
监控指标
监控系统指标
监控已然成为了整个产品生命周期非常重要的一环,运维关注硬件和基础监控,研发关注各类中间件和应用层的监控,产品关注核心业务指标的监控。可见,监控的对象已经越来越立体化。在系统的质量保障中,我们常常希望能实现所谓的立体化监控,实时感知,提前预警。但是越全面,成本越高。所以,根据所处的时期从中挑选合适的监控方式更加重要。本节即着重讨论我们在搭建监控体系时候的指标考量。
指标的划分
对于监控指标,我们可以有很多种的划分方式。其一即根据目标来划分,将其分为系统指标、程序指标、业务指标等。
- 系统指标主要是网络 IO、网络延迟、磁盘 IO、磁盘占用大小、CPU 使用率、内存使用率、交换分区等等。
- 程序指标除了和系统指标一样的 CPU 使用率、内存使用率这种外部表现的指标之外,还有应用程序错误数、应用程序请求量、应用平均响应时间这种内部表现的指标;对于程序指标的落地我们常常就会徘徊于侵入式与非侵入式两种。
- 业务指标即每一个业务会经过的关键状态,都可以作为业务指标来监控。但是由于业务指标往往不具有通用性,所以,需要手动在程序里埋点打桩。因此,对业务指标的监控必然是侵入性的。
无论业务系统如何复杂,监控指标如何眼花缭乱,但万变不离其宗,监控的目的无非是为了解服务运行状况、发现服务故障和帮助定位故障原因。为了达成这个目的,Google SRE 总结的监控四个黄金指标对我们添加监控具有非常重要的指导意义。
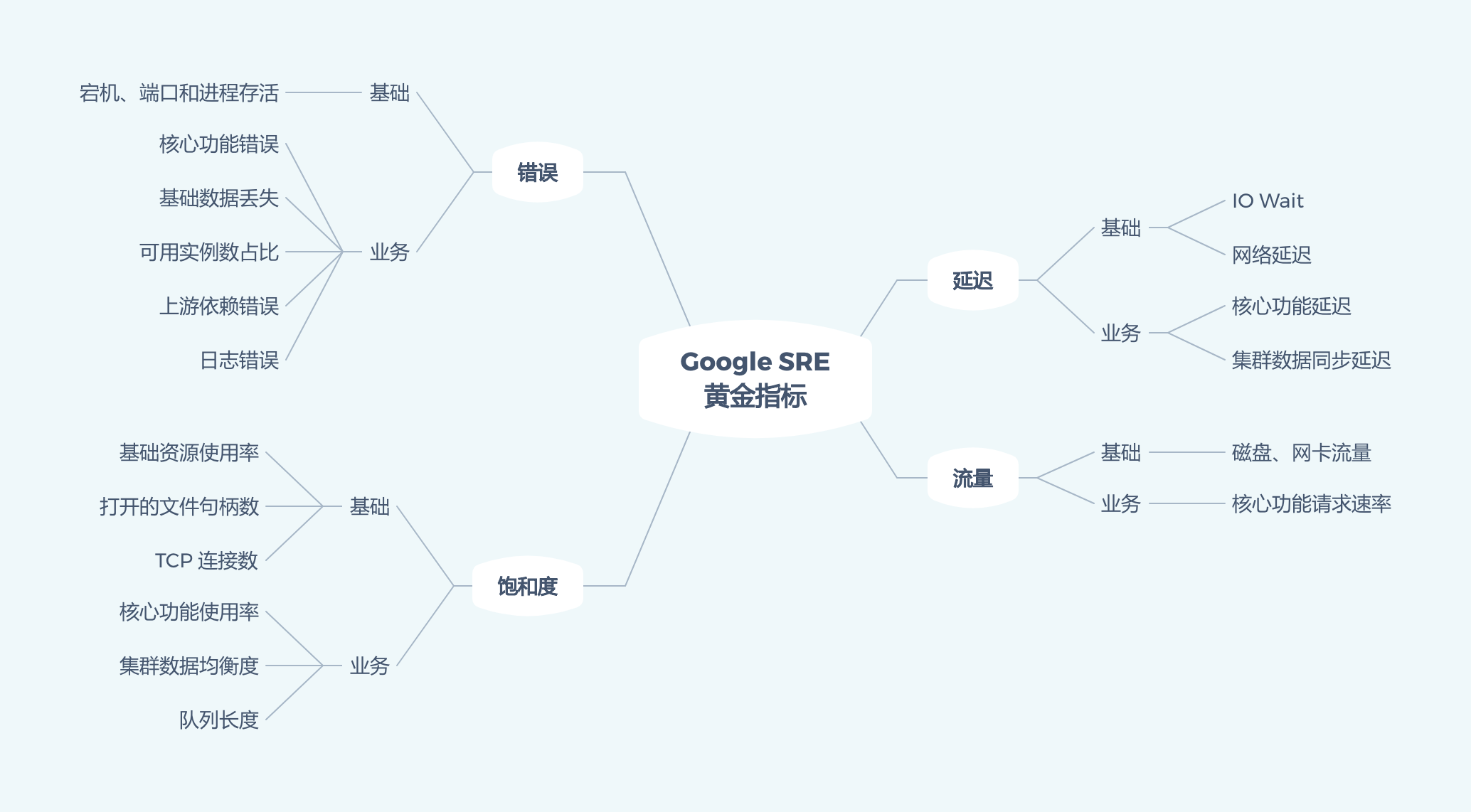
其中,吞吐量(Throughout)与时延(Latency)是衡量软件系统的最常见的两个指标,系统的吞度量(承压能力)与请求对 CPU 的消耗、外部接口、IO 等等紧密关联;单个请求对 CPU 消耗越高,外部系统接口、IO 影响速度越慢,系统吞吐能力越低,反之越高。吞吐量与时延是天生矛盾的,吞吐量增加也就意味着同一时间请求并发的增加;而由于资源的限制,同一时刻可以处理的请求数是固定的,取决于整个请求处理过程中最小的那个环节。当并发请求数大于这个值时,就会有请求排队等待被处理。所以,要提升服务的吞吐量,必定会增加整体延迟。另外,如果服务的延迟(单个请求的耗时)减少,由于排队的请求的等待时间也减少了,所以吞吐量会上升。
Logging,Metrics 和 Tracing
笔者在 DevOps 中的设计的三个关键方面即是:Logging,Metrics 和 Tracing,分别对应着日志聚合、监控与告警以及分布式追踪。Logging,Metrics 和 Tracing 有各自专注的部分:
- Logging:用于记录离散的事件。例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。
- Metrics:用于记录可聚合的数据。例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累加。
- Tracing:用于记录请求范围内的信息。例如,一次远程方法调用的执行过程和耗时。它是我们排查系统性能问题的利器。
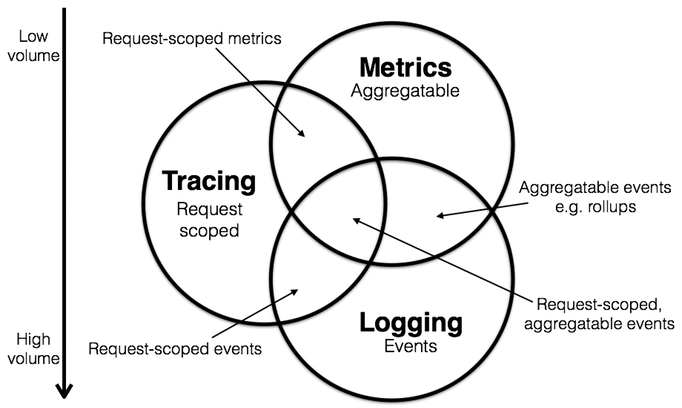
通过上述信息,我们可以对已有系统进行分类。例如,Zipkin 专注于 tracing 领域;Prometheus 开始专注于 metrics,随着时间推移可能会集成更多的 tracing 功能,但不太可能深入 logging 领域;ELK,阿里云日志服务这样的系统开始专注于 logging 领域,但同时也不断地集成其他领域的特性到系统中来,正向上图中的圆心靠近。
度量作为时序数据,是跨时间间隔的可聚合和测量的数字。度量针对存储和数据处理进行了优化,因为它们只是一段时间内聚合的数字。基于度量的监控的一个优点是度量生成和存储的开销是恒定的,它不像基于日志的监控那样,与系统负载的增加成正比,随之改变。这意味着磁盘和处理利用率不会根据流量的增加而改变。磁盘存储利用率仅根据时序数据库上存储的数据而增加,当你在应用程序代码中添加新指标或启动新服务/容器/主机时,才会发生这种情况。
度量比查询和聚合日志数据更有效。但是日志可以提供准确的数据,如果你想获得服务器响应时间的准确平均值,你可以记录它们,然后在 ELK 上编写聚合查询。度量不是百分之百准确,而是使用一些统计算法。类似 Prometheus 和常见的度量客户端这些工具实现了一些高级算法,以便为我们提供最准确的数字。
指标枚举
硬件监控
包括:电源状态、CPU 状态、机器温度、风扇状态、物理磁盘、raid 状态、内存状态、网卡状态。
服务器基础监控
- CPU:单个 CPU 以及整体的使用情况
- 内存:已用内存、可用内存
- 磁盘:磁盘使用率、磁盘读写的吞吐量
- 网络:出口流量、入口流量、TCP 连接状态
数据库监控
包括:数据库连接数、QPS、TPS、并行处理的会话数、缓存命中率、主从延时、锁状态、慢查询
中间件监控
- Nginx:活跃连接数、等待连接数、丢弃连接数、请求量、耗时、5XX 错误率
- Tomcat:最大线程数、当前线程数、请求量、耗时、错误量、堆内存使用情况、GC 次数和耗时
- 缓存:成功连接数、阻塞连接数、已使用内存、内存碎片率、请求量、耗时、缓存命中率
- 消息队列:连接数、队列数、生产速率、消费速率、消息堆积量
应用监控
- HTTP 接口:URL 存活、请求量、耗时、异常量
- RPC 接口:请求量、耗时、超时量、拒绝量
- JVM:GC 次数、GC 耗时、各个内存区域的大小、当前线程数、死锁线程数
- 线程池:活跃线程数、任务队列大小、任务执行耗时、拒绝任务数
- 连接池:总连接数、活跃连接数
- 日志监控:访问日志、错误日志
- 业务指标:视业务来定,比如 PV、订单量等
Links
- https://donggeitnote.com/2021/07/10/monitor/ 常见监控系统 Metric 实现讨论总结