
系列设计
Disruptor 设计
Disruptor 通过以下设计来解决队列速度慢的问题:
- 环形数组结构:为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。
- 元素位置定位:数组长度 2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心 index 溢出的问题。index 是 long 类型,即使 100 万 QPS 的处理速度,也需要 30 万年才能用完。
- 无锁设计:每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
核心组件
- RingBuffer: 被看作 Disruptor 最主要的组件,然而从 3.0 开始 RingBuffer 仅仅负责存储和更新在 Disruptor 中流通的数据。对一些特殊的使用场景能够被用户(使用其他数据结构)完全替代。
- Sequence:Disruptor 使用 Sequence 来表示一个特殊组件处理的序号。和 Disruptor 一样,每个消费者(EventProcessor)都维持着一个 Sequence。大部分的并发代码依赖这些 Sequence 值的运转,因此 Sequence 支持多种当前为 AtomicLong 类的特性。
- Sequencer:这是 Disruptor 真正的核心。实现了这个接口的两种生产者(单生产者和多生产者)均实现了所有的并发算法,为了在生产者和消费者之间进行准确快速的数据传递。
- SequenceBarrier: 由 Sequencer 生成,并且包含了已经发布的 Sequence 的引用,这些的 Sequence 源于 Sequencer 和一些独立的消费者的 Sequence。它包含了决定是否有供消费者来消费的 Event 的逻辑。
- WaitStrategy:决定一个消费者将如何等待生产者将 Event 置入 Disruptor。
- Event:从生产者到消费者过程中所处理的数据单元。Disruptor 中没有代码表示 Event,因为它完全是由用户定义的。
- EventProcessor:主要事件循环,处理 Disruptor 中的 Event,并且拥有消费者的 Sequence。它有一个实现类是 BatchEventProcessor,包含了 event loop 有效的实现,并且将回调到一个 EventHandler 接口的实现对象。
- EventHandler:由用户实现并且代表了 Disruptor 中的一个消费者的接口。
- Producer:由用户实现,它调用 RingBuffer 来插入事件(Event),在 Disruptor 中没有相应的实现代码,由用户实现。
- WorkProcessor:确保每个 sequence 只被一个 processor 消费,在同一个 WorkPool 中的处理多个 WorkProcessor 不会消费同样的 sequence。
- WorkerPool:一个 WorkProcessor 池,其中 WorkProcessor 将消费 Sequence,所以任务可以在实现 WorkHandler 接口的 worker 吃间移交
- LifecycleAware:当 BatchEventProcessor 启动和停止时,于实现这个接口用于接收通知。
RingBuffer
正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的 buffer。基本来说,ringbuffer 拥有一个序号,这个序号指向数组中下一个可用元素。
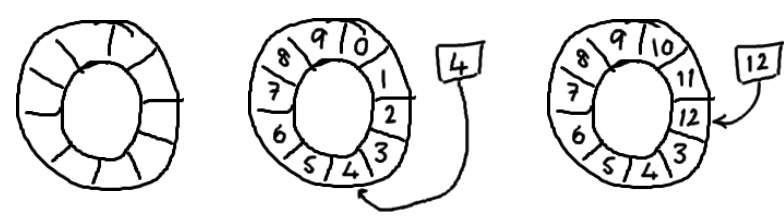
Disruptor 说的是生产者和消费者的故事。有一个数组,生产者往里面扔芝麻;消费者从里面捡芝麻。但是扔芝麻和捡芝麻也要考虑速度的问题:
- 消费者捡的比扔的快,那么消费者要停下来。生产者扔了新的芝麻,然后消费者继续。
- 数组的长度是有限的,生产者到末尾的时候会再从数组的开始位置继续。这个时候可能会追上消费者,消费者还没从那个地方捡走芝麻,这个时候生产者要等待消费者捡走芝麻,然后继续。
随着你不停地填充这个 buffer(可能也会有相应的读取),这个序号会一直增长,直到绕过这个环。要找到数组中当前序号指向的元素,可以通过 mod 操作:sequence mod array length = array index(取模操作)以上面的 ringbuffer 为例(java 的 mod 语法):12 % 10 = 2。很简单吧。
Java 内置队列的不足
PCP 又称 Bounded-Buffer 问题,其核心就是保证对一个 Buffer 的存取操作在多线程环境下不会出错。使用 Java 中的 ArrayBlockingQueue 和 LinkedBlockingQueue 类能轻松的完成 PCP 模型,这对于一般程序已经没问题了,但是对于并发度高、TPS 要求较大的系统则不然。
Java 的内置队列如下表所示。
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded | 加锁 | arraylist |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedlist |
| ConcurrentLinkedQueue | unbounded | 无锁 | linkedlist |
| LinkedTransferQueue | unbounded | 无锁 | linkedlist |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。我们就从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是 ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成 LinkedBlockingQueue 和 ConcurrentLinkedQueue 两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的 LinkedTransferQueue 都是通过原子变量 compare and swap(以下简称“CAS”)这种不加锁的方式来实现的。
通过不加锁的方式实现的队列都是无界的(无法保证队列的长度在确定的范围内);而加锁的方式,可以实现有界队列。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少 Java 的垃圾回收对系统性能的影响,会尽量选择 array/heap 格式的数据结构。这样筛选下来,符合条件的队列就只有 ArrayBlockingQueue。
锁的损耗
BlockingQueue 使用的是 package java.util.concurrent.locks 中实现的锁,当多个线程(例如生产者)同时写入 Queue 时,锁的争抢会导致只有一个生产者可以执行,其他线程都中断了,也就是线程的状态从 RUNNING 切换到 BLOCKED,直到某个生产者线程使用完 Buffer 后释放锁,其他线程状态才从 BLOCKED 切换到 RUNNABLE,然后时间片到其他线程后再进行锁的争抢。上述过程中,一般来说生产者存放一个数据到 Buffer 中所需时间是非常短的,操作系统切换线程上下文的速度也是非常快的,但是当线程数量增多后,OS 切换线程所带来的开销逐渐增多,锁的反复申请和释放成为性能瓶颈。BlockingQueue 除了使用锁带来的性能损失外,还可能因为线程争抢的顺序问题造成性能再次损失:实际使用中发现线程的调度顺序并不理想,可能出现短时间内 OS 频繁调度出生产者或消费者的情况,这样造成缓冲区可能短时间内被填满或被清空的极端情况。(理想情况应该是缓冲区长度适中,生产和消费速度基本一致)
下面是 ArrayBlockingQueue 通过加锁的方式实现的 offer 方法,保证线程安全。
public boolean offer(E e) {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
if (count == items.length)
return false;
else {
insert(e);
return true;
}
} finally {
lock.unlock();
}
}
对于上面的问题 Disruptor 的解决方案是:不用锁。
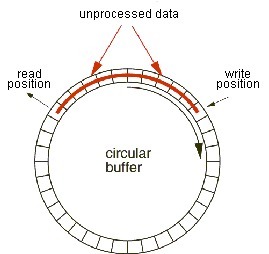
Disruptor 使用一个 Ring Buffer 存放生产者的产品,环形缓冲区实际上还是一段连续内存,之所以称作环形是因为它对数据存放位置的处理,生产者和消费者各有一个指针(数组下标),消费者的指针指向下一个要读取的 Slot,生产者指针指向下一个要放入的 Slot,消费或生产后,各自的指针值 p = (p +1) % n,n 是缓冲区长度,这样指针在缓冲区上反复游走,故可以将缓冲区看成环状。(Ring Buffer 并非 Disruptor 原创,Linux 内核中就有环形缓冲区的实现)使用 Ring Buffer 时:
- 当生产者和消费者都只有一个时,由于两个线程分别操作不同的指针,所以不需要锁。
- 当有多个消费者时,每个消费者各自控制自己的指针,依次读取每个 Slot(也就是每个消费者都会读取到所有的产品),这时只需要保证生产者指针不会超过最慢的消费者(超过最后一个消费者“一圈”)即可,也不需要锁。
- 当有多个生产者时,多个线程共用一个写指针,此处需要考虑多线程问题,例如两个生产者线程同时写数据,当前写指针=0,运行后其中一个线程应获得缓冲区 0 号 Slot,另一个应该获得 1 号,写指针=2。对于这种情况,Disruptor 使用 CAS 来保证多线程安全。
伪共享
ArrayBlockingQueue 有三个成员变量:
- takeIndex:需要被取走的元素下标
- putIndex:可被元素插入的位置的下标
- count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。

如上图所示,当生产者线程 put 一个元素到 ArrayBlockingQueue 时,putIndex 会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。这种无法充分使用缓存行特性的现象,称为伪共享。解决伪共享问题,可以在变量的前后都占据一定的填充位置,尽量让变量占用一个完整的缓存行。CPU1 上的线程更新了 X,则 CPU2 上的 Y 则不会失效。同样地,CPU2 上的线程更新了 Y,则 CPU1 的不会失效。
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
/**
* <p>Concurrent sequence class used for tracking the progress of
* the ring buffer and event processors. Support a number
* of concurrent operations including CAS and order writes.
*
* <p>Also attempts to be more efficient with regards to false
* sharing by adding padding around the volatile field.
*/
public class Sequence extends RhsPadding
{
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static
{
UNSAFE = Util.getUnsafe();
try
{
VALUE_OFFSET = UNSAFE.objectFieldOffset(Value.class.getDeclaredField("value"));
}
catch (final Exception e)
{
throw new RuntimeException(e);
}
}
// ... ...
}
在 Sequence 的实现中,主要使用的是 Value,但通过 LhsPadding 和 RhsPadding 在 Value 的前后填充了一些空间,使 Value 无冲突的存在于缓存行中。