
Node-CheatSheet

本文节选自 Node.js CheatSheet | Node.js 语法基础、框架使用与实践技巧,也可以阅读 JavaScript CheatSheet 或者 现代 Web 全栈开发与工程架构 了解更多 JavaScript/Node.js 的实际应用。
Node.js CheatSheet | Node.js 语法基础、框架使用与实践技巧
Node.js 的包管理,或者说依赖管理使用了语义化版本的规范,版本的发布分为四个不同的层次:使用 1.0.0 表示新发布,使用 1.0.1 这样第三位数字表示错误修复等小版本更新;使用 1.1.0 这样的第二位数字表示新特性等兼容性更新;使用 2.0.0 这样第一位数字表示大版本的更新。相对应地,在 package.json 声明依赖版本时,我们也可以指定不同的兼容范围:
-
Patch releases:1.0 或者 1.0.x 或者 ~1.0.4
-
Minor releases: 1 或者 1.x 或者 ^1.0.4
-
Major releases: * 或者 x

基础语法
开发实践
调试
在 VSCode 中,我们也能够方便地进行断点调试,首先我们需要在 package.json 中添加 debug 指令:
"scripts": {
"debug": "node --nolazy --inspect-brk=9229 myProgram.js"
},
然后在 ./vscode/launch.json 中添加启动配置项:
{
"name": "Launch via NPM",
"type": "node",
"request": "launch",
"cwd": "${workspaceFolder}",
"runtimeExecutable": "npm",
"runtimeArgs": ["run-script", "debug"],
"port": 9229
}
如果我们希望包含较多的环境变量,还可以指定环境变量:
//...
"envFile": "${workspaceFolder}/.env",
"env": { "USER": "john doe" }
//...
或者指定加载外部的环境变量文件:
USER=doe
PASSWORD=abc123
IO
异步循环
Node 的异步语法比浏览器更复杂,因为它可以跟内核对话,不得不搞了一个专门的库 libuv 做这件事。这个库负责各种回调函数的执行时间,毕竟异步任务最后还是要回到主线程,一个个排队执行。

事件循环会无限次地执行,一轮又一轮。只有异步任务的回调函数队列清空了,才会停止执行。
每一轮的事件循环,分成六个阶段。这些阶段会依次执行。
timers IO callbacks idle, prepare poll check close callbacks
每个阶段都有一个先进先出的回调函数队列。只有一个阶段的回调函数队列清空了,该执行的回调函数都执行了,事件循环才会进入下一个阶段。

下面简单介绍一下每个阶段的含义,详细介绍可以看官方文档,也可以参考 libuv 的源码解读。
(1)timers
这个是定时器阶段,处理 setTimeout()和 setInterval()的回调函数。进入这个阶段后,主线程会检查一下当前时间,是否满足定时器的条件。如果满足就执行回调函数,否则就离开这个阶段。
(2)IO callbacks
除了以下操作的回调函数,其他的回调函数都在这个阶段执行。
setTimeout()和 setInterval()的回调函数 setImmediate()的回调函数 用于关闭请求的回调函数,比如 socket.on(‘close’, …)
(3)idle, prepare
该阶段只供 libuv 内部调用,这里可以忽略。
(4)Poll
这个阶段是轮询时间,用于等待还未返回的 IO 事件,比如服务器的回应、用户移动鼠标等等。
这个阶段的时间会比较长。如果没有其他异步任务要处理(比如到期的定时器),会一直停留在这个阶段,等待 IO 请求返回结果。
(5)check
该阶段执行 setImmediate()的回调函数。
(6)close callbacks
该阶段执行关闭请求的回调函数,比如 socket.on(‘close’, …)。
const fs = require("fs");
const timeoutScheduled = Date.now();
// 异步任务一:100ms 后执行的定时器
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms`);
}, 100);
// 异步任务二:至少需要 200ms 的文件读取
fs.readFile("test.js", () => {
const startCallback = Date.now();
while (Date.now() - startCallback < 200) {
// 什么也不做
}
});
上面代码有两个异步任务,一个是 100ms 后执行的定时器,一个是至少需要 200ms 的文件读取。请问运行结果是什么?
脚本进入第一轮事件循环以后,没有到期的定时器,也没有已经可以执行的 IO 回调函数,所以会进入 Poll 阶段,等待内核返回文件读取的结果。由于读取小文件一般不会超过 100ms,所以在定时器到期之前,Poll 阶段就会得到结果,因此就会继续往下执行。
第二轮事件循环,依然没有到期的定时器,但是已经有了可以执行的 IO 回调函数,所以会进入 IO callbacks 阶段,执行 fs.readFile 的回调函数。这个回调函数需要 200ms,也就是说,在它执行到一半的时候,100ms 的定时器就会到期。但是,必须等到这个回调函数执行完,才会离开这个阶段。
第三轮事件循环,已经有了到期的定时器,所以会在 timers 阶段执行定时器。最后输出结果大概是 200 多毫秒。
八、setTimeout 和 setImmediate
由于 setTimeout 在 timers 阶段执行,而 setImmediate 在 check 阶段执行。所以,setTimeout 会早于 setImmediate 完成。
setTimeout(() => console.log(1)); setImmediate(() => console.log(2));
上面代码应该先输出 1,再输出 2,但是实际执行的时候,结果却是不确定,有时还会先输出 2,再输出 1。
这是因为 setTimeout 的第二个参数默认为 0。但是实际上,Node 做不到 0 毫秒,最少也需要 1 毫秒,根据官方文档,第二个参数的取值范围在 1 毫秒到 2147483647 毫秒之间。也就是说,setTimeout(f, 0)等同于 setTimeout(f, 1)。
实际执行的时候,进入事件循环以后,有可能到了 1 毫秒,也可能还没到 1 毫秒,取决于系统当时的状况。如果没到 1 毫秒,那么 timers 阶段就会跳过,进入 check 阶段,先执行 setImmediate 的回调函数。
但是,下面的代码一定是先输出 2,再输出 1。
const fs = require("fs");
fs.readFile("test.js", () => {
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
});
上面代码会先进入 IO callbacks 阶段,然后是 check 阶段,最后才是 timers 阶段。因此,setImmediate 才会早于 setTimeout 执行。
Stream
Stream 是 Node.js 中的基础概念,类似于 EventEmitter,专注于 IO 管道中事件驱动的数据处理方式;类比于数组或者映射,Stream 也是数据的集合,只不过其代表了不一定正在内存中的数据。。Node.js 的 Stream 分为以下类型:
- Readable Stream: 可读流,数据的产生者,譬如 process.stdin
- Writable Stream: 可写流,数据的消费者,譬如 process.stdout 或者 process.stderr
- Duplex Stream: 双向流,即可读也可写
- Transform Stream: 转化流,数据的转化者
Stream 本身提供了一套接口规范,很多 Node.js 中的内建模块都遵循了该规范,譬如著名的 fs 模块,即是使用 Stream 接口来进行文件读写;同样的,每个 HTTP 请求是可读流,而 HTTP 响应则是可写流。
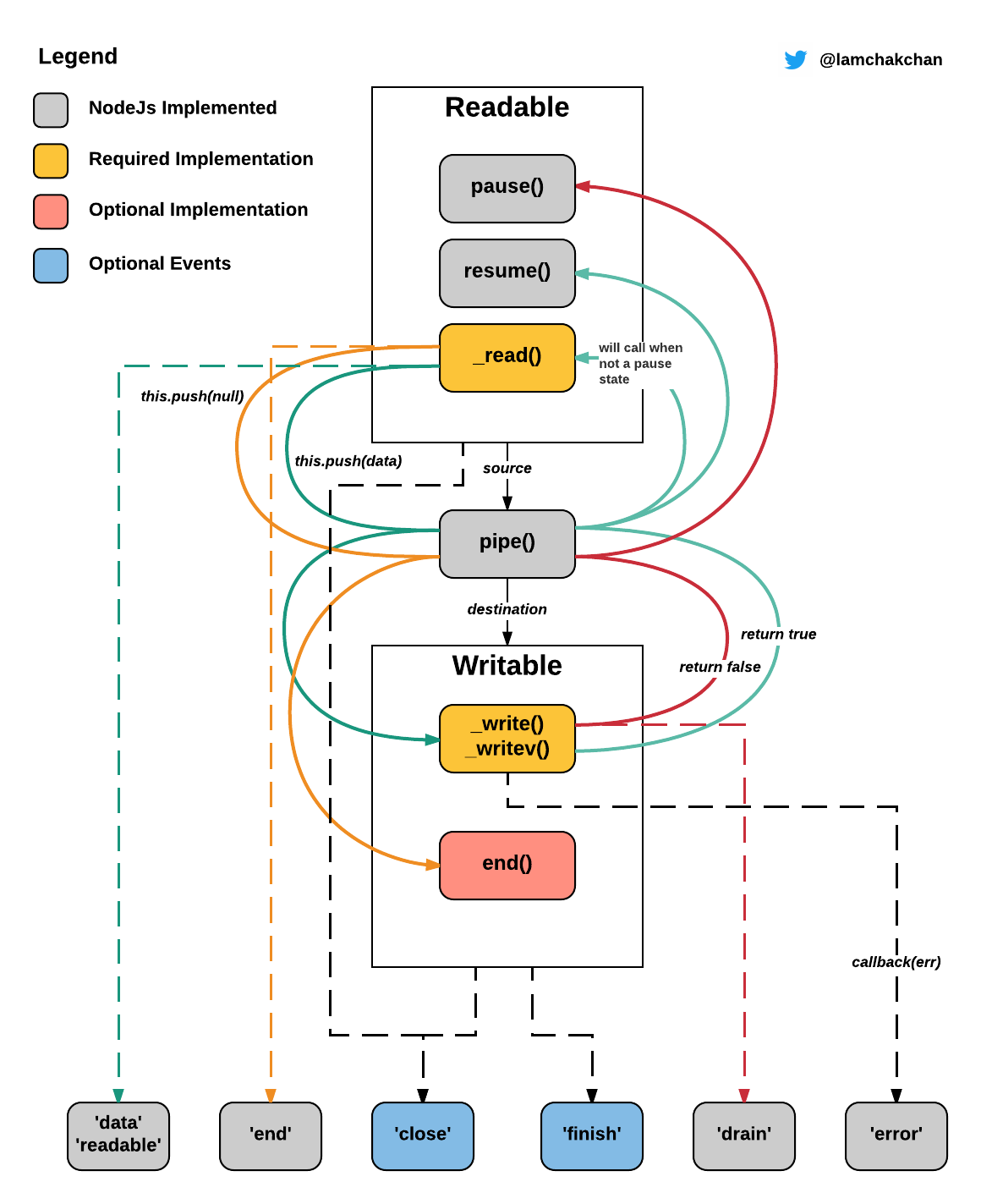
文件读写
__dirname 指向当前文件所在目录。我们可以使用 join 与 resolve 两个辅助函数来进行路径构造,区别在于 join 只是进行简单连接,而 resolve 会进行根路径重置:
path.join('/a', '/b'); // Outputs '/a/b'
path.resolve('/a', '/b'); // Outputs '/b'
// 获取文件状态
fs.statSync(path[, options])
stats.isBlockDevice()
stats.isDirectory()
stats.isFIFO()
stats.isFile()
stats.isSocket()
// 同步读取
const contents = fs.readFileSync("DATA", "utf8");
// 异步读取
const { promisify } = require("util");
const fs = require("fs");
const readFileAsync = promisify(fs.readFile); // (A)
const filePath = process.argv[2];
readFileAsync(filePath, { encoding: "utf8" })
.then((text) => {
console.log("CONTENT:", text);
})
.catch((err) => {
console.log("ERROR:", err);
});
// fs-extra
HTTP Server
WebSocket
Production | 部署
我们也可以将 Node.js 应用部署为 Systemd 服务,首先创建 /etc/systemd/system/node-sample.service 文件:
[Unit]
Description=node-sample - making your environment variables rad
Documentation=https://example.com
After=network.target
[Service]
ExecStart=[node binary] /home/srv-node-sample/[main file]
Restart=always
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=node-sample
User=srv-node-sample
Group=srv-node-sample
Environment=NODE_ENV=production
[Install]
WantedBy=multi-user.target
然后使用 systemctl 命令启动与控制服务:
$ systemctl enable node-sample
$ systemctl start node-sample
# 查看应用状态
$ systemctl status node-sample
# 查看日志
$ journalctl -u node-sample
Cluster | 集群模式
const cluster = require("cluster");
const http = require("http");
const numCPUs = require("os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http
.createServer((req, res) => {
res.writeHead(200);
res.end("hello world\n");
})
.listen(8000);
console.log(`Worker ${process.pid} started`);
}
系统功能
数据存储
Knex
当我们使用 leftJoin 查询单条数据时,可以通过 nestTables 选项将扁平结构转化为嵌套结构:
knex
.from('users')
.leftJoin('user_address', 'users.id', '=', 'user_address.user_id')
.options({ nestTables: true })
.then(results => {
// do something with results ...
});
// result 结果如下
{
users: {
id: 3,
username: 'somename',
email:
},
user_address: {
id: 1, // or whatever format your id is in
user_id: 3,
street: 'somestreet',
postcode: 'somepostcode'
}
}
当我们使用 innerJoin 查询多个关联项时,可以使用 knexnest:
const knexnest = require("knexnest");
const sql = knex
.select(
"c.id AS _id",
"c.title AS _title",
"t.id AS _teacher_id",
"t.name AS _teacher_name",
"l.id AS _lesson__id",
"l.title AS _lesson__title"
)
.from("course AS c")
.innerJoin("teacher AS t", "t.id", "c.teacher_id")
.innerJoin("course_lesson AS cl", "cl.course_id", "c.id")
.innerJoin("lesson AS l", "l.id", "cl.lesson_id");
knexnest(sql).then(function (data) {
result = data;
});
/* result should be like:
[
{id: '1', title: 'Tabular to Objects', teacher: {id: '1', name: 'David'}, lesson: [
{id: '1', title: 'Defintions'},
{id: '2', title: 'Table Data'},
{id: '3', title: 'Objects'}
]},
]
*/
Kenx 同样支持子查询,我们可以将某个查询语句当做源表或者计算列处理:
// 源表
const subQuery = this.app.knex
.select("asset_id as asset_id_1")
.count("_id as component_num")
.from("asset_component")
.groupBy("asset_id")
.as("ac");
const assets = await this.app
.knex("asset")
.select("*")
.leftJoin(subQuery, "asset.asset_id", "ac.asset_id_1")
.orderBy("updated_at", "desc");
// 计算列
const components = await knexCamel("component").select(
"*",
knexCamel.raw(
"(SELECT count(*) from vuln where vuln.c_id = component.c_id) as vuln_count"
)
);
在我们进行插入操作时,常常需要在存在时更新;在 MySQL 数据库中,我们可以自行封装如下函数:
function upsert(table, data, updateData?) {
if (!updateData) {
updateData = data;
}
const insert = this.knex(table).insert(data).toString();
const updateSql = this.knex(table)
.update(updateData)
.toString()
.replace(/^update .* set /i, "");
return this.knex.raw(insert + " on duplicate key update " + updateSql);
}
Bookshelf 则是基于 Knex 的 ORM 框架,其能够自动地从数据库中抓取表结构信息,并且支持事务、多态以及 One-to-One, One-to-Many, Many-to-Mant 等多种关系映射。
const knex = require("knex")({
client: "mysql",
connection: process.env.MYSQL_DATABASE_CONNECTION,
});
const bookshelf = require("bookshelf")(knex);
const User = bookshelf.Model.extend({
tableName: "users",
posts: function () {
return this.hasMany(Posts);
},
});
const Posts = bookshelf.Model.extend({
tableName: "messages",
tags: function () {
return this.belongsToMany(Tag);
},
});
const Tag = bookshelf.Model.extend({
tableName: "tags",
});
User.where("id", 1)
.fetch({ withRelated: ["posts.tags"] })
.then(function (user) {
console.log(user.related("posts").toJSON());
})
.catch(function (err) {
console.error(err);
});
日志
const env = process.env.NODE_ENV || "development";
const logDir = "log";
// Create the log directory if it does not exist
if (!fs.existsSync(logDir)) {
fs.mkdirSync(logDir);
}
const filename = path.join(logDir, "results.log");
const logger = createLogger({
// change level if in dev environment versus production
level: env === "production" ? "info" : "debug",
format: format.combine(
format.label({ label: path.basename(module.parent.filename) }),
format.timestamp({ format: "YYYY-MM-DD HH:mm:ss" })
),
transports: [
new transports.Console({
format: format.combine(
format.colorize(),
format.printf(
(info) =>
`${info.timestamp} ${info.level} [${info.label}]: ${info.message}`
)
),
}),
new transports.File({
filename,
format: format.combine(
format.printf(
(info) =>
`${info.timestamp} ${info.level} [${info.label}]: ${info.message}`
)
),
}),
],
});
DevOps
Deploy
Pandora.js 阿里巴巴产出的一个 Node.js 应用监控管理器,可以让您对自己的 Node.js 应用了若指掌,我们的目标就是让应用可管理、可度量、可追踪。
$ npm i pandora pandora-dashboard -g
# 输出 Pandora.js dashboard 的目录,然后 Pandora.js 会把它当成一个普通的项目来启动
$ pandora start --name dashboard `pandora-dashboard-dir`
# 主入口为 server.js,在项目根目录运行下面的命令来初始化
$ pandora init server.js
? Which type do you like to generate ? (Use arrow keys)
fork # Fork 简单拉起 server.js
❯ cluster # Cluster 则用 Node.js 的 Cluster 模块启动 server.js(即 Master / Worker 模型)
$ pandora start
Starting rest-crud at /xx/xxx/rest-crud
rest-crud started successfully! Run command [ pandora log rest-crud ] to get more information
如果需要在 Egg.js 中使用,则添加自定义的 server.js 入口文件:
const egg = require('egg');
const workers = Number(process.argv[2] || require('os').cpus().length);
egg.startCluster({
workers,
baseDir: __dirname,
});
Web 框架
基础框架除了应用最广泛的主流 Web 框架 Koa 外,Fastify 也是一直劲敌,作者 Matteo Collina 是 Node.js 核心开发,Stream 掌门,性能优化专家。Fastify 基于 Schema 优化,对性能提升极其明显。当然,最值得说明的,我认为是企业级 Web 开发,这里简单介绍 3 个知名框架。
b1)Egg.js
阿里开源的企业级 Node.js 框架 Egg 发布 2.0,基于 Koa 2.x,异步解决方案直接基于 Async Function。框架层优化不含 Node 8 带来的提升外,带来 30% 左右的性能提升。
Egg 采用的是微内核 + 插件 + 上层框架 模式,对于定制,生态,快速开发有明显提升,另外值得关注的是稳定性和安全上,也是极为出色的。
b2)Nest
Nest 是基于 TypeScript 和 Express 的企业级 Web 框架。
很多人开玩笑说,Nest 是最像 Java 开发方式的,确实,Nest 采用 TypeScript 作为底层语言,TypeScript 是 ES6 超集,对类型支持,面向对象,Decorator(类似于 Java 里注解 Annotation)等支持。在写法上,保持 Java 开发者的习惯,能够吸引更多人快速上手。
TypeScript 支持几乎是目前所有 Node Web 框架都要做的头等大事,在 2017 年 Nest 算首个知名项目,值得一提。
b3)ThinkJS
ThinkJS 是一款拥抱未来的 Node.js Web 框架,致力于集成项目最佳实践,规范项目让企业级团队开发变得更加简单,更加高效。秉承简洁易用的设计原则,在保持出色的性能和至简的代码同时,注重开发体验和易用性,为 WEB 应用开发提供强有力的支持。
ThinkJS 是国产老牌 Web 框架,在 2017 年 10 月发布 v3 版本,基于 Koa 内核,在性能和开发体验上有更好的提升。
整体来看,Node.js 在企业 Web 开发领域日渐成熟,无论微服务,还是 Api 中间层都得到了非常好的落地。在 2017 年唯一遗憾的是 Node.js 在 servless 上表现的不太好,相关框架实践偏少。
c)不可不见的 Api 中间层
前端越来越复杂,后端服务化,今日的前端要面临更多的挑战。一个典型的场景就是在服务化架构里,前端面临的最头痛的问题是异构 API,前后端联调的时候,多个后端互相推诿,要么拖慢上线进度,要么让前端性能变得极其慢。进度慢找前端,性能差也找前端,但这个锅真的该前端来背么?
Node.js 的 Api 中间层应用很好的解决了这个问题。后端不想改的时候,实在不行就前端自己做,更灵活,更能应变。
透传接口,对于内网或者非安全接口,可以采用中间层透传。 聚合接口,对异构 API 处理非常方便,如果能够梳理 model,应变更容易。 Mock 接口,通过 Mock 接口,提供前端开发效率,对流程优化效果极其明显,比如去哪儿开发的 yapi 就是专门解决这个问题的。 除此之外,前端如果想做一些技术驱动的事儿,SSR(服务器端渲染)和 PWA(渐进式 Web 应用)也是非常不错的选择。
if _, err := net.ListenUDP(“udp”, addr); err != nil { log.Fatal(“error making udp socket”, err) }
Express
Koa
Koa 中最著名即其洋葱圈模型,其任何的处理流都是以中间件方式进行:

基础的 Koa 用法如下:
const Koa = require('koa');
const app = new Koa();
const PORT = 3000;
app.use(async (ctx, next)=>{
console.log(1)
ctx.body = ...
await next();
console.log(1)
});
...
Koa 洋葱模型的两个核心设计点即是 context 的保存和传递以及中间件的管理和 next 的实现,从 Koa 入口 Server 开始:
listen(...args) {
debug('listen');
const server = http.createServer(this.callback());
return server.listen(...args);
}
在 callback 函数中,会执行中间件的聚合与使用:
callback() {
const fn = compose(this.middleware);
...
const handleRequest = (req, res) => {
const ctx = this.createContext(req, res);
return this.handleRequest(ctx, fn);
};
return handleRequest;
}
compose 函数在 koa-compose 中定义,其会包含某个 dispatch 函数,该函数等于会递归执行数组后的中间件函数:
function compose (middleware) {
...
return function (context, next) {
// last called middleware #
let index = -1
return dispatch(0)
function dispatch (i) {
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
let fn = middleware[i]
// 如果中间件执行完毕,则调用传入的函数
if (i === middleware.length) fn = next
if (!fn) return Promise.resolve()
try {
// 递归执行下一个函数,传入的 next 函数即是包装的 dispatch 的下一个函数的调用
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}
而 handleRequest 函数中只是会简单地初始化调用中间件聚合函数:
handleRequest(ctx, fnMiddleware) {
...
return fnMiddleware(ctx).then(handleResponse).catch(onerror);
}