
B+Tree
B+ 树
刚才讨论的日志结构索引正处在逐渐被接受的阶段,但它们并不是最常见的索引类型。使用最广泛的索引结构在 1970 年被引入,不到 10 年后变得“无处不在”,B 树经受了时间的考验。在几乎所有的关系数据库中,它们仍然是标准的索引实现,许多非关系数据库也使用它们。
像 SSTables 一样,B 树保持按键排序的键值对,这允许高效的键值查找和范围查询。但这就是相似之处的结尾:B 树有着非常不同的设计理念。我们前面看到的日志结构索引将数据库分解为可变大小的段,通常是几兆字节或更大的大小,并且总是按顺序编写段。相比之下,B 树将数据库分解成固定大小的块或页面,传统上大小为 4KB(有时会更大),并且一次只能读取或写入一个页面。这种设计更接近于底层硬件,因为磁盘也被安排在固定大小的块中。
每个页面都可以使用地址或位置来标识,这允许一个页面引用另一个页面:类似于指针,但在磁盘而不是在内存中。我们可以使用这些页面引用来构建一个页面树:
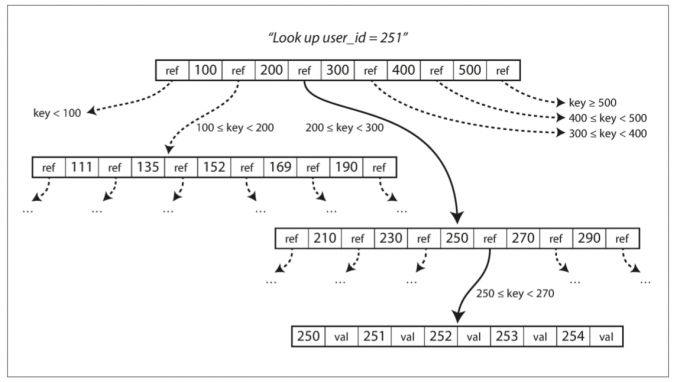
一个页面会被指定为 B 树的根;在索引中查找一个键时,就从这里开始。该页面包含几个键和对子页面的引用。每个子页面负责一段连续范围的键,引用之间的键,指明了引用子页面的键范围。譬如在上例中,我们正在寻找关键字 251,所以我们知道我们需要遵循边界 200 和 300 之间的页面引用。这将我们带到一个类似的页面,进一步打破了 200 - 300 到子范围。最后,我们可以看到包含单个键(叶页)的页面,该页面包含每个键的内联值,或者包含对可以找到值的页面的引用。
B+Tree
B-Tree 有许多变种,其中最常见的是 B+Tree,例如 MySQL 就普遍使用 B+Tree 实现其索引结构。与 B-Tree 相比,B+Tree 有以下不同点:
- 每个节点的指针上限为 2d 而不是 2d+1。
- 内节点不存储 data,只存储 key;叶子节点不存储指针。
下图是一个简单的 B+Tree 示意。
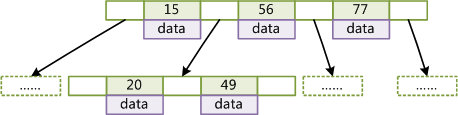
由于并不是所有节点都具有相同的域,因此 B+Tree 中叶节点和内节点一般大小不同。这点与 B-Tree 不同,虽然 B-Tree 中不同节点存放的 key 和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中 B-Tree 往往对每个节点申请同等大小的空间。
一般来说,B+Tree 比 B-Tree 更适合实现外存储索引结构。