
体系设计
自动化运维的体系设计
设计目标
指标精细透明
能够对系统各指标(系统、业务)进行精准、细致、体系化、实时的监控。通常来讲,衡量一个系统的监控体系做的是否足够好在于我们能否基于这套指标监控体系讲清楚当前业务发生的行为以及行为(正常行为和异常行为)产生的原因,超出当前业务或系统体系则需结合上下游系统一起来诊断。因此,我们一般会从两个视角来定义应用系统关键指标:业务视角和系统视角,这两个视角密不可分(如接口调用量和业务单量)。我们将指标分为面向最终结果的指标和面向过程的指标,这些指标同样也需要精确无歧义的定义,只有这样我们才能做到既能直观了解到系统发生了什么,也能快速定位背后的原因。最后,指标数据采集和展现的实时性非常重要,关系到我们能否快速了解系统最新的行为。
问题快速发现
能否及时主动的发现系统、业务异常。基于设计良好的监控指标体系,我们能快速掌握当前业务及系统运行情况,结合我们对业务或系统的专业了解能很快识别出当前系统运行是否正常。如果我们把这些业务或系统可能发生的异常行为通过相关的指标值来表达,则可以基于监控大盘与告警系统做到快速、主动的感知具体异常行为的发生。更近一步,若能再融入大数据算法模型,把告警升级为预警则效果更好。
预案自动执行
能够自动执行系统容灾或备份链路等系统预设的应急方案。如果我们能用监控指标数据准确定义异常发生时的系统行为且能做到快速识别并有明确的异常处理系统化方案,则可以基于预设的异常条件与处理方案在异常发生时自动触发系统流程来解决异常或降低异常对系统影响面,为后续开发的介入创造主动性。
变更安全可控
系统变更(业务规则、系统配置等)可灰度执行、数据影响可追溯、变更可快速回滚。通过分析线上故障发现,很大比例的故障是在系统发生变更时产生,针对变更(包括但不限于系统配置项变更、数据订正、业务规则切换、发布等),我们一定要有快速回滚方案。同时为了控制变更对系统可能产生的影响,一定要有变更灰度执行或灰度生效的机制,对于较常用的变更操作,特别是针对某类场景的组合类变更一定要有工具化、流程化、系统化的解决方案,尽可能降低因人为操作而导致出错的概率。
答疑高效支持
针对内部、外部的答疑(问题的定位、分析、排查)提供高效、自助的一站式解决方案。开发团队每天都会花费大量精力应对系统内部或外部的问题咨询与答疑,即使如此仍难免未能支持好所有人的需求。如果对系统的异常行为有清晰的定义和系统化排查与解决方案,则会极大的降低团队内部排查问题的工作量;再进一步,如果我们把常见的问题抽象成通用的问题分析、处理平台并提供一站式解决方案提供我们的客户,则不仅将极大降低开发团队在线上咨询方面处理的投入度,提升客户满意度,更重要的是避免了排查和解决问题时大量的线上操作行为,提升了系统安全与稳定性。
设计原则
核心思路是把一切变更操作标准化、流程化、自助化、自动化,降低人工干预程度,提升操作效率。实现这张架构图并迭代演进是一个跨多个职能团队协作(Cross-Functional Autonomous Teams)的工作,一切要以客户需求出发,进行持续的抽象和迭代。
一个好的自动化运维管控系统平台绝不仅仅是一个功能复杂的工具集,它应具备良好的系统化架构与设计,需要和业务系统密切配合又不关心业务处理的细节,基于(问题)场景为用户提供简单直接的解决方案。管控系统和业务系统最大的区别是管控系统需要为业务系统服务,帮助业务系统快速定位问题、解决问题,而不是替业务系统解决问题。一个极端的例子是管控系统里面包含大量直接操作业务系统库表的工具集并自定义组装业务变更的逻辑,这样一旦业务模型升级或逻辑发生变化时,该管控系统就失去了应用的意义。
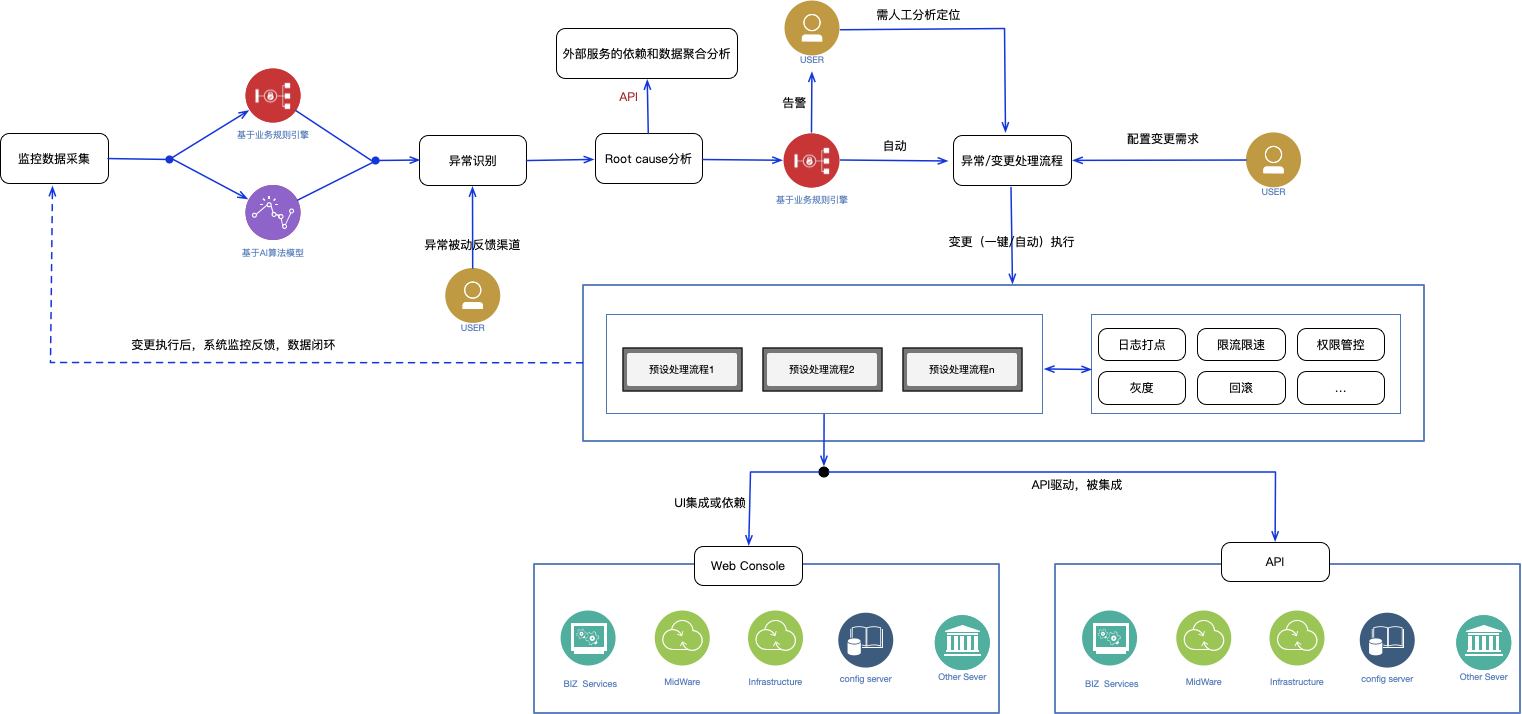
监控数据采集
监控大盘是观察系统的眼睛,一个系统的监控指标是否精细、完整和实时直接关系到这个系统的可运维性,监控指标又分为两大类:业务系统依赖的基础设施的运行时指标(系统类指标)和业务系统自身的业务指标(业务类指标,又分为业务结果数据数据和业务执行过程数据)。具体需要监控哪些数据主要从两个角度来梳理:系统类指标主要从可能会影响系统稳定的点来梳理哪些系统数据显性化有助于我们快速分析定位问题;业务类指标要从业务关心的目标结果数据以及影响这些目标结果达成的过程数据来梳理。目前集团内业务系统依赖的基础中间件、存储、VM 等关键系统指标数据非常全面,所以我们的侧重点在业务类指标的梳理和完善上。又由于指标采集的工具、数据分析计算平台都很完备,做好系统数据的监控采集并不难。
异常自动识别
我们常从异常、失败的角度来做数据的埋点、采集和监控,很大一部分异常可以直接通过设定单维度监控预警阈值来进行识别,从而做到精准监控;部分异常需要结合上下文或上下游依赖的数据利用业务知识做二次分析判断,如监控到快递公司某条线路的包裹时效出现波动,由于快递网络包裹配送是一个多角色协同的场景,具体哪个环节出了问题还需要结合更细粒度的数据来分析,这里可能会引入一些算法模型。还有部分异常当前还做不到自动判断,需要人工干预。此外,目前还有一种高阶的做法是基于 AI 技术做异常预警,基于当前的数据可以预测异常即将发生。
根因分析定位
这个领域基本上是模板驱动(Automated pattern discovery),前提是能够准确分析某类异常发生的根本原因且在对应的业务系统自动化体系里有现成的解决方案,否则就只能人工介入做决策。在依靠人工对异常问题处理的干预的同时,我们也能够沉淀更多的自动解决方案。
异常/变更处理
整个体系最重要的环节,包含预设的解决方案(系统具备的自动处理能力)、变更安全管控模块、对外核心处理能力的集成与驱动。
-
预设的解决方案:通过业务知识的沉淀形成所谓的专家库,这些沉淀一方面来自于系统业务逻辑设计时制定的规则,另外一方面来自于日常对各种问题处理时的积累,它是一个不断迭代优化的过程。
-
变更安全管控模块:自动化体系建设确实能够提升解决问题的效率,但也使线上系统变更的成本变得更低了,为保证线上变更的安全性,需要对关键的变更做好权限控制,配置类变更需要做好版本控制和灰度发布,同时也要具备变更暂停和快速回滚的能力。对于大数量的变更或大量任务重试等还需要考虑限速限流的能力,避免把下游系统“打垮”,同时基于“重监控、轻管控”的原则,系统也要做好变更操作的关键记录便于事后追溯,有些变更带来的影响具备较长的延时性,这时记录信息能够起到非常关键的作用。
-
对外核心处理能力的集成与驱动:自动化管控系统不应涉及到太多的业务细节,它可能需要基于某个场景来协同多个系统单元来提供整体的自动化/自助化解决方案,但是每个系统单元的能力应该由各系统独自封装并以 API 的形式提供出来。自动化运维管控系统是目标驱动的,不关心 API 实现的细节,如:“我们需要修正某个电子面单包裹信息里面的路由分单规则并更新信息至快递公司”,业务运维管控系统里面对小二提供的是个一键修正的功能。在管控系统实现层面可能会分别依赖电子面单系统、分单系统提供的不同 API,如计算路由分单码的接口、更新电子面单单据信息的接口、信息下发合作伙伴的接口等,至于每个接口内部如何实现管控系统并不关心。业务系统需要保证每个独立 API 具备可重试和幂等的原则,并由管控系统来保证结果的最终执行,即使执行不成功原则上也不影响原有业务系统的数据和逻辑(由于非事物一致性)。基础系统也同样遵循这个原则,只不过当前阿里体系内部研发基础设施非常完备,基本上常用的中间件体系都有配套良好的运维控制系统,因此我们对这类系统的运维变更需求都是登录对应中间件管控平台操作,也有部分中间件产品对外开放了常用的 API(基本都是 RESTful 风格)供业务自动化运维管控系统来集成。
安全机制
这里的安全指系统或数据安全。在研发人员心中自动化管控系统的重要性通常低于其服务的业务系统的,因此在系统架构设计、代码质量、研发规范、安全等级等方面投入的精力和重视程度会打折扣。笔者曾见到一些系统的安全 Bug 在流程里面校验不通过利用安全白名单机制绕开,这其实是不可取的,一个功能齐全的自动化运维管控系统对线上数据、业务变更的权限很大,可视作一个内部超级账号,即使内网很安全,我们也要避免意外发生。