
01.编年史
数据库编年史
数据库领域图灵奖获得者 Jim Gray 说过:所有的存储系统最终都会演变成数据库系统。(All storage systems will eventually evolve to be database systems.)。
1960 年代:第一个数据库
1961 年,Charles Bachman 等人设计了第一个计算机数据库管理系统(DBMS),这个网状模型(Network model)的数据库被称为 IDS(Integrated Data Store)。随后不久,IBM 在 1968 年开发了层次模型(hierarchical model)的数据库 IMS(Information Management System)。这两个数据库都是实验性的先行者。
无论是网状模型还是层次模型,最开始的数据库都非常难用,没有很多我们如今习惯的东西:
- 没有表,更没有 SQL;
- 数据粗暴存储,不得不通过指针遍历整个数据结构来进行查询;
- 逻辑层和物理层并不分离,没有独立的模式(schema),要增加属性,必须重新加载全部的数据然后转存;
最初的数据库没有独立存储数据,没有任何抽象,这导致开发者需要耗费大量精力来使用。
1970 年代:关系型数据库
到了 20 世纪 70 年代,IBM 的研究员 Edgar Frank Codd 看到他周围的程序员每天花费大量时间处理查询、改变模式和思考如何存储数据,于是他创造了今天众所周知的关系模型。关系模型建立之后,IBM 开启了著名的 System R 进行专项研究,该项目是第一个实现 SQL 和事务的 DBMS。System R 的设计对后来各类数据库产生了积极的影响。
关系模型摆脱了查询和数据存储之间的紧密耦合,查询独立于存储,数据库可以自由地在幕后进行优化,程序员无需知道背后的存储方式,只需要通过 SQL 与数据库进行交互,这对于开发者非常友好。1978 年 Oracle 发布,点燃了商业数据库的导火线。
20 世纪末:走向成熟
接下来的几十年里,数据库进入成长期,一步步走向成熟。早期的层次模型和网状模型消失了,关系型数据库成为主流。SQL 成为数据库标准查询语言,直到今天我们仍然在使用。
数据库商业化也越来越完善,同时开始出现如 PostgreSQL 和 MySQL 等开源数据库。由于大型商业数据库非常昂贵,一些互联网企业开始使用 MySQL 等开源数据库作为替代方案。
2000 年代:NoSQL
21 世纪伊始,互联网走向繁荣,突然间许多公司需要支持越来越多的用户,并且必须 24*7 不间断运行服务,为此互联网公司不得不在多台计算机上复制(replication)和分片(shard)存储他们的数据。
分片存储即将表按照某个关键字拆分成多个分片,例如按照年进行拆分,2000 年的数据存储在第一台机器上,2001 年的数据存储在第二台机器上,以此类推。这通常由数据库管理员来完成。同时为了让应用程序不修改代码、无感知地读写分片数据,必须要将一个中间件放到这些分片前面,将应用程序原本的 SQL 转换为支持分片的 SQL。如下图所示。
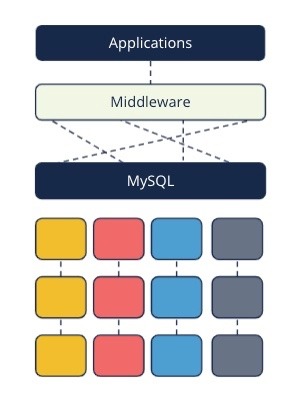
当然,这类方案也有一些缺点,例如:
- 不支持跨分片事务;
- 重新分片是困难的,会成为数据库管理员的噩梦;
Google 等公司如此分片存储数据库,目的是不惜一切代价来获得可扩展性,因为他们需要构建越来越大的应用,服务越来越多的用户。这些事情都是为了追求可扩展性。为此,这些公司还开发了 NoSQL,不惜放弃了关系模型,放弃了事务,放弃了数据一致性保证(有的 NoSQL 只保证最终一致性)。
前文提到,20 世纪 70 年代 Edgar Frank Codd 为了减轻开发人员心智负担而设计了关系型数据库,而 NoSQL 解决了应用程序所需的可扩展性,但又好似退回到了以前,程序员又要面临 NoSQL 功能不足的问题——也就是 Jim Gray 所说的:“所有的存储系统最终都会演变成数据库系统。”
2010 年代:分布式数据库
为什么要构建分布式数据库呢?通过历史发展分析应该相当清楚了,现有的数据库解决方案给开发者和管理员带来了过重的负担。当你开始一个新的大项目,选择一个单点数据库会牺牲掉未来的可扩展性,选择一个 NoSQL 又会让开发者承受额外的负担来解决问题,并且可能不支持事务等优秀的功能。
分布式数据库试图结合两者优点,构建成为两全其美的系统:既能支持完整的关系模型,又能提供高可扩展性和可用性。分布式数据库常被称为 NewSQL 或 Distributed SQL:无论怎么称呼,都指那些在多台机器运行的数据库。这不是说 NoSQL 是完全没用的,事实上人们在 NoSQL 上构建了许多成功的系统,但这要困难得多。Google 的分布式数据库 Spanner 论文中有一句话:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions. 我们认为最好让应用程序开发者来解决因过度使用事务而导致的性能问题,而不是让开发者总是围绕着缺少事务编写代码。
也就是说,事务是否会造成性能影响的应该由业务开发者来考虑,而作为一个数据库必须提供事务机制,来满足各种应用常见的需求。Spanner 论文发表后,开始涌现出许多优秀的开源分布式数据库,其中具有代表性的有:CockroachDB、TiDB、YugabyteDB 和最近开源的 OceanBase 等等。