
2023-关于 3D AIGC 的务实探讨
NeRF 基础概念
NeRF(Neural Radiance Field,即神经辐射场)就是将它们付诸现实的关键技术。它可以通过多角度拍摄的场景图像,重构出场景的 3D 表示,进而生成场景在任意视角和位置下的图片(新视角合成)。

近两年,NeRF 技术已经成为计算机视觉的热门领域,从 2020 年 Mildenhall 等人奠基性的工作 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 开始,NeRF 领域如火山爆发般产生了许多后续研究,特别是最近的改进工作 Instant NGP (Instant Neural Graphics Primitives) 更是被时代杂志列为了 2022 年最佳发明之一。
和之前的研究相比,上面提到的 NeRF 和 Instant NGP 两篇论文取得的重大突破是:
- NeRF 可以获得场景的高精度表示,从新角度渲染的图片十分逼真;
- 在 NeRF 工作的基础上,Instant NGP 大大缩短了训练和渲染时间,训练时间被缩短到一分钟以内,并且很容易做到实时渲染。
简单地说,神经辐射场就是把整个 3D 场景编码为神经网络的参数。为了能从任意新的视角渲染场景,神经网络至少需要学习空间中每个点的 RGB 颜色和体密度 $\sigma$(即这个点有没有被“占据”)。一点处的体密度与视角是无关的,但颜色是会随着视角变化而改变的(比如换个角度看到的物体就变了),所以神经网络实际上需要学习一个点$(x,y,z)$在相机不同视角$(\theta,\phi)$即经纬度)下的颜色$(r,g,b)$和体密度$\sigma$。
于是神经辐射场的输入是五维向量$(x,y,z,\theta,\phi)$,输出是四维向量$(r,g,b,\sigma)$:
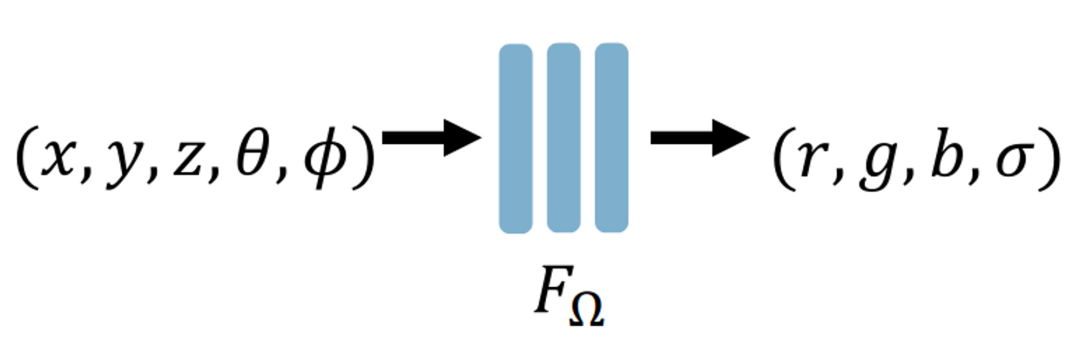
假设我们拥有了这样一个神经辐射场,将空间中每个点对应的$(r,g,b,\sigma)$进一步送到体渲染中,就可以得到当前视角$(\theta,\phi)$下视角看到的 2D 图像(体密度 (volume rendering) 的概念在图形学中常用在云、烟雾等介质的渲染中,它表示当一条光线穿过该点时,这个点有多大的概率会挡住光线。体密度衡量了这个点对光线最终颜色的贡献权重)。
体渲染
NeRF 训练和渲染的核心步骤是体渲染技术 (volume rendering)。体渲染可以把神经场“拍平”成一张 2D 图像,从而可以和基准图像进行比较。这个过程是可微的,从而可以用来训练网络!在介绍体渲染之前,先了解一下相机成像的基本原理。在图形学中,为了节约计算资源,会假设从相机发出的光线在击中场景中的点之后,该点的颜色就是光线与屏幕交点处像素的颜色:

然而在渲染大气、烟雾等类似介质时,光线会穿过介质而不是仅仅在介质表面处停止。而且在光线前进的过程中,会有一定比例的光线被介质吸收掉(不考虑散射和自发光)。吸收光线的这部分介质会对光线的最终颜色有贡献。体密度高的地方吸收的光线就多,这部分介质的颜色就显得浓重。所以光线最终的颜色是光线沿途经过的点的颜色的积分。
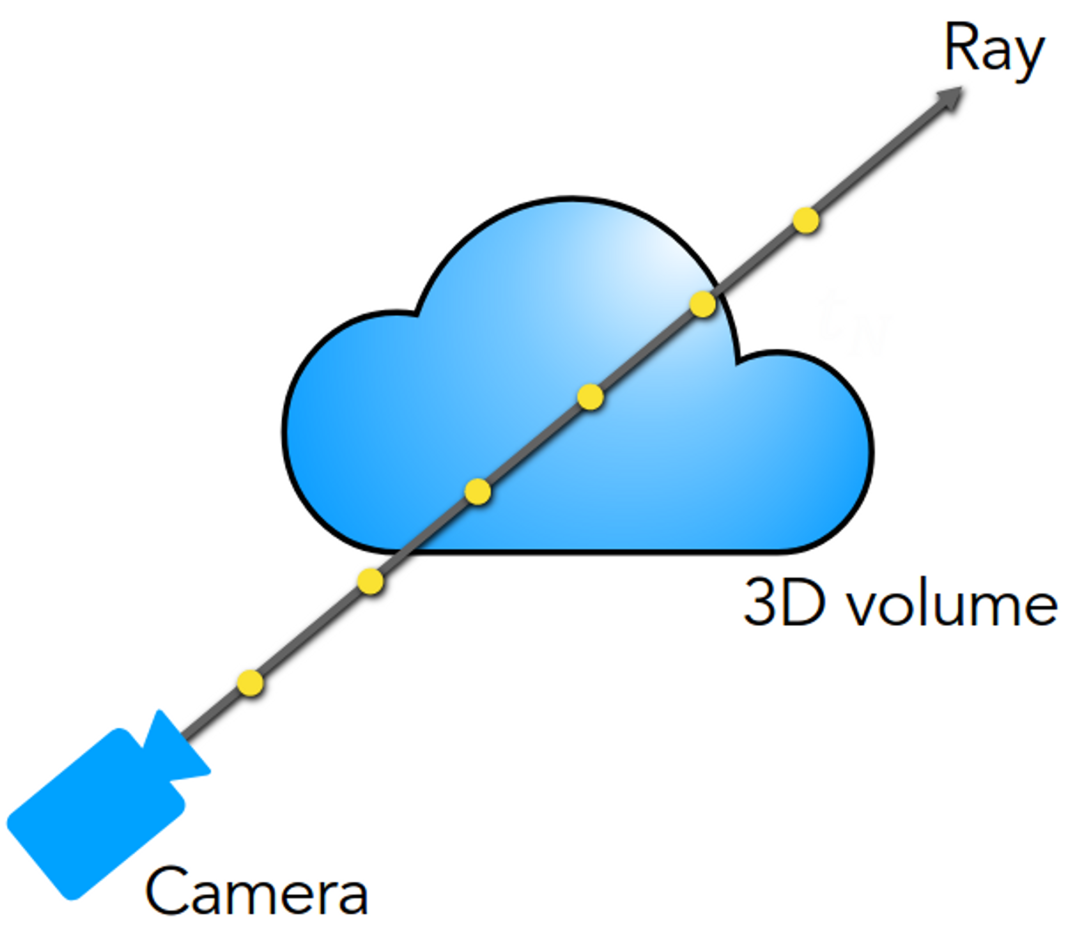
在实际计算时我们需要用离散和来逼近积分值。也就是在光线上采集一些离散点,将它们的颜色加权求和。这个离散化的具体过程我们就不介绍了,大家可以去看比如上面图片链接中的讲解。
NeRF 的训练
有了神经场和体渲染的预备知识,我们来介绍 NeRF 的训练。整个过程分为五步,如下图所示:
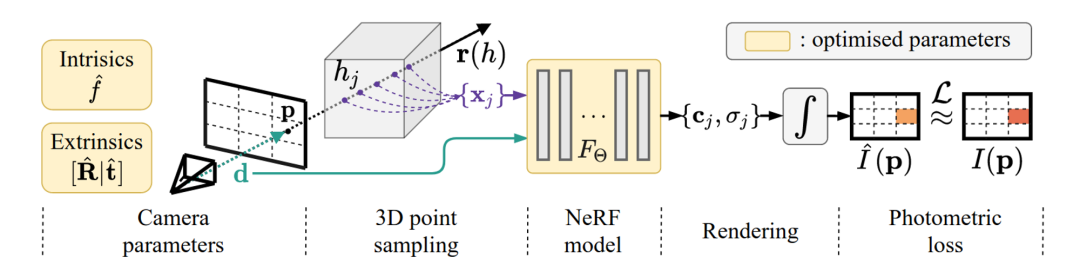
1.[Camera paramertes] 在准备好一组拍摄的 2D 图像后,首先解算每张图像对应的相机位姿参数。这一步可以使用如 COLMAP 等现成工具。COLMAP 会匹配不同图像中出现的场景共同点来计算相机位姿。此外我们假设整个场景位于范围是$[-1,1]^3$的立方体盒子内。
2.[3D point sampling] 对一张真实图像,从相机发出一条光线,光线穿过图像进入场景。光线和图像的交点$p$的像素值$I(p)$是基准颜色。我们在这条光线上离散采样得到若干个点。把这些采样点的空间坐标$(x,y,z)$和第一步解算出的对应的相机的姿态$\theta,\phi$组合起来作为神经网络的输入。
3.[NeRF model] 通过神经网络预测光线上每个采样点的颜色和密度。
4.[Rendering] 通过体渲染,我们可以用上一步神经网络输出的采样点的颜色和密度作离散和,近似计算对应光线的像素值$\hat{I}(p)$。
5.[Photometric loss] 把$\hat{I}(p)$和光线颜色的真值$I(p)$比较计算误差和梯度,就可以对神经网络进行训练。
Instant NGP 的改进
原始版本的 NeRF 给出的效果已经十分惊艳,但它的训练速度较慢,通常需要一到两天左右。这里主要的原因是 NeRF 使用的神经网络还是有点“大”了,2022 年 NVIDIA 的论文 Instant NGP 大大改进了这一点。Instant NGP 相对于 NeRF 的核心改进在于它采用了“多分辨率哈希编码” (Multi-resolution hash encoding) 的数据结构。你可以理解为 Instant NGP 把原始 NeRF 中神经网络的大部分参数扔掉,换成一个小得多的神经网络;同时额外训练一组编码参数 (feature vectors),这些编码参数是存储在网格的顶点上的,这样的网格一共有$L$层,它们按照分辨率从低到高,用于学习场景不同层次的细节。在每次训练时,小神经网络的参数和每层网格上只有点$(x,y,z)$周围的 8 个顶点中的编码参数会被更新。
Instant NGP 的另一个重要的工程优化是将整个网络实现在一个 CUDA kernel 中 (Fully-fused MLP),使得网络的所有计算都在 GPU 的 local cache 中进行。据论文所称这会带来 10x 的效率提升。
选择一个好问题
2D AIGC 基本上只有一种选择:生成图片。但是 3D 资产比 2D 内容复杂,因为 3D 资产有很多种:模型、贴图、骨骼、(关键帧)动画等等。这里我们只考虑最主流的资产,也就是 3D 模型。而 3D 模型的表示又分为网格(Mesh)、体素(Voxel)、点云、SDF、甚至上文提到的 NeRF 等等。一旦考虑到实际落地到渲染管线中,基本上只有一种主流表示可以选择:Mesh。

从 CG 工作流程来看,从文字生成 3D 模型分两步:
- AI 建模:给定文字输入,产出 3D 白模(即无贴图的模型);
- AI 画贴图:给定文字和白模,画上 diffuse 贴图或者 PBR 贴图组合(base color, metallic, roughness 等)。
从工业生产可控性的角度来说,用户会希望两步能够分离。而在学术界,大家更喜欢一步到位,对于可控性和 PBR 追求不高。
学术研究
学术界通常不太考虑 AI 建模和 AI 贴图的分离,往往会一步到位,输入文字,得到带贴图的 3D 模型。这部分工作有两个“流派”,下面我简单梳理一下。
“原生 3D 派”
这一流派的特点是直接在 ShapeNet 等 3D 数据集上进行训练,从训练到推理都基于 3D 数据。一些有趣的工作如下:
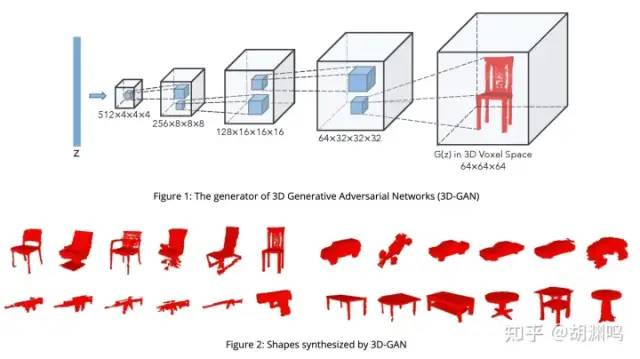
3D-GAN 是 NIPS 2016 比较经典的早期工作了。比较直观,就是 GAN 的 3D 版本,以 voxel 为单位,生成 3D 模型。用 ShapeNet dataset,输入是一个 Gaussian noise,2016 年的时候还没实现 text conditioning。
GET3D:通过 differentiable rasterizer (NVDiffRast) 加上类似 GAN 的架构,分别生成 mesh 和 texture,质量看起来也挺不错的,后面也会提到 differentiable rasterizer 会是 3D AIGC 很重要的基础算法。
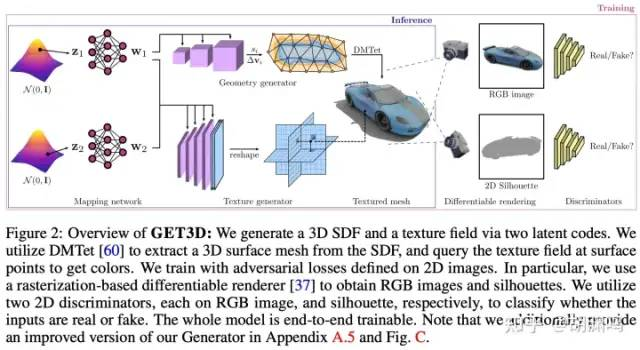
这一类基于 3D 数据的工作还包括 TextCraft (实现了 text conditioning)、AutoSDF 等等。这类方法生成速度往往较快,但是也有比较直接的问题:由于 3D 数据集往往相对 LAION 等巨型数据集都小至少 3 个数量级(后续有讨论),这一类方法比较难实现数据多样性。比如说,生成数据集中存在的汽车、家具、动物等完全没问题,但是生成需要“想象力”的模型,比如 “一只骑在马背上的兔子”、“带着皇冠的鹦鹉”、“手持大锤、生气的牛头怪” 等,就比较有挑战了。由于 Stable Diffusion 等 2D AIGC 模型的想象力完全可以描述后者,用户自然也会期待在 3D 空间的 AIGC 也能做到类似的效果:给出各种奇奇怪怪的文字,AI 能够得到高质量的 3D 模型。这种“想象力”(本质上是在多样的训练数据集中插值)是 AIGC 的核心价值所在,但是目前 3D 数据集却较难提供。
“2D 升维派”
既然 3D 数据集无法满足数据多样性的要求,不妨曲线救国,借助 2D 生成式 AI 的想象力,来驱动 3D 内容的生成。这个流派的工作在最近乘着 Imagen、Stable Diffusion 等 2D AIGC 基础模型的突破取得了很多进展,因此本文着重讨论。
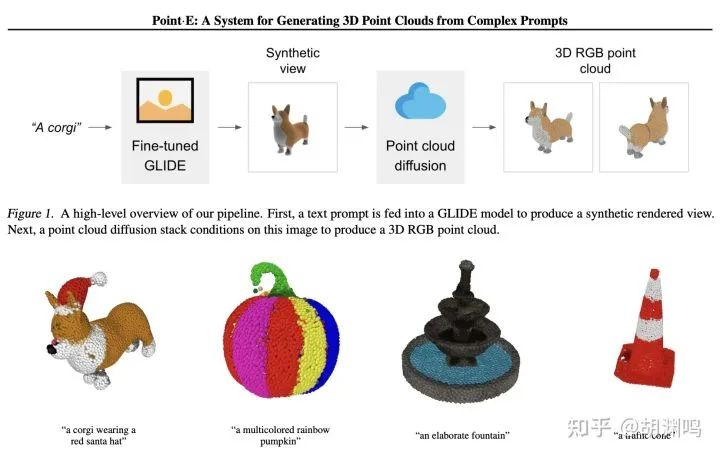
- OpenAI Point·E: 只需要 1-2 分钟就可以在单块 GPU 上生成点云。第一步是以文字为输入,用 2D diffusion 模型(选择了 GLIDE)生成一张图片,然后用 3D 点云的 diffusion 模型基于输入图片生成点云。
- DreamFusion:很有意思的工作,大体思路是通过 2D 生成模型(如 Imagen)生成多个视角的 3D 视图,然后用 NeRF 重建。这里面有个“鸡生蛋蛋生鸡”的问题:如果没有一个训练得比较好的 NeRF,Imagen 吐出的图会视角之间没有 consistency;而没有 consistent 的多视角图,又得不到一个好的 NeRF。于是作者想了个类似 GAN 的方法,NeRF 和 Imagen 来回迭代。好处是多样性比较强,问题也比较明显,因为需要两边来回迭代 15,000 次,生成一个模型就需要在 4 块 TPUv4 上训练 1.5 小时。
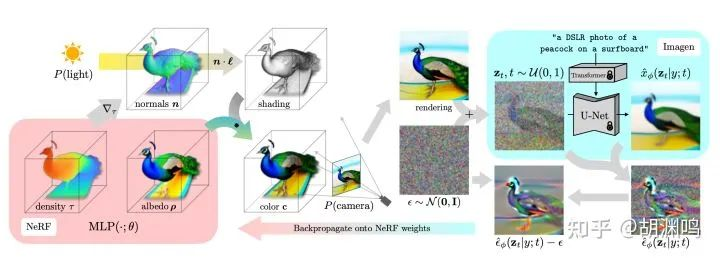
- Magic3D: DreamFields 的升级版本,巧妙之处在于将重建过程分为了两步。第一步仅采用 NeRF(具体来说,是上一篇提到的 InstantNGP)进行比较粗糙的模型重建,第二步则采用一个可微的光栅化渲染器。NeRF 比较适合从 0 到 1、粗糙重建,更多的表面细节还需要更加特定的算法,比如说 differentiable rasterizer。

目前 DreamFusion / Magic3D 这一类算法的性能瓶颈有两点:一是 NeRF,二是依赖的 Imagen / e-diffI SD 等 2D 生成模型。如果沿着这个算法思路进行优化,可能有下面两点机会:
-
NeRF 是否是最佳的 differentiable renderer? 从直觉上来说,并不是。NN 在 NeRF 中一开始只是作为一个 universal function approximator,如 Plenoxel 等工作其实说明了 NN 在 NeRF 中甚至不是必要的。还有个思路是直接不用 NeRF,直接用 differentiable rasterizer,比如说 nvdiffrast,一方面能够提速,另一方面由于直接在三角网格上优化,能够避免 NeRF 的结果转化到生产过程中需要用的三角网格的损失。
-
2D 生成式模型,如 Stable Diffusion 生成速度如果能够更快,那么对提速会相当有价值。GigaGAN 让我们看到了希望,生成 512x512 的图只需要 0.13s,比 SD 快了数十倍。
当然,SDF 也是可微性(differentiability)比较好的一种表示。Wenzel Jakob 组在这方面有一篇很棒的工作,重建质量非常棒,不过还没有和 AIGC 结合:

另外,除了生成通用资产,数字人的生成也是一个独立的有科研、商业价值的方向。影眸科技做的 ChatAvatar、MSRA 的 Rodin,都是最近有代表性的工作。
数据、算法、算力,谁更重要?
在 AI 领域一直有“数据、算法、算力三要素”的说法,这里我们讨论一下对于 3D AIGC 这三要素的重要性排序。
-
数据:目前 3D AIGC 比较大的一个问题是 3D 的数据集(ShapeNet 有 51 K 模型、Objaverse 有 800+K、商业模型网站 SketchFab 有 5M)和 2D 的 LAION 的 5B 数量级的数据差了至少三个数量级,并且这个状况很可能短时间不太容易改变,因为 3D 数据天然的稀缺性、收集的难度等客观原因。况且,就算收集到了大量数据,如何无损地把他们喂给深度学习系统,也是一个悬而未决的问题。
-
算法:这里面比较核心的算法是 differentiable renderer,目前看更像是 differentiable rasterizer。另外,效果比较好的工作基本上都有 multiscale 的特性,比如从 NeRF 到 coarse mesh 再到 fine mesh 逐级优化,一方面跳过 local minima,另一方面加快优化速度,具体如何设计这些 stages,为算法研发者留下了空间。换个角度,生成 2D 512x512 的图片开销尚能接受,如果不去想好的算法,直接暴力扩展到 3D,变成 512x512x512,这个计算量是非常可怕的。
-
算力:3D AIGC 会在训练、推理两部分都需要算力。基于前面的假设,3D AIGC 目前看来还是会基于 2D 的基础模型,如 Stable Diffusion,加上并没有真正大规模的 3D 数据集,3D AIGC 的训练部分其实并不需要除了 fine-tune 2D 模型以外的大量算力。在“推理”部分,目前主流的做法都依赖于 differentiable renderer,如果要提高这部分的性能,常见的写法是手写 CUDA,并且手动写出对应的 gradient kernels。而一个可微分的 SIMT 编程系统会显著加速相关的研发、提高正确性。(打个广告,这一点上看,Taichi 确实有一定的优势 :-)
综上,我认为对于 3D AIGC,算法 > 算力 > 数据。这意味着 3D AIGC 需要对计算机图形学、人工智能、可微编程框架等问题比较有洞见的团队来攻关。虽然学术界不断有激动人心的进展,AI 建模、画贴图要落地依然是很有挑战的。一是目前的技术依然不够成熟,无法达到工业生产的标准,甚至有很远的距离;二是市场方面的风险依然存在。后面我们会着重讨论。
商业落地
学术研究和商业落地中间存在着鸿沟,要跨过这个鸿沟,还有大量要考虑的产品化和商业化问题。其中最关键的问题无非是如下几点,直接决定产品是否能够有 Product-market fit (PMF):
- 到底解决了谁的问题?第一批用户是谁?(用户是谁?)
- 采购决策者是否有动力采用?(客户是谁?)
- 一个单一产品是否可以解决 3D 内容创作者的一个比较通用的问题?(能否标准化?是否 scalable?开发产品的 ROI 如何?是否能够真正成就一家产品公司,而不是项目公司?)
- 是否已有解决方案,如素材库、资产外包公司、程序化生成工具 Houdini?切换成本多高?(竞品是谁?)
- 商业模式是什么?SaaS?按量计费还是订阅制?GPU 成本如何?毛利能否做到令人满意的水平?
- 渠道是什么?PLG、SLG?
- 先发者的护城河在哪里?是更早转起来的数据飞轮,还是算法、产品力等?
落地场景
从市场角度,3D 资产的最大消耗者就是游戏产业。2022 年全球游戏行业营收是 $~200 B,比影视($26B)、建筑可视化、产品渲染等大不少。国内游戏市场规模(2022 年为 2650 亿 RMB)约为全球的 1/5,3D 各行业占比与全球类似。
具体比较游戏与影视行业:游戏行业中,不少重资产品类(如 3D MMORPG)研发成本的 1/3~1/2 用于美术,而美术开销中又有 1/2 以上是 3D 资产开销。影视行业中虽然也有特效镜头需要用到 3D 资产,但其中灯光、合成等环节却是比 3D 资产更大的开销。因此,游戏行业中的 3D 资产比重,要比影视大不少。
考虑到游戏市场整体比影视等其他市场大,而其中的 3D 资产占研发费用的比例又比其他市场更高,我们优先集中讨论 3D AIGC 在游戏行业的应用。这里又有两种:
- 面向专业的游戏美术。这边的主要挑战是游戏生产对于资产的质量要求是极高的,要做到质量达标,目前看来技术风险很大。
- 直接面向用户(UGC 场景)。质量要求会相对低一些。但是这里的问题是,和 2D 资产(图片)不一样,大众并不能直接消费 3D 资产,必须有一个好的场景。而 UGC 游戏是一个比较不错的场景。为玩家提供丰富创造自由度、并且创造巨大商业价值的游戏有很多,比如 Minecraft(史上销售份数最多的游戏)、Roblox(目前市值 ~$30B)、Fortnite(~$6B revenue) 等。
技术风险
3D AIGC 何时才能在生产中变得实用?说实话,这一点非常难预测:按照 2D AIGC 近期的发展速度,3D AIGC 也许一两年就能做到同等的质量;但是毕竟 3D AIGC 比 2D 要困难得多,如果说 5 年内没法实现,也完全有这个可能性。那么,生产环境可用 (production-ready) 的 AIGC 到底意味着什么?我个人认为要在现有工作的基础上(以目前的 text-to-3D SOTA Magic3D 举例),做到以下三点本质提升:
i. 质量好 10 倍(网格和纹理)
网格方面,在游戏资产需要有比较好的 topology(布线等)、UV 分布,对面数(poly count)也有较为严格的限制,目前的 3D AIGC 系统基本上无法满足这种需求。另外,即使不谈这波 AIGC 技术,自动重拓扑、自动展 UV 得出的效果依然无法和手动的结果匹敌。AI 建模实现合理的布线,是极其有挑战的事情,在学术界目前也较少有人研究。
纹理方面,对于 PBR 流程的游戏,需要 AI 生成较好的 base color、metallic、roughness、normal 等贴图,需要较好的从 2D AIGC 分离出 PBR channel 的算法(其实已经有一些了);如果是风格化的游戏,一张高质量的 diffuse 也可以满足需求,只要质量够高。如果依赖于多个视角的 2D AIGC 来绘制 3D 模型的贴图,如何剔除光照、阴影的影响,且保持视角之间的一致性,会成为比较大的挑战。
当然,也可以寄希望于随着半导体技术(缓慢)的发展,游戏能用上的机能更加富余一些,这样对于 3D 资产的质量(如面数等)要求也许会有所放松;另一方面,如果并非并非专业人员使用而是每个玩家都能创作内容,那么质量要求也会放松。
ii. 控制能力强 10 倍(几何、贴图风格等)
在游戏的工业化生产管线中,建模师的上游是原画。传统生产过程中,建模师的工作是在 3D 建模、画贴图过程中还原原画的效果。如果不改变这个流程,就需要 3D 生成模型能够以 2D 图片为输入,产出符合原画要求的模型贴图。
如果改变这个流程,不让原画给出输入了,直接生成 3D,就需要回答谁来用 3D AIGC 工具的问题(原画?主美?)。另外,在游戏中资产风格的统一性是至关重要的,这一点目前看也许要寄希望于 LoRA 之类的技术和深入的 prompt engineering 了 :-)
iii. 速度快 30 倍(小于 1 分钟生成时间)
我自己对这一点比较乐观。原因是在过去的 AI 系统研发历史上,速度往往是最容易突破的问题。只要东西能 work,卷速度往往是大家喜闻乐见的工作。比如,AlexNet 在 2012 年训练一次要 5~6 天,现在利用最新的 GPU 和分布式加速,train 一把只需要几分钟。另一方面,半导体领域摩尔定律的放缓也许是一个值得担忧的问题。
这三点技术风险中,质量是最让人担忧的。如果做不到真正满足生产要求的质量,那么有好的风格控制和速度也是白搭。而突破质量的方式,目前尚不明晰。
实际上,3D AIGC 要做到生产级别能用,除了算法层面的创新。必然还需要做很多工程层面的 dirty work。根据我之前多年在学术界的经验推断,这类工程上的工作其实并不是学术界的焦点(因为大多不会被科研界认为是学术创新),而需要工业界的工程团队静下心来深耕,这也是创业团队的机会所在。
市场风险
如果上面提到的技术风险都能解决,依然有不少市场风险是需要考虑的。这里我抛砖引玉列出一些可能会成为市场风险的点:
-
版权问题:这一点不用多说了,一直是 AIGC 生成图片争议比较大的问题,对 3D 同样成立。长期来看,在 3D 游戏这个主要应用场景,也许玩家并不在乎内容是不是 AI 生成的,只要质量达标,AI 带来的高生产力能够帮助工作室做出更好的作品,社会应该还是接纳的。当然,这个过程中一定伴随着大量的争议和讨论。
-
工作流风险:3D 工作流天然比 2D 更加复杂,已经形成的工作流更难改变。因为 3D 数据格式无法完全统一的问题,用户会更加倾向于在一个软件中完成所有操作。能否融入工作流,便成为了至关重要的一环。举个例子,不同 DCC 软件中的空间坐标系都不一样(Y-up/Z-up),更不要说 BSDF 模型等高度和软件架构设计耦合的数据表示了。法线贴图的 G 通道有 DirectX/OpenGL 两种格式,至今都无法统一:3D 资产内生的复杂性会导致软件之间无法统一,而这种不统一天然会导致 3D 资产跨软件传输时必然造成损耗,需要小心翼翼地避免、甚至开发专属工具。更进一步地,3D workflow 的可重塑性会因此比 2D 差。因此,3D AIGC 产品的工作流整合风险至少是值得花大精力去解决的问题。
-
“注意力退潮”:目前 AIGC 太火热,很多人的注意力都被吸引了,从而会愿意尝鲜一些自己并没有真正需求的产品。这会引出一系列问题,比如:Midjourney 是否真的有长线用户留存?有较长留存的用户到底是谁?到底解决了谁的工作中的刚需?付费率是否能到达到文章中推算的 5%?当 AI 热度褪去,是否依然会有目前数量级的活跃用户?我自己的看法是相对乐观的,虽然这些问题目前没法准确回答,我依然认为大众对 AIGC 的注意力褪去后,Midjourney 之类的应用会有不错的留存。
-
基础模型(Foundation models)抢饭碗:多模态是否会对 3D AIGC 有冲击?GPT-5/6/7/… 是否能够直接生成 3D 模型?有点类似 Jasper.ai/Grammarly 受到 ChatGPT 冲击一样。一种观点认为,如果底层模型足够强,确实是有可能让上层工具白干(就像搜索引擎大家基本只用 Google/百度一样,啥都能搜)。我的个人看法:3D AIGC 需要大量计算机图形学的 domain knowledge,需要同时有图形和 AI 的背景团队去做产品。其中,3D 图形人才的供给更加稀缺。有较好 AI 经验的图形团队去卷 3D AIGC,比顶尖 AI 团队学图形学来卷 3D AIGC,更加容易一些。(这一点 3D 和 2D 不一样,因为 2D 是可以相对直接地用 U-Net + 大数据量 + 通用算法搞出来的。)
-
“AGI 干掉一切”:如果几年后真的实现 AGI 了,直接让 AI 看 Maya/Max/Blender 建模教程、学会操作 Maya 就行了,而不用去重新定义一套新的生产工具。这是比较激进的看法了。我自己感觉最近 5 年这样发生的事儿并且能落地的可能性不太大。(如果放在 1 年前,我可能会认为 10 年内也不会发生这样的事儿。但是最近一年 AI 的发展改变了我的看法。当然,如果真的发生了,社会、商业都会发生巨大变化,也许人类可以直接迈入共产主义,人人都可以躺平,也不用辛苦地创业了。)
-
“计算机图形学不存在了”:假如 Midjourney 能够做到 60 FPS、帧间 consistenct、成本完全可控等,那么生成式 AI 会直接干掉实时图形的市场,“传统”图形技术(i.e., 基于渲染方程的光栅化、光线追踪技术)某种意义上讲就没有必要在主流市场存在了。我个人感觉 10 年内不需要担心这种风险,至少目前看来 AI 不是万能的。
-
“到底谁来用?”:整个游戏生产环节涉及到的岗位众多,公司老板、制作人、策划、主美、原画、建模师、TA、Level art/design,到底谁是用户?谁是客户(采购决策者)?推进 3D AIGC 在游戏工业化生产流程的切入,可能会成为和 3D CG workflow 切入同等重要的问题。(当然,如果切入前面提到的第二类 3D AIGC 需求,也就是面向大众的 3D AIGC,便不会有这个问题。但是,更加直击灵魂的问题就会变成 “为什么大众会有 3D 资产生成的需求?” 除了游戏,还有一点希望:圈子里广泛流传今年 WWDC 苹果会发布 Apple Glass,成为 XR 的 “iPhone” 时刻,也许会成为一个答案,因为一旦 VR/AR 让界面变成了 3D,大众便有了生成 3D 内容的需求。)
-
产品化/标准化:是否真的能够用通用的生成式 AI 模型实现比较广泛的品类的游戏的 3D 资产?画风上来说,游戏风格有仙侠、三国、赛博朋克、美漫等等,差别很大(好在基础模型如 Stable Diffusion 已经可以覆盖各种画风,并且通过 LoRA / ControlNet 等技术控制,一定程度上对画风进行了标准化);品类上来说,SLG、RPG、FPS 等游戏对 3D 资产的需求强度、质量要求、数量要求也许并不一样。有些品类比较重资产,有些则其实对 3D 资产没有太高的要求,甚至 2D 是更好的表现形式。好在不同品类的 3D 资产生产流程相对比较统一,存在标准化的可能性。总之,这一点我相对乐观:大家之所以觉得这一次 AI 浪潮机会多,本质上就是 基础模型(GPT、SD 等)足够通用,提供了制造出标准化产品的机会,让产品开发 ROI 变高了,以前一些做项目的机会,现在可以做产品了。
-
“Moat(护城河)在哪里?”:A16Z 的一篇文章 “Who Owns the Generative AI Platform?” 提到了已有的生成式 AI 应用层产品的潜在困局:(特别是图像、文本 AIGC 工具)大家都用一样的底层模型、一样的数据集,比较难真正形成差异化和护城河。3D 的 AIGC,尚未是完全解决的问题。产品开发者必须有自己的算法创新,才能形成护城河,保持领先地位。
-
“下游收缩”:3D 数字资产的生成市场能做多大,主要还是看下游(游戏等行业)有多强烈的需求、多少研发成本。而游戏满足的是人类娱乐的需求,这一点是刻在基因里的,很难改变,因此游戏行业本身并不会在未来缩水。加上全球游戏行业盘子很大,我感觉这一点不用太担心,按目前的情况看反而是非常积极的。
已经有的产品

我们还是聚焦到 3D。考虑到 AI 直接生成 3D 模型比较难,可以退而求其次,做给定模型和 prompt,产出贴图。甚至也可以只产出用于 tiling 的贴图,不考虑几何了。于是出现了下面三种产品:
-
生成平面贴图(生成平铺材质,本质是 2D 问题。比下面的 AI 画贴图简单一些,因为不需要考虑几何):
- barium.ai 主打生成 PBR 贴图,已经被 Unity 买了;
- spline.design 很早就实现了基于 AIGC 的 2D 贴图生成功能;
- Maliang: 很有意思的产品,在生成贴图的基础之上加上了编辑投影功能,更加实用。官网在这里。
-
根据几何(mesh)在 UV 空间生成贴图(“AI 画贴图”):国际上有几款产品,都比较早期:
- Meshy.ai 是目前能够公开访问,主要做的是给白模在 UV 空间上贴图,使用体验类似 Midjourney。生成一次大概要半分钟。
- Leonardo.ai 放出了一个很炫酷的 demo(可以到他们的 twitter 查看),不过暂时还没有上线。他们表示会在月底上线 Blender 插件,可以期待一下。
- Polyhive.ai 也实现了这个功能,不过生成一次要 5 分多钟。
这类产品和平面贴图工具主要的不同在于对于几何的理解。比如说,能够比较智能地在网格的头部画上眼睛,而不仅仅是生成 tiling 的纹理。下面是 Meshy.ai 的 demo,比较有代表性,给白模上贴图:
- 直接生成 3D 模型(AI 建模 + 贴图)
目前还没有真正公测的产品。Luma.ai 的 imagine 目前还不能公开访问,而 Kaedim3D 稍有争议:虽然之前号称是 AI 建模,但是目前看起来很可能还是需要人工辅助。除此之外,在 2D 游戏资产生成领域大红大紫的 Scenario.gg 也表示自己有要做 3D 资产生成的愿景,不过还没做出动作。
总结
总的来说,我认为 3D AIGC(特别是 text to 3D mesh,从文本生成 3D 模型和贴图),在学术界是非常值得探索的 topic,在商业界也是值得一试的创业机会。我个人认为几个有价值的推断:
- 要实现能够产品化、 标准化的通用 text to 3D,数据多样性非常重要。而目前 LAION 这样的 2D 数据集带来的数据多样性,会比 3D 数据集数据量大三个数量级,因此 2D 生成基础模型,如 Stable Diffusion,会是 3D AIGC 必要的宝贵资源。短时间内,看起来 “2D 升维派” 会比 “原生 3D 派” 更像是 3D AIGC 的主流方法;
- (图形)算法和算力会比数据更加重要,需要图形行业的团队深耕产业需求、甚至做出一些底层基础设施的创新(如带 AutoDiff 的并行编程系统)来满足算法研发、提高计算速度;
- 游戏行业,很可能会是 text to 3D mesh 的首选市场;
- Text to 3D mesh 的技术风险和市场风险共存;
- 即使由于上述风险做这事儿很可能失败,由于游戏行业对于 3D 资产的需求足够强、市场够大,且具备有标准化产品的可能性,从 ROI 角度来说依然是值得尝试的。
引用一下 Amara’s Law:
We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.
新技术的短期影响往往被人们高估,而长期影响却会被低估。技术创新是推动人类进步的重要力量,但创新之路充满着不确定性和风险,需要决心与勇气去面对。只有在相互支持和鼓励的氛围下,创新才能更好地发挥其作用,推动社会不断向前发展。
如果创新者畏惧失败,往往不会成功。3D AIGC 的风险与机会并存,不论谁去做,只要做成了都会有巨大的社会价值,都应该得到同行者的祝福。因此,虽然到目前只是浅浅的调研和早期产品实验,我觉得还是应该分享一下自己的看法,希望也能够帮助对这个方向有兴趣的同行者少走点弯路。