
03.网络
网络 IO
在虚拟存储一章中我们讨论了内核空间与用户空间的划分,即针对 32 位 Linux 操作系统而言,将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF),供内核使用,称为内核空间,而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个进程使用,称为用户空间。
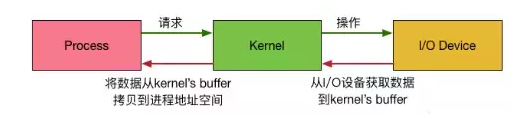
有了用户空间和内核空间,整个 Linux 内部结构可以分为三部分,从最底层到最上层依次是:硬件–>内核空间–>用户空间。我们都知道,为了 OS 的安全性等的考虑,进程是无法直接操作 IO 设备的,其必须通过系统调用请求内核来协助完成 IO 动作,而内核会为每个 IO 设备维护一个 Buffer。
内核包处理(Kernel Packet Processing)
回到最简单的传统实现,网卡接收到一个数据包,并向 Linux 内核发送一个中断,指出存在应该处理的数据包。内核停止其他工作,将上下文切换到中断处理程序,处理数据包,然后切换回其正在执行的操作。

这种上下文切换很慢,这在 90 年代对 10Mbit NIC 来说可能还不错,但是在 NIC 为 10G 且最大线路速率的现代服务器上,每秒可以带来大约 1500 万个数据包,而在具有 8 个核心的小型服务器上 这可能意味着内核每个内核每秒中断数百万次。
多年前,Linux 不再不断处理中断,而是添加了 NAPI,这是现代驱动程序用来提高高数据包速率性能的网络 API。在低速率下,内核仍然按照我们提到的方法接受来自 NIC 的中断。一旦有足够的数据包到达并超过阈值,它将禁用中断,而是开始轮询 NIC 并分批提取数据包。该处理在 “softirq” 或软件中断上下文中完成。这发生在系统调用和硬件中断的末尾,这是内核(而不是用户空间)已经在运行的时候。

这快得多,但是带来了另一个问题。如果要处理的数据包如此之多,以至于我们花了所有的时间来处理来自 NIC 的数据包,但又没有时间让用户空间进程实际上耗尽那些队列(从 TCP 连接等读取),会发生什么?最终,队列将满,我们将开始丢弃数据包。为了使公平起见,内核将在给定 softirq 上下文中处理的数据包数量限制为一定的预算。超出预算后,它会唤醒一个称为 ksoftirqd 的单独线程(您将在每个内核的 ps 中看到其中一个),该线程将在正常的系统调用/中断路径之外处理这些 softirq。使用标准流程调度程序调度该线程,该进程已经尝试公平了。

纵观内核处理数据包的方式,我们可以肯定地有机会停止处理。如果两次 softirq 处理调用之间的时间增加,则在处理数据包之前,数据包可能会在 NIC RX 队列中停留一段时间。这可能是导致 CPU 内核死锁的原因,也可能是导致内核无法运行 softirqs 的缓慢原因。
Links
-
NGTE 扩展阅读:关于 IO 模型、IO 多路复用参阅《Concurrent-Notes》;关于网络协议参阅《Network-Notes》
-
2017-调整 Linux I/O 调度器优化系统性能: Linux I/O 调度器是 Linux 内核中的一个组成部分,用户可以通过调整这个调度器来优化系统性能。本文首先介绍 Linux I/O 调度器的结构,然后介绍如何根据不同的存储器来设置 Linux I/O 调度器从而达到优化系统性能。