然而,(2)中的规律:天鹅的羽毛是白的.这实际上并不是所有天鹅都有的特征,只是局部样本的特征。机器在学习全局特征的同时,又学习了局部特征,这才导致了不能识别黑天鹅的情况.
Early stopping
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping 便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。 Early stopping 方法的具体做法是,在每一个 Epoch 结束时(一个 Epoch 集为对所有的训练数据的一轮遍历)计算 validation data 的 accuracy,当 accuracy 不再提高时,就停止训练。这种做法很符合直观感受,因为 accurary 都不再提高了,在继续训练也是无 益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为 validation accurary 不再提高了呢?并不是说 validation accuracy 一降下来便认为不再提高了,因为可能经过这个 Epoch 后,accuracy 降低了,但是随后的 Epoch 又让 accuracy 又上去 了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的 validation accuracy,当连续 10 次 Epoch(或者更多次)没达到最佳 accuracy 时,则可以认为 accuracy 不再提高了。此时便可以停止迭代了 (Early Stopping)。这种策略也称为“No-improvement-in-n”,n 即 Epoch 的次数,可以根据实际情况取,如 10、20、30……
数据集扩增
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进 行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模 拟地更准确。因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打 标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方 式与策略在已有的数据集上进行手脚,以得到更多的数据。 通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
Cross Validation:交叉验证
Norm:范式
- l0-norm-l1-norm-l2-norm-l-infinity-norm
- differences-between-the-l1-norm-and-the-l2-norm-least-absolute-deviations-and-least-squares
一般在机器学习的实践中,我们常用的范式就是 L1 范式
Types:范式类型
L0 Norm
L1 Norm
L2 Norm
L-Infinity Norm
Loss/Error Function:损失函数
L1 范式与 L2 范式常用的场景就是作为损失函数或者代价函数,而使用 L1 范式的损失函数一般称为 LAD(Least Absolute Deviations),即最小绝对值偏差或者 LAE(Least Absolute Errors),即最小绝对值错误。LAD 的目标即是使得目标值$Y_i$与测量值$f(x_i)$之间的绝对值差和最小。
$$ S = \sum_{i=1}^{n}|y_i - f(x_i)| $$
使用 L2 范式的损失函数一般又被称为 LSE(Least Squares Error),即最小平方误差:
$$ S = \sum^n_{i=1}(y_i - f(x_i))^2 $$
而 LAE 与 LSE 的区别可以总结为:
| L2 loss function | L1 loss function |
|---|---|
| Not very robust | Robust |
| Stable solution | Unstable solution |
| Always one solution | Possibly multiple solutions |
-
Solution uniqueness:是否唯一解

-
Robustness:鲁棒性,即异常值的影响能力 直观来说,因为 LSE 使用了 L2 范式,即将误差值平方求和,这就导致了模型会比 LAE 存在更大的误差,因此模型与 LAE 相比会更加地敏感于单个数据点。如果该数据点是个异常值,那么模型会为了更好地拟合这个异常值的情形而导致对于其他值的偏差增大。一般来说,正常的数据点造成的误差值都比较小,而异常数据点造成的误差值会比较大,在 LSE 中异常数据点对于拟合结果的影响会大于 LAE。
-
Stable:稳定性,即异常值发生变化时候的影响 在 LAD 中,如果某个数据点发生了一点水平位移,都可能导致最后的拟合线发生较大的变化。而 LSE 与之相比则有较大的稳定性,对于数据点任何较小地变化,拟合线也只会变化一点点,即拟合地参数可以看做关于数据的一个持续函数的值。
下图就是一个使用真实的数据与真实的拟合模型构造的结果图:

关于上图需要注意两点: (1)在同一张图中,计入异常点与不计入异常点相比,LAE 的两条拟合线差异较大,而 LSE 则差异较小。 (2)在将异常点从左到右进行移动地过程中,LAE 与 LSE 相比会发生更多的变化。