
广度优先搜索
广度优先搜索
广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称 BFS。它的思想是:从图中某顶点 v 出发,在访问了 v 之后依次访问 v 的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点“先于”后被访问的顶点的邻接点“被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
换句话说,广度优先搜索遍历图的过程是以 v 为起点,由近至远,依次访问和 v 有路径相通且路径长度为 1,2…的顶点。
无向图的广度优先搜索
下面以"无向图"为例,来对广度优先搜索进行演示。还是以上面的图 G1 为例进行说明。
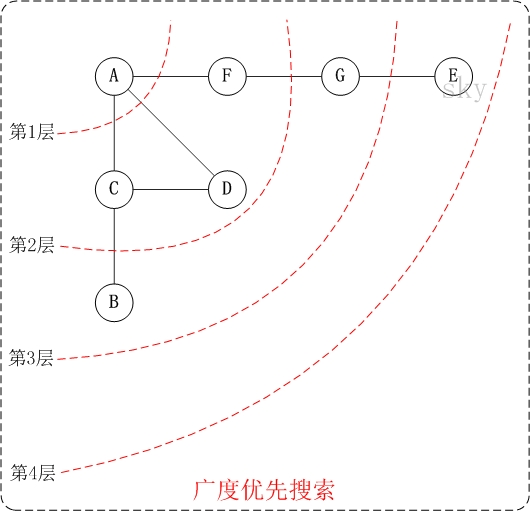
- 第 1 步:访问 A。
- 第 2 步:依次访问 C、D、F。在访问了 A 之后,接下来访问 A 的邻接点。前面已经说过,在本文实现中,顶点 ABCDEFG 按照顺序存储的,C 在"D 和 F"的前面,因此,先访问 C。再访问完 C 之后,再依次访问 D,F。
- 第 3 步:依次访问 B,G。在第 2 步访问完 C,D,F 之后,再依次访问它们的邻接点。首先访问 C 的邻接点 B,再访问 F 的邻接点 G。
- 第 4 步:访问 E。在第 3 步访问完 B,G 之后,再依次访问它们的邻接点。只有 G 有邻接点 E,因此访问 G 的邻接点 E。
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
有向图的广度优先搜索
下面以"有向图"为例,来对广度优先搜索进行演示。还是以上面的图 G2 为例进行说明。
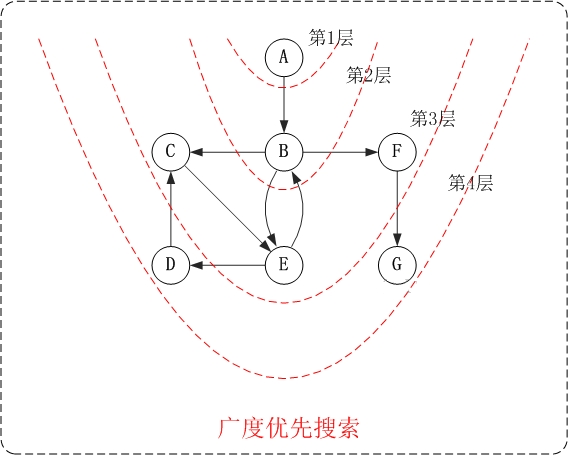
- 第 1 步:访问 A。
- 第 2 步:访问 B。
- 第 3 步:依次访问 C,E,F。在访问了 B 之后,接下来访问 B 的出边的另一个顶点,即 C,E,F。前面已经说过,在本文实现中,顶点 ABCDEFG 按照顺序存储的,因此会先访问 C,再依次访问 E,F。
- 第 4 步:依次访问 D,G。在访问完 C,E,F 之后,再依次访问它们的出边的另一个顶点。还是按照 C,E,F 的顺序访问,C 的已经全部访问过了,那么就只剩下 E,F;先访问 E 的邻接点 D,再访问 F 的邻接点 G。
因此访问顺序是:A -> B -> C -> E -> F -> D -> G
广度优先遍历
图的广度优先遍历基于广度优先搜索 BFS (Breadth First Search),其主要思想是首先以一个未被访问过的顶点作为起始顶点,访问其所有相邻的顶点,然后对每个相邻的顶点,再访问它们相邻的未被访问过的顶点,直到所有的顶点都被访问过,遍历结束。广度优先搜索是从图中某一顶点 v 出发,在访问顶点 v 后再访问 v 的各个未曾被访问过的邻接顶点 w1、w2、…、wk,然后再依次访问 w1、w2、…、wk 的所有还未被访问过的邻接顶点。再从这些访问过的顶点出发,再访问它们的所有还未被访问过的邻接顶点,……,如此下去,直到图中所有和顶点 v 由路径连通的顶点都被访问到为止。
下图(a)给出了一个从顶点 A 出发进行广度优先搜索的示例。图(b)给出了由广度优先搜索得到的广度优先生成树,它由搜索时访问过的 n 个顶点和搜索时经历的 n-1 条边组成,各顶点旁边附的数字标明了顶点被访问的顺序。
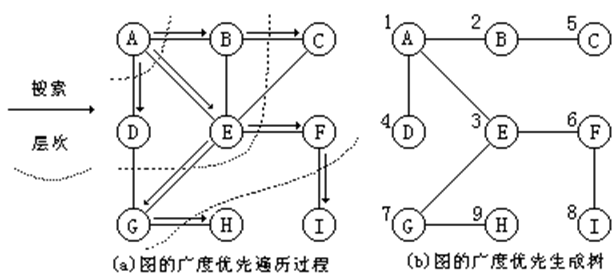
广度优先搜索是一种分层的搜索过程,它类似于树的层次遍历。从图中可以看出,搜索每向前走一步可能访问一批顶点,不像深度优先搜索那样有往回退的情况,因此,广度优先遍历不是一个递归的过程,其算法也不是递归的。为了实现逐层访问,算法中使用了一个队列,以记录刚才访问过的上一层和本层顶点,以便于向下一层访问。从指定的结点 v 开始进行广度优先搜索的算法步骤是:
(1)访问结点 v,并标记 v 已被访问,同时顶点 v 入队列 (2)当队列空时算法结束,否则继续步骤(3) (3)队头顶点出队列为 v (4)取顶点 v 的第一个邻接顶点 w (5)若顶点 w 不存在,转步骤(3);否则继续步骤(6) (6)若顶点 w 未被访问,则访问顶点 w,并标记 w 已被访问,同时顶点 w 入队列;否则继续步骤 (7)使 w 为顶点 v 的在原来 w 之后的下一个邻接顶点,转到步骤(5)
代码实现
// 广度优先遍历的算法
template<class vertexType, class arcType>void Graph <vertexType, arcType> ::
BFTraverse (void visit( vertexType v )) {
int i, n = NumberOfVertexes() ;//取图的顶点个数
int * visited = new int [n]; //定义访问标记数组 visited
for ( i = 0; i < n; i++ )
visited [i] = 0; //访问标记数组 visited 初始化
for ( i = 0; i < n; i++ ) //对图中的每一个顶点进行判断
if (!visited [i]) BFS (i, visited, visit);
delete [ ] visited; //释放 visited
}
// 广度优先搜索的算法
template<class vertexType, class arcType> void Graph <vertexType, arcType> ::
BFS (const int v, int visited [ ], void visit( vertexType v )) {
linkqueue <int> q; //定义队列q
visit( GetValue (v)); //访问顶点 v
visited[v] = 1; //顶点 v 作已访问标记
q.EnQueue (v); //顶点 v 进队列q
while ( !q.IsEmpty ( ) ) {
v = q.DeQueue ( ); //否则, 队头元素出队列
int w = GetFirstNeighbor (v);
while ( w != -1 ) { //若邻接顶点 w 存在
if ( !visited[w] ) { //若该邻接顶点未访问过
visit( GetValue (w)); //访问顶点 w
visited[w] = 1; //顶点 w 作已访问标记
q.EnQueue (w); //顶点 w 进队列q
}
w = GetNextNeighbor (v, w);
} //重复检测 v 的所有邻接顶点
} //外层循环,判队列空否
}
在图的广度优先遍历算法中,图中每一个顶点需进队列一次且仅进队列一次,而在遍历过程中是通过边来搜索邻接点的。所以,图的广度优先遍历算法的时间复杂度和图的深度优先遍历算法的时间复杂度类似,如果使用邻接表表示图,则其时间复杂度为 O(n+e);如果使用邻接矩阵表示图,则其时间复杂度为 $O(n^2)$。