Cache-CheatSheet
Web 架构缓存概览:从 CPU 到浏览器
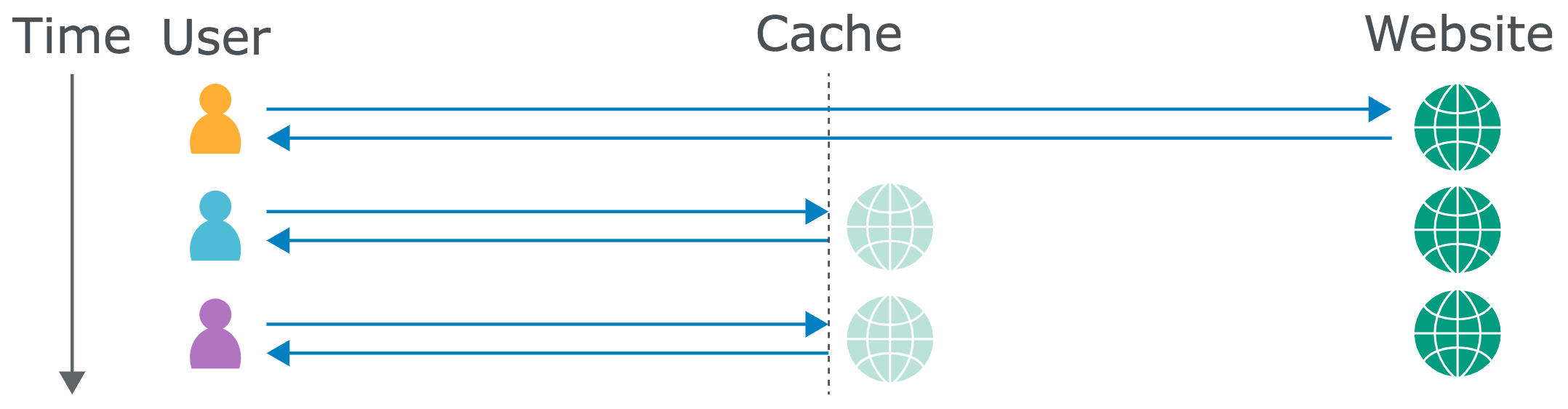
Web caches sit between the user and the application server, where they save and serve copies of certain responses. In the diagram below, we can see three users fetching the same resource one after the other:
Caching is intended to speed up page loads by reducing latency, and also reduce load on the application server. Some companies host their own cache using software like Varnish, and others opt to rely on a Content Delivery Network (CDN) like Cloudflare, with caches scattered across geographical locations. Also, some popular web applications and frameworks like Drupal have a built-in cache.
There are also other types of cache, such as client-side browser caches and DNS caches, but they’re not the focus of this research.
CPU Cache
由于内存的访问速度与 CPU 中寄存器的访问速度相去甚远,当我们需要对同一批数据(譬如数组或循环计数变量)进行多次操作时,CPU 会自动将值放到 CPU 缓存而不是内存中。CPU 缓存的访问速度仅次于 CPU 寄存器。其容量远小于内存,但速度却可以接近处理器的频率。当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
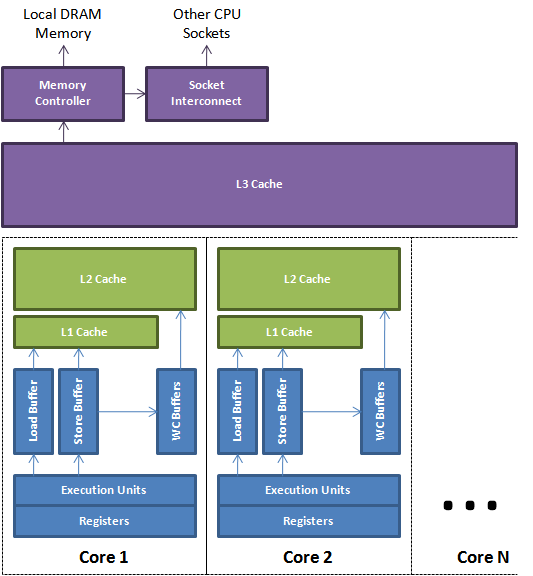
随着多核的发展,CPU 缓存又被细分为了 L1, L2, L3 这三个级别,级别越小越接近于 CPU,并且容量越小;一般来说,每个核上都会包含用于存放数据的 L1d Cache 与存放指令的 L1i Cache,以及独立的 L2 Cache,而往往同一个 CPU 插槽之间的核会共享 L3 Cache。在 Linux 设备上 cat /proc/cpuinfo 或者 lscpu 查看 CPU 情况。
| 存储单元 | 体积 | 访问所需 CPU 周期 | 访问所需时间 |
|---|---|---|---|
| 寄存器 | 1 cycle | ||
| L1 Cache | 2KB~64KB | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | 256KB~512KB | ~10-20 cycles | ~3-7 ns |
| L3 Cache | 1MB~8MB | ~40-45 cycles | ~15 ns |
| 跨槽传输 | ~20 ns | ||
| 内存 | ~120-240 cycles | ~60-120ns |
结构上,一个直接映射(Direct Mapped)缓存由若干缓存块(Cache Block,或 Cache Line)构成。每个缓存块存储具有连续内存地址的若干个存储单元。在 32 位计算机上这通常是一个双字(dword),即四个字节。因此,每个双字具有唯一的块内偏移量。每个缓存块有一个索引(Index),它一般是内存地址的低端部分,但不含块内偏移和字节偏移所占的最低若干位。一个数据总量为 4KB、缓存块大小为 16B 的直接映射缓存一共有 256 个缓存块,其索引范围为 0 到 255。在 Linux 设备上我们可以查看机器缓存行的大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64
缓存策略
CDN
CDN 的全称是 Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN 系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决 Internet 网络拥挤的状况,提高用户访问网站的响应速度。
客户端浏览器先检查是否有本地缓存是否过期,如果过期,则向 CDN 边缘节点发起请求,CDN 边缘节点会检测用户请求数据的缓存是否过期,如果没有过期,则直接响应用户请求,此时一个完成 http 请求结束;如果数据已经过期,那么 CDN 还需要向源站发出回源请求(back to the source request),来拉取最新的数据。
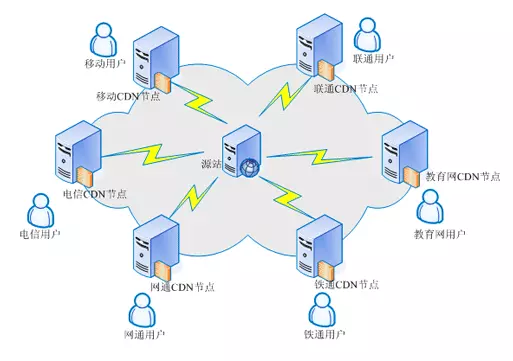
CDN 系统中,直接面向用户,负责给用户提供内容服务的的 Cache 设备都部署在整个 CDN 网络的边缘位置,所以将这一层称为边缘层。CDN 系统中,中心层负责全局的管理和控制,同时也保存了最多的内容 Cache。在边缘层设备未能命中 Cache 时,需要向中心层设备请求;而中心层未能命中时,则需要向源站请求。不同的 CDN 系统设计存在差异,中心层可能具备用户服务的能力,也可能只会向下一层提供服务。如果 CDN 系统比较庞大,边缘层向中心层请求内容太多,会造成中心层负载压力太大。此时,需要在中心层和边缘层之间部署一个区域层,负责一个区域的管理和控制,也可以提供一些内容 Cache 供边缘层访问。
常规的 CDN 都是回源的。即:当有用户访问某一个 URL 的时候,如果被解析到的那个 CDN 节点没有缓存响应的内容,或者是缓存已经到期,就会回源站去获取。如果没有人访问,那么 CDN 节点不会主动去源站拿的;源站内容有更新的时候,源站主动把内容推送到 CDN 节点。回源域名一般是 cdn 领域的专业术语,通常情况下,是直接用 ip 进行回源的,但是如果客户源站有多个 ip,并且 ip 地址会经常变化,对于 cdn 厂商来说,为了避免经常更改配置(回源 ip),会采用回源域名方式进行回源,这样即使源站的 ip 变化了,也不影响原有的配置。CDN 本来是给我们的网站加速的,但是有时会因为不合适的回源策略给服务器带来负担,只有选择正确的策略才能给自己的网站带来更高的访问效率。
微服务缓存
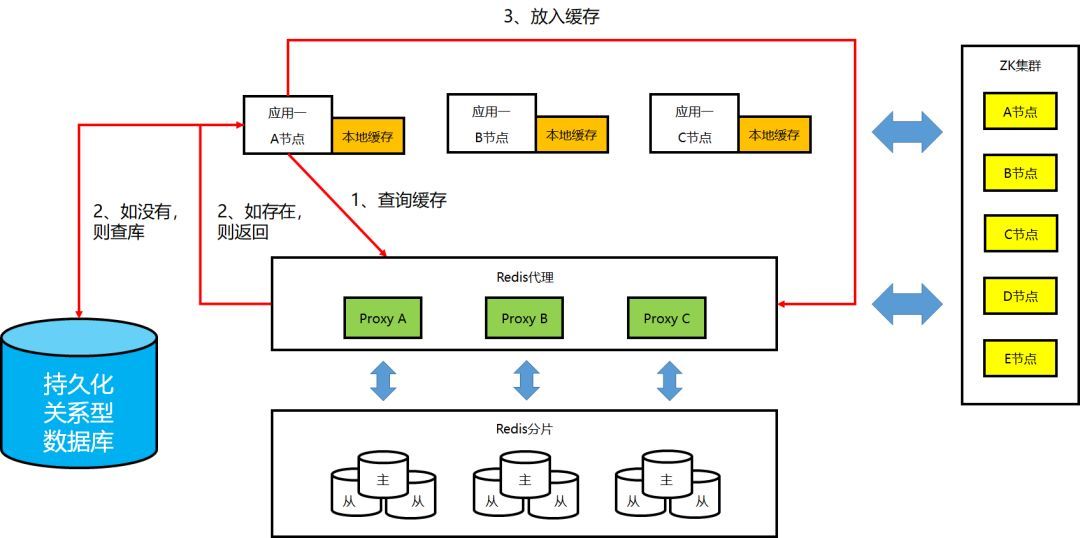
① 非本地缓存的工作机制
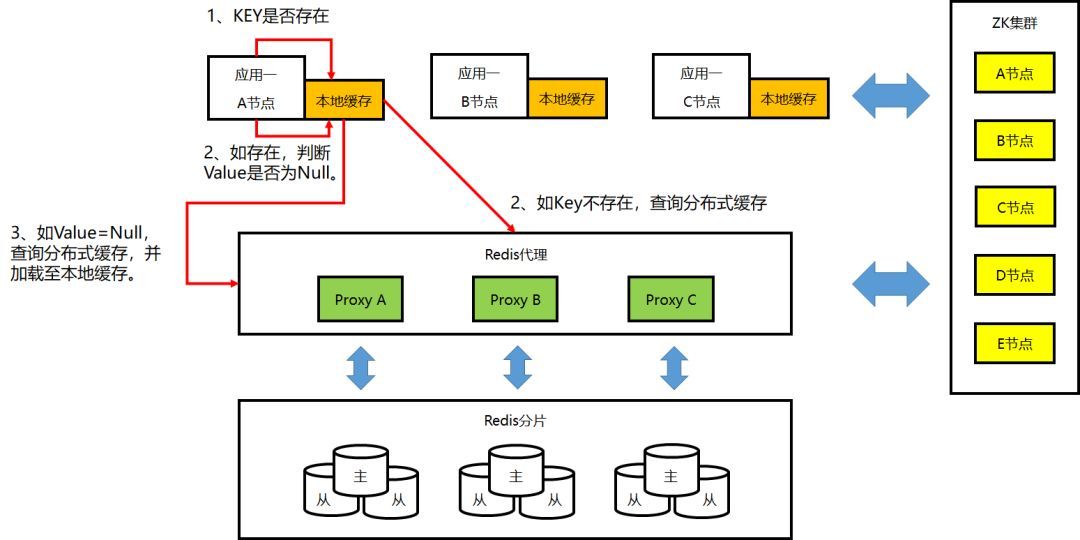
② 本地缓存的工作机制:Key 预加载/更新
③ 本地缓存的工作机制:Set/Delete 操作
④ 本地缓存的工作机制:Get 操作