
03.监控告警
监控告警
本部分主要着眼于服务端系统的监控与告警,前端相关的监控体系建设请参考 Web Series。
目的与方法
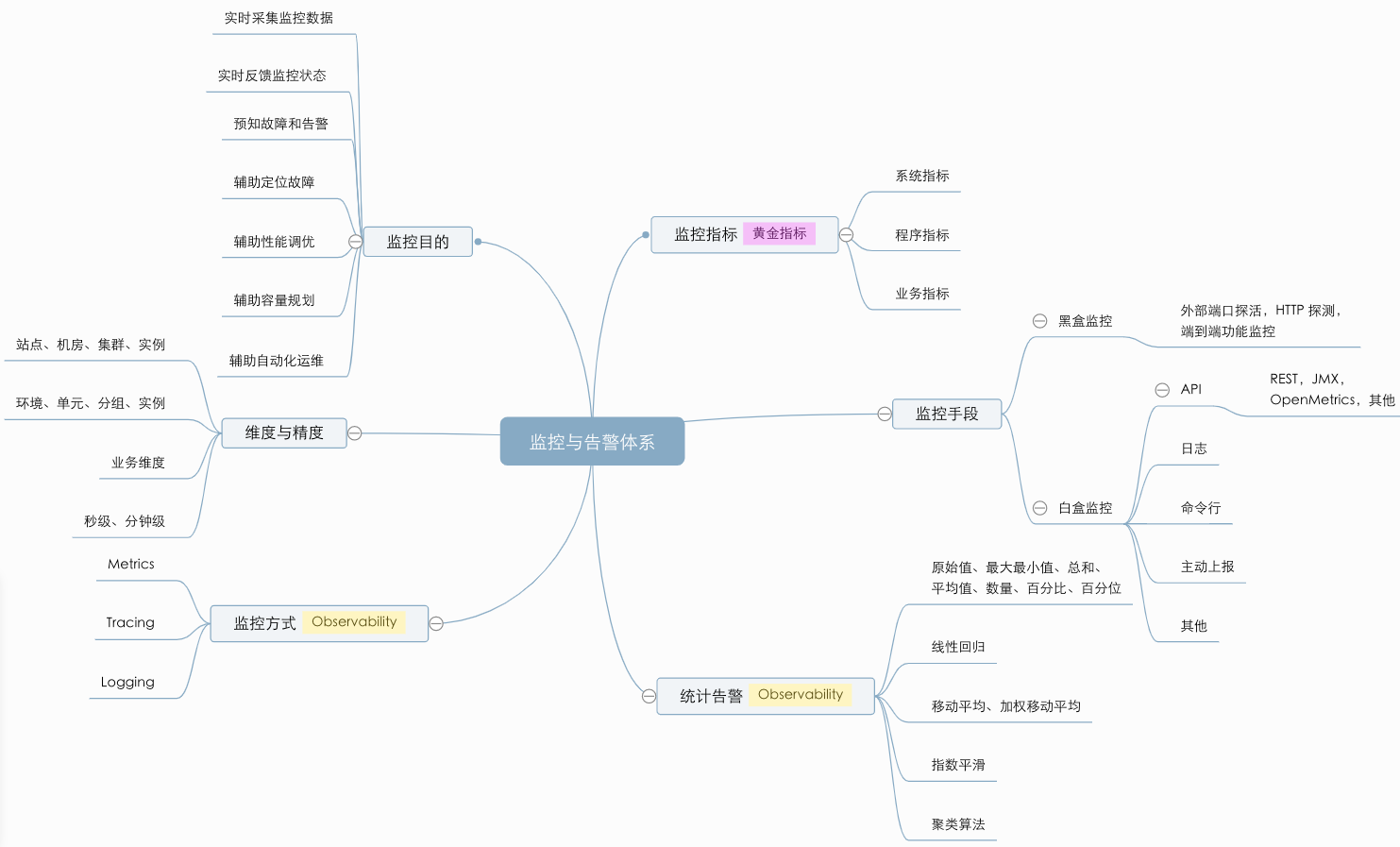
正所谓无监控,不运维,监控系统的地位不言而喻。不管你是监控系统的开发者还是使用者,首先肯定要清楚:监控系统的目标是什么?它能发挥什么作用?
- 实时采集监控数据:包括硬件、操作系统、中间件、应用程序等各个维度的数据。
- 实时反馈监控状态:通过对采集的数据进行多维度统计和可视化展示,能实时体现监控对象的状态是正常还是异常。
- 预知故障和告警:能够提前预知故障风险,并及时发出告警信息。
- 辅助定位故障:提供故障发生时的各项指标数据,辅助故障分析和定位。
- 辅助性能调优:为性能调优提供数据支持,比如慢 SQL,接口响应时间等。
- 辅助容量规划:为服务器、中间件以及应用集群的容量规划提供数据支撑。
- 辅助自动化运维:为自动扩容或者根据配置的 SLA 进行服务降级等智能运维提供数据支撑。
可见光有一套好的监控系统还不够,还必须知道如何用好它。一个成熟的研发团队通常会定一个监控规范,用来统一监控系统的使用方法。
- 了解监控对象的工作原理:要做到对监控对象有基本的了解,清楚它的工作原理。比如想对 JVM 进行监控,你必须清楚 JVM 的堆内存结构和垃圾回收机制。
- 确定监控对象的指标:清楚使用哪些指标来刻画监控对象的状态?比如想对某个接口进行监控,可以采用请求量、耗时、超时量、异常量等指标来衡量。
- 定义合理的报警阈值和等级:达到什么阈值需要告警?对应的故障等级是多少?不需要处理的告警不是好告警,可见定义合理的阈值有多重要,否则只会降低运维效率或者让监控系统失去它的作用。
- 建立完善的故障处理流程:收到故障告警后,一定要有相应的处理流程和 oncall 机制,让故障及时被跟进处理。
黑盒监控与白盒监控
传统上,如果组织中有 IT 运维部门,可能会有人使用 Nagios 等工具进行黑盒监控。这个工具给你一些信号,如系统停机、服务器 / 服务停机、CPU 消耗高等。这是必须的,非常有利于识别问题的症状,但没法知道根本原因。
一旦你得到的症状告诉你有什么不对劲。你需要深入了解并理解根本原因。这个时候需要用到白盒监控。白盒监控可以帮助你确定问题的根本原因,更重要的是,如果设计正确,可以通过查看系统上的某些趋势,对于可能出现的可预防问题,为你提供主动告警。因为应用程序的内部可以提供更有价值和可操作的告警,使得对边界场景和类似性能问题采取行动时更加主动,并在问题发生之前采取行动。
白盒监控还包括日志记录、度量和分布式跟踪,它们指的是一类使用系统内部报告的数据的监控工具和技术。我想写一下白盒监控范围内可观察性的这三个支柱。当正确使用这些工具时,通常你可能就不需要进行黑盒监控了,但如果你问我,继续进行黑盒监控当然很好。
白盒与黑盒分别从内部和外部来监控系统的运行状况,例如机器存活、CPU 内存使用率、业务日志、JMX 等监控都属于白盒监控,而外部端口探活、HTTP 探测以及端到端功能监控等则属于黑盒监控的范畴。
-
日志:日志可以包含服务运行的方方面面,是重要的监控数据来源。例如,通过 Nginx access 日志可以统计出错误(5xx)、延迟(响应时间)和流量,结合已知的容量上限就可以计算出饱和度。一般除监控系统提供的日志采集插件外,如 Rsyslog、Logstash、Filebeat、Flume 等都是比较优秀的日志采集软件。
-
JMX:多数 Java 开发的服务均可由 JMX 接口输出监控指标。不少监控系统也有集成 JMX 采集插件,除此之外我们也可通过 jmxtrans、jmxcmd 工具进行采集。
-
REST:提供 REST API 来进行监控数据的采集,如 Hadoop、ElasticSearch。
-
OpenMetrics:得益于 Prometheus 的流行,作为 Prometheus 的监控数据采集方案,OpenMetrics 可能很快会成为未来监控的业界标准。目前绝大部分热门开源服务均有官方或非官方的 exporter 可供使用。
-
命令行:一些服务提供本地的命令来输出监控指标。
-
主动上报:对于采用 PUSH 模型的监控系统来说,服务可以采取主动上报的方式把监控指标 push 到监控系统,如 Java 服务可使用 Metrics 接口自定义 sink 输出。另外,运维也可以使用自定义的监控插件来完成监控的采集。
-
埋点:埋点是侵入式的监控数据采集方式,其优点是其可以更灵活地为我们提供业务内部的监控指标,当然缺点也很明显:需要在代码层面动手脚(常常需要研发支持,成本较高)。
-
其它方式:以上未涵盖的监控指标采集方式,例如 Zookeeper 的四字命令,MySQL 的 show status 命令。
Links
- https://mp.weixin.qq.com/s/uk0qKcmlHwlCeC_zJhWgow 我经历过的监控系统演进史