
MicroService-CheatSheet
MicroService CheatSheet | 微服务理念、架构与实践速览
微服务是系统或应用程序中的自包含独立组件。每个微服务都应该有明确的作用域和责任,理想情况下,一个微服务只做一件事。它应该是无状态的或有状态的,如果它是有状态的,它应该带有自己的持久层(即数据库),不与其他服务共享。软件开发团队基于微服务架构以更分散的方式开发可重用的独立组件。他们可以为每个微服务使用自定义框架、依赖关系集,甚至是完全不同的编程语言。微服务也有助于实现可扩展性,因为它们本质上是分布式的,并且每个微服务都可以独立增长或复制。
微服务微前端,都是希望将某个单一的单体应用,转化为多个可以独立运行、独立开发、独立部署、独立维护的服务或者应用的聚合。如康威定律(Conway’s Law)所言,设计系统的组织,其产生的设计和架构等价于组织间的沟通结构;微服务与微前端不仅仅是技术架构的变化,还包含了组织方式、沟通方式的变化。微服务与微前端原理和软件工程,面向对象设计中的原理同样相通,就像高级编程语言一样,微服务以更抽象能力提供了更好地描述问题的方式;并且它们都是遵循单一职责(Single Responsibility)、关注分离(Separation of Concerns)、模块化(Modularity)与分而治之(Divide & Conquer)等基本的原则。
HA CheatSheet | 高可用架构手册或者 Spring Boot CheatSheet,微前端。
很多人认为微服务是一种细粒度的 SOA,在去掉了 SOA 中的 ESB 之后,微服务变得更加灵活、性能更强。Martin Fowler 曾经总结过微服务实施的前提包括:
计算资源的快速分配
基本的监控
快速部署
虽然如 Spring Cloud、Dubbo 微服务框架在各方面已经非常完善,但随着云原生计算基金会的壮大,基于 Kubernetes 的微服务在社区中的热度越来越高,也开始有很多公司开始利用这一套技术栈来构建微服务。
单体应用与微服务
微服务是一个简单而泛化的概念,不同的行业领域、技术背景、业务架构对于微服务的理解与实践也是不一致的。与微服务相对的,即是单体架构的巨石型(Monolithic)应用,典型的即是将所有功能都部署在一个 Web 容器中运行的系统。虽然很多的文章对于巨石型应用颇多诟病,但并不意味着其就真的一无是处,毕竟微服务本身也是有代价的。除了组织的结构之外,微服务往往还要求组织具备快速的环境提供(Rapid Provisioning)与云开发、基本的监控(Basic Monitoring)、快速的应用发布(Rapid Application Deployment)、DevOps 等能力。


架构衍化
团队规模不大的时候,单块架构比微服务架构具有更高的生产率(Productivity),建立微服务架构需要额外的开销来支持和管理微服务,从而降低生产率;但是随着业务复杂性的增加和团队规模的扩大,单块架构比微服务架构的生产率下降更趋明显,当复杂性达到一个点,微服务的松散耦合自治特性减缓了生产率的下降趋势,微服务架构的生产率会优于单块架构。换言之,如果团队能力强,不管用单块还是微服务,都能找到好的管理复杂性的手段,所以说团队的技能才是管理复杂性的关键。
在系统早期流量较少时,只需一个应用将所有功能都部署在一起,以减少部署节点和成本;此时,用于简化增删改查工作量的数据访问框架 (ORM) 是关键。随着流量逐步增大,我们过渡为了包含多个相互隔离应用的垂直应用架构;如下图 y 轴的衍化,即是将不同职能的模块分成不同的服务,也逐步开始了微服务化的步伐。接下来,随着垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中台;此时我们即需要考虑应用间的协调治理,也需要考虑如下图所示的 x 轴水平扩展以及 z 轴分库分表的数据库扩展等操作。系统继续衍化,服务数目、体量持续增加,小服务资源的浪费等问题逐渐显现,需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率;此时对于资源调度与治理越发的关键。

存储分隔与无状态服务
在编码中,我们往往倾向于使用纯函数来描述抽象逻辑,以保证代码的可读性与可测性;并且纯函数也可以非常方便地使用并发编程或者结果缓存等方式来进行扩展与优化。而在微服务系统中
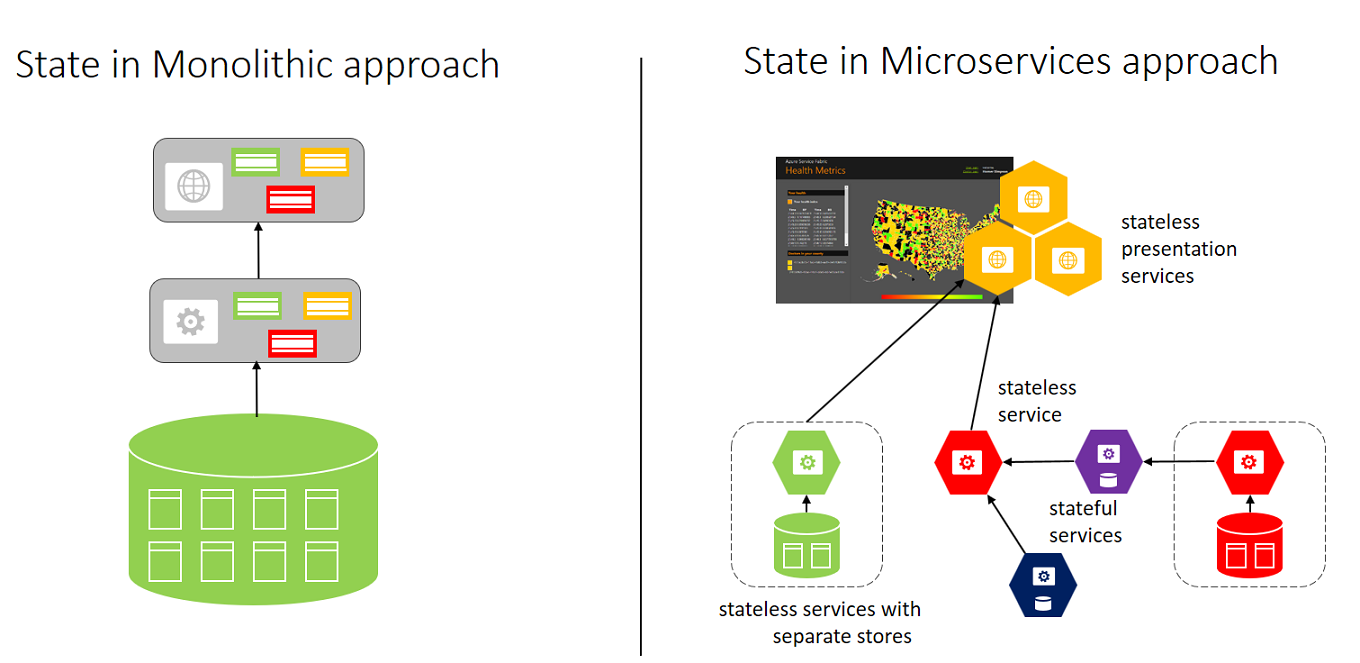
The monolithic approach on the left has a single database and tiers of specific technologies.
The microservices approach on the right has a graph of interconnected microservices where state is typically scoped to the microservice and various technologies are used.
In a monolithic approach, typically the application uses a single database. The advantage is that it is a single location, which makes it easy to deploy. Each component can have a single table to store its state. Teams need to strictly separate state, which is a challenge. Inevitably there are temptations to add a new column to an existing customer table, do a join between tables, and create dependencies at the storage layer. After this happens, you can’t scale individual components.
In the microservices approach, each service manages and stores its own state. Each service is responsible for scaling both code and state together to meet the demands of the service. A downside is that when there is a need to create views, or queries, of your application’s data, you need to query across disparate state stores. Typically, this is solved by having a separate microservice that builds a view across a collection of microservices. If you need to perform multiple impromptu queries on the data, each microservice should consider writing its data to a data warehousing service for offline analytics.
所谓的“单体”,即把所有服务代码结合一个“项目”打包发布,也就是一个“普通”的项目并且共用一个数据库,但每个服务的表名都有服务的标识(约定),例如商品服务的相关表名以“KW_GOODS_XXX”命名,订单服务的相关表名以“KW_ORDER_XXX”命名,支付服务的相关表名以“KW_PAYMENT_XXX”命名,充值服务的相关表名以“KW_RECHARGE_XXX”命名,对账服务的相关表名以“KW_ACCOUNT_XXX”命名,服务之间决不能跨越服务操作数据库表,必须按照“业务流程设计”调用,所以“单体”只是体现在物理实施层面,逻辑层面始终保持着“微服务”的分布式特性,保留了各种不用修改一行代码即可灵活扩展的可能性。
微服务的挑战
微服务应用往往由多个粒度较小,版本独立,有明确边界并可扩展的服务构成,各个服务之间通过定义好的标准协议相互通信。在构建微服务架构时,模块化(Modularity)和分而治之(Divide & Conquer)是基本的思路。然后需要考虑单一职责(Single Responsibility)原则,即一个服务应当承担尽可能单一的职责,服务应基于有界的上下文(Bounded Context),通常是边界清晰的业务领域构建;服务理想应当只有一个变更的理由,当一个服务承担过多职责,就会产生各种耦合性问题,需要进一步拆分使其尽可能职责单一化。其次我们需要遵循关注分离(Separation of Concerns),将日志分析、监控、限流、安全等横向功能与具体的业务逻辑相互分离,让开发人员能专注于业务逻辑的开发。
当我们开始构建微服务系统时,首先要考虑的就是服务之间如何通信交互。基于微服务架构构建的应用程序或 API 不仅要把自己完全暴露出来,还需要在内部组件(微服务)之间建立连接。由于每个微服务都可以使用不同的编程语言实现,我们需要依赖标准协议(如 HTTP)来建立微服务之间的连接。这个时候我们就回到了 API 上。 最基本的形式是每个微服务都公开一个 API,让其他服务可以向这个 API 发出请求并获取数据。也可以使用其他不同的方法,比如消息队列。微服务 API 是私有 API,仅限用在单个应用程序中。它通常不提供公共 URL,而是使用组织内部专用网络的私有 IP 或主机名,甚至是单个服务器集群内的 IP 或主机名。不过,这些 API 可以遵循类似公共 API 那样的设计范式或协议。而且,尽管它们的消费者数量有限,也应该遵循开发者体验的基本规则。也就是说,它们应该拥有相关的、一致的、可演化的 API 设计和文档,让其他团队(甚至是你自己)知道如何使用这些微服务。
服务网关
网关一词较早出现在网络设备里面,比如两个相互独立的局域网段之间通过路由器或者桥接设备进行通信,这中间的路由或者桥接设备我们称之为网关。
相应的 API 网关将各系统对外暴露的服务聚合起来,所有要调用这些服务的系统都需要通过 API 网关进行访问,基于这种方式网关可以对 API 进行统一管控,例如:认证、鉴权、流量控制、协议转换、监控等等。API 网关的流行得益于近几年微服务架构的兴起,原本一个庞大的业务系统被拆分成许多粒度更小的系统进行独立部署和维护,这种模式势必会带来更多的跨系统交互,企业 API 的规模也会成倍增加,API 网关(或者微服务网关)就逐渐成为了微服务架构的标配组件。
Kong, Traefik, Caddy, Linkerd, Fabio, Vulcand, and Netflix Zuul seem to be the most common in microservice proxy/gateway solutions. Kubernetes Ingress is often a simple Ngnix, which is difficult to separate the popularity from other things.
A Service Mesh is related, but distinct from the concept of API gateways, edge proxies, and the enterprise service bus. The service mesh is a networking model that sits at a layer of abstraction above TCP/IP. A Service Mesh provides three benefits:
security (TLS for service to service authentication) intelligent traffic management (proxy, deployed as a sidecar to the relevant service) visibility (monitoring and tracing for troubleshooting and debugging) Lyft’s Istio or Bouyant’s Linkerd or Conduit are examples of a Service Mesh, while Traefik, Envoy, Kong, Zuul, etc. are API Gateway implemented using Reverse Proxy. Before Linkerd/Istio/Conduit, large companies implemented the same functionality using fat client libraries.
In these systems, a generalized communication layer became suddenly relevant, but typically took the form of a “fat client” library—Twitter’s Finagle, Netflix’s Hysterix, and Google’s Stubby being cases in point.
1、面向 Web 或者移动 App
这类场景,在物理形态上类似前后端分离,前端应用通过 API 调用后端服务,需要网关具有认证、鉴权、缓存、服务编排、监控告警等功能。
2、面向合作伙伴开放 API
这类场景,主要为了满足业务形态对外开放,与企业外部合作伙伴建立生态圈,此时的 API 网关注重安全认证、权限分级、流量管控、缓存等功能的建设。
3、企业内部系统互联互通
对于中大型的企业内部往往有几十、甚至上百个系统,尤其是微服务架构的兴起系统数量更是急剧增加。系统之间相互依赖,逐渐形成网状调用关系不便于管理和维护,需要 API 网关进行统一的认证、鉴权、流量管控、超时熔断、监控告警管理,从而提高系统的稳定性、降低重复建设、运维管理等成本。
服务发现是大部分分布式系统和面向服务架构的核心组件。最初问题看起来很简单:客户如何决定服务的 IP 地址和端口,这些服务已存在于多个服务器上的。
通常,你开始一些静态的配置,这些配置离你需要做的还挺远的。当你开始布署越来越多的服务时,事情会越来越复杂。在一个上线的系统中,由于自动的或人为的规模变化,服务的位置会经常的变化,例如布署新的服务,服务器宕机或者被替换。
在这些应用场景中为了避免服务冲突,动态的服务注册和发现会越来越重要。
定位服务的问题划分为两类。服务注册与服务发现。
- 服务注册 - 服务进程在注册中心注册自己的位置。它通常注册自己的主机和端口号,有时还有身份验证信息,协议,版本号,以及运行环境的详细资料。
- 服务发现 - 客户端应用进程向注册中心发起查询,来获取服务的位置。
任何服务注册、服务发现也有其它开发、操作层面的考虑:
-
监控 - 如果服务注册失败会发生什么?有时会因为超时、或者其它进程而突然处于未注册状态。通常会要求服务实现心跳机制来确保其活跃性,并且通常要求客户端有能力可靠地处理失效的服务。
-
负载均衡 -如果多个服务被注册,怎样来处理所有的客户端跨服务的均衡问题?如果有个主服务,它能被客户端正确的判断吗?
-
集成风格 - 注册中心仅仅提供了少量语言的绑定,例如仅仅支持 Java 吗?集成需要嵌入注册与发现的代码到程应用程序中,还是可以选择一个辅助进程?
-
运行时依赖 - 它需要 JVM,Ruby 或者其它与你的运行环境不兼容的软件吗?
-
可用性考虑 - 丢失一个节点能继续工作吗?升级时不会中断服务吗?注册处会成为架构的中心部分,会变成单点故障吗?
请求路由,客户端直接调用 Gateway,Gateway 负责路由转发到注册服务上 服务注册,后端服务将 API 注册,Gateway 负责路由 负载均衡,支持多种负载策略 round robin 随机均衡算法 多权重负载 session 粘连 其它 安全特性,支持 HTTPS,账户鉴权,及其它安全特性支持 灰度发布,可以针对服务版本或者租户等特性做灰度发布 API 聚合,将多个后端接口聚合,减少客户端调用次数 API 编排,通过编排来串接多个 API 完成特定业务
设计要点 可用性,必须保证高可用 扩展性,可以灵活扩展以支持特定业务比如特定业务流控 高性能,通常使用异步 IO 模型框架实现,比如 Java netty,Go Channel 安全,如加密通信,鉴权,DDOS 防御等 运维 应用监控,包括容量,性能,异常检测等 弹性伸缩,具备高弹性能力,以低成本应对高峰值 架构 与业务解耦合,提供扩展扩展机制比如 Plugin,Serverless 的思路支持后端业务 服务隔离,可以按照后端服务划分网关,做到不同服务使用不同网关 网关部署靠近后端,保证网络损耗最小,性能最佳
服务注册与服务发现
服务协调
配置中心
服务编排
Service Mesh
sidecar 把所有流量都劫持了,在网络层面做治理。在 service mesh 里面,分成数据面和控制面,数据面就是 sidecar,把所有网络流量都拿在手里。控制面就包括服务发现,sidecar 的配置管理。
价值 分离控制与逻辑,分离业务逻辑与路由,流控,熔断,幂等,服务发现,鉴权等控制组件 适用场景 老系统改造扩展,Sidebar 进程与服务进程部署在同一个节点,通过网络协议通讯 多语言混合分布式系统扩展 应用程序由多方提供 设计要点 标准服务协议,Sidebar 到 Service,Sidebar 到 Sidebar 协议尽可能与语言解耦 聚合控制逻辑比如流控,熔断,幂等,重试,减少业务逻辑 不要使用对服务侵入的方式进行进程间通讯如信号量,共享内存,优先使用本地网络通讯的方式比如 TPCP 或者 HTTP
部署
在项目迭代的过程中,不可避免需要”上线“。上线对应着部署,或者重新部署;部署对应着修改;修改则意味着风险。
Blue/Green Deployment | 蓝绿部署
蓝绿部署是不停老版本,部署新版本然后进行测试,确认 OK,将流量切到新版本,然后老版本同时也升级到新版本。