
tinyurl
如何设计一个短网址服务(TinyURL)?
使用场景(Scenario)
微博和 Twitter 都有 140 字数的限制,如果分享一个长网址,很容易就超出限制,发布出去。短网址服务可以把一个长网址变成短网址,方便在社交网络上传播。
需求(Needs)
很显然,要尽可能的短。长度设计为多少才合适呢?
短网址的长度
当前互联网上的网页总数大概是 45 亿(参考 http://www.worldwidewebsize.com),45 亿超过了 $$2^{32}=4294967296$$,但远远小于 64 位整数的上限值,那么用一个 64 位整数足够了。
微博的短网址服务用的是长度为 7 的字符串,这个字符串可以看做是 62 进制的数,那么最大能表示$${62}^7=3521614606208$$个网址,远远大于 45 亿。所以长度为 7 就足够了。
一个 64 位整数如何转化为字符串呢?,假设我们只是用大小写字母加数字,那么可以看做是 62 进制数,$$log_{62} {(2^{64}-1)}=10.7$$,即字符串最长 11 就足够了。
实际生产中,还可以再短一点,比如新浪微博采用的长度就是 7,因为 $$62^7=3521614606208$$,这个量级远远超过互联网上的 URL 总数了,绝对够用了。
现代的 web 服务器(例如 Apache, Nginx)大部分都区分 URL 里的大小写了,所以用大小写字母来区分不同的 URL 是没问题的。
因此,正确答案:长度不超过 7 的字符串,由大小写字母加数字共 62 个字母组成
一对一还是一对多映射?
一个长网址,对应一个短网址,还是可以对应多个短网址? 这也是个重大选择问题
一般而言,一个长网址,在不同的地点,不同的用户等情况下,生成的短网址应该不一样,这样,在后端数据库中,可以更好的进行数据分析。如果一个长网址与一个短网址一一对应,那么在数据库中,仅有一行数据,无法区分不同的来源,就无法做数据分析了。
以这个 7 位长度的短网址作为唯一 ID,这个 ID 下可以挂各种信息,比如生成该网址的用户名,所在网站,HTTP 头部的 User Agent 等信息,收集了这些信息,才有可能在后面做大数据分析,挖掘数据的价值。短网址服务商的一大盈利来源就是这些数据。
正确答案:一对多
如何计算短网址
现在我们设定了短网址是一个长度为 7 的字符串,如何计算得到这个短网址呢?
最容易想到的办法是哈希,先 hash 得到一个 64 位整数,将它转化为 62 进制整,截取低 7 位即可。但是哈希算法会有冲突,如何处理冲突呢,又是一个麻烦。这个方法只是转移了矛盾,没有解决矛盾,抛弃。
正确答案:分布式发号器(Distributed ID Generator)
如何存储
如果存储短网址和长网址的对应关系?以短网址为 primary key, 长网址为 value, 可以用传统的关系数据库存起来,例如 MySQL, PostgreSQL,也可以用任意一个分布式 KV 数据库,例如 Redis, LevelDB。
如果你手痒想要手工设计这个存储,那就是另一个话题了,你需要完整地造一个 KV 存储引擎轮子。当前流行的 KV 存储引擎有 LevelDB 何 RockDB,去读它们的源码吧 :D
301 还是 302 重定向
这也是一个有意思的问题。这个问题主要是考察你对 301 和 302 的理解,以及浏览器缓存机制的理解。
301 是永久重定向,302 是临时重定向。短地址一经生成就不会变化,所以用 301 是符合 http 语义的。但是如果用了 301, Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户的 Cookie, User Agent 等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
所以,正确答案是 302 重定向。
可以抓包看看新浪微博的短网址是怎么做的,使用 Chrome 浏览器,访问这个 URL http://t.cn/RX2VxjI,是我事先发微博自动生成的短网址。来抓包看看返回的结果是啥,
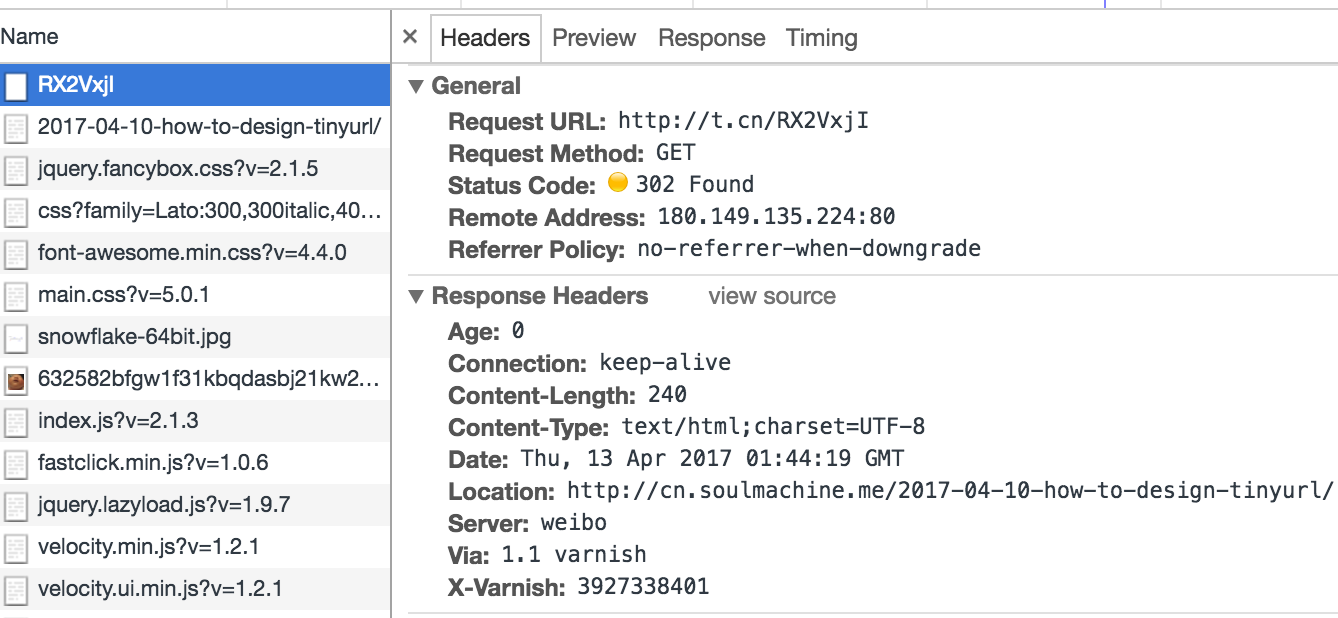
可见新浪微博用的就是 302 临时重定向。
预防攻击
如果一些别有用心的黑客,短时间内向 TinyURL 服务器发送大量的请求,会迅速耗光 ID,怎么办呢?
首先,限制 IP 的单日请求总数,超过阈值则直接拒绝服务。
光限制 IP 的请求数还不够,因为黑客一般手里有上百万台肉鸡的,IP 地址大大的有,所以光限制 IP 作用不大。
可以用一台 Redis 作为缓存服务器,存储的不是 ID->长网址,而是 长网址->ID,仅存储一天以内的数据,用 LRU 机制进行淘汰。这样,如果黑客大量发同一个长网址过来,直接从缓存服务器里返回短网址即可,他就无法耗光我们的 ID 了。